
阿里云开发者社区






大家在互动










综合
最新
有奖励
免费用

FunASR 语音大模型在 Arm Neoverse 平台上的优化实践
Arm 架构的服务器通常具备低功耗的特性,能带来更优异的能效比。相比于传统的 x86 架构服务器,Arm 服务器在相同功耗下能够提供更高的性能。这对于大模型推理任务来说尤为重要,因为大模型通常需要大量
让你的文档从静态展示到一键部署可操作验证
通过函数计算的能力让阿里云的文档从静态展示升级为动态可操作验证,用户在文档中单击一键部署可快速完成代码的部署及测试。这一改变已在函数计算的活动沙龙中得到用户的认可。
一键生成视频,用 PAI-EAS 部署 AI 视频生成模型 SVD 工作流
本教程将带领大家免费领取阿里云PAI-EAS的免费试用资源,并且带领大家在 ComfyUI 环境下使用 SVD的模型,根据任何图片生成一个小短视频。
一文浅谈CodeReview中的一些思考
CodeReview在日常的开发过程中越来越被重视,它在提高代码质量同时促进团队成员之间的知识共享和技能提升方面发挥了诸多作用,本文将主要围绕CodeReview展开,简单聊聊在CodeReview过

乘风问答官5月排位赛开启!
2024年5月起乘风问答官专属活动全新起航鼓励问答官们积极给予高质量的解答和参与讨论给社区带来更好的体验~2024年5月问答官专属每周积分活动、每月排位赛开启欢迎问答官们参与。 面对对象 所有乘风问

Apache RocketMQ ACL 2.0 全新升级
RocketMQ ACL 2.0 不管是在模型设计、可扩展性方面,还是安全性和性能方面都进行了全新的升级。旨在能够为用户提供精细化的访问控制,同时,简化权限的配置流程。欢迎大家尝试体验新版本,并应用在
飞 天 技 术 沙 龙 | AI 原 生 应 用 架 构 专 场

表单新加了个字段A,历史数据要添加字段A的值问题
表单新加了个字段A历史数据要添加字段A的值管理页的批量修改这种方式是否是目前最好的方式了尝试过通过api接口的方式速度是快的但更新后只能在列表页看到字段A的数据详情页是看不到字段A的数据的。研究了下
阿里云云原生开源开发者沙龙北京站 PPT 合集

一文熟悉PolarDB-PG 分区表核心特性
在 PolarDB-PG 数据库中,分区表 (Partitioned Table) 使您能够将非常大的表分解为更小且更易于管理的部分,这个部分称为分区 (Partition) 。 每个分区都是一个独立
OpenKruise v1.6 版本解读:增强多域管理能力
OpenKruise 在 2024.3 发布了最新的 v1.6 版本(ChangeLog),本文对新版本的核心特性做整体介绍。
10倍性能提升-SLS Prometheus 时序存储技术演进
本文将介绍近期SLS Prometheus存储引擎的技术更新,在兼容 PromQL 的基础上实现 10 倍以上的性能提升。同时技术升级带来的成本红利也将回馈给使用SLS 时序引擎的上万内外部客户。
1 名工程师轻松管理 20 个工作流,创业企业用 Serverless 让数据处理流程提效
为应对挑战,语势科技采用云工作流CloudFlow和函数计算FC,实现数据处理流程的高效管理与弹性伸缩,提升整体研发效能。
VLDB顶会论文解读 | PolarDB MySQL高性能强一致集群核心技术详解
在VLDB2023会议上,阿里云瑶池数据库团队的论文介绍了PolarDB-SCC,这是一个创新的云原生数据库系统,确保了低延迟的全局强一致读取。PolarDB-SCC解决了传统主从架构中只读节点可能返
SLS 查询新范式:使用 SPL 对日志进行交互式探索
像 Unix 命令一样支持多级管道级联,像加工预览一样实时处理查询结果,更便捷的交互,更丰富的算子,更灵活的探索半结构化日志,快来试试使用 SPL 语言查询日志数据吧~
得物 ZooKeeper SLA 也可以 99.99%丨最佳实践
在本文中,作者探讨了ZooKeeper(ZK)的一个内存占用问题,特别是当有大量的Watcher和ZNode时,导致的内存消耗。
流水线运行出错排查难?AI 来帮你
目前云效流水线 Flow 内 Java 构建、Node.js 构建、Java 单元测试、Node.js 单元测试这 4 个步骤均接入了智能排查的能力。
高峰无忧,探索PolarDB PG版Serverless的弹性魅力
在数字经济时代,数据库成为企业命脉,面对爆炸式增长的数据,企业面临管理挑战。云原生和Serverless技术革新数据库领域,PolarDB PG Serverless作为阿里云的云原生数据库解决方案,
Serverless 应用引擎产品使用之在阿里函数计算中,使数据库和阿里云函数计算位于同一个内网中如何解决
阿里云Serverless 应用引擎(SAE)提供了完整的微服务应用生命周期管理能力,包括应用部署、服务治理、开发运维、资源管理等功能,并通过扩展功能支持多环境管理、API Gateway、事件驱动等
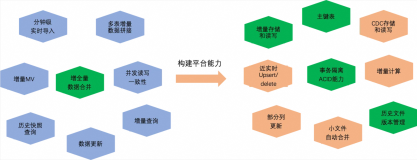
MaxCompute 近实时增全量处理一体化新架构和使用场景介绍
本文主要介绍基于 MaxCompute 的离线近实时一体化新架构如何来支持这些综合的业务场景,提供近实时增全量一体的数据存储和计算(Transaction Table2.0)解决方案。
国内独家|阿里云瑶池发布ClickHouse企业版:云原生Serverless新体验
全面升级为云原生架构,支持云原生按需弹性Serverless能力,解决了长期困扰用户的集群扩展效率和平滑性问题。

Llama 3开源!魔搭社区手把手带你推理,部署,微调和评估
Meta发布了 Meta Llama 3系列,是LLama系列开源大型语言模型的下一代。在接下来的几个月,Meta预计将推出新功能、更长的上下文窗口、额外的模型大小和增强的性能,并会分享 Llama

基于Ollama+AnythingLLM轻松打造本地大模型知识库
Ollama是开源工具,简化了在本地运行大型语言模型(ile优化模型运行,支持GPU使用和热加载。它轻量、易用,可在Mac和Linux上通过Docker快速部署。AnythingLLM是Mintple
云原生数据仓库产品使用合集之在云数据仓库ADB中,GROUP BY操作中出现NULL值,如何解决
阿里云AnalyticDB提供了全面的数据导入、查询分析、数据管理、运维监控等功能,并通过扩展功能支持与AI平台集成、跨地域复制与联邦查询等高级应用场景,为企业构建实时、高效、可扩展的数据仓库解决方案

数据管理DMS操作报错合集之阿里云DMS控制台上展示出了已经删除的数据库信息,如何解决
数据管理DMS(Data Management Service)是阿里云提供的数据库管理和运维服务,它支持多种数据库类型,包括RDS、PolarDB、MongoDB等。在使用DMS进行数据库操作时,可
【MySQL-10】数据库函数-案例演示【字符串/数值/日期/流程控制函数】(代码演示&可cv代码)
【MySQL-10】数据库函数-案例演示【字符串/数值/日期/流程控制函数】(代码演示&可cv代码)


Spring AI 抢先体验,5 分钟玩转 Java AI 应用开发
Spring Cloud Alibaba AI 以 Spring AI 为基础,并在此基础上提供阿里云通义系列大模型全面适配,让用户在 5 分钟内开发基于通义大模型的 Java AI 应用。
云原生数据仓库产品使用合集之ADB MySQL湖仓版和 StarRocks 的使用场景区别,或者 ADB 对比 StarRocks 的优劣势
阿里云AnalyticDB提供了全面的数据导入、查询分析、数据管理、运维监控等功能,并通过扩展功能支持与AI平台集成、跨地域复制与联邦查询等高级应用场景,为企业构建实时、高效、可扩展的数据仓库解决方案
查询提速11倍、资源节省70%,阿里云数据库内核版 Apache Doris 在网易日志和时序场景的实践
网易的灵犀办公和云信利用 Apache Doris 改进了大规模日志和时序数据处理,取代了 Elasticsearch 和 InfluxDB。Doris 实现了更低的服务器资源消耗和更高的查询性能,相

大数据技术与Python:结合Spark和Hadoop进行分布式计算
【4月更文挑战第12天】本文介绍了大数据技术及其4V特性,阐述了Hadoop和Spark在大数据处理中的作用。Hadoop提供分布式文件系统和MapReduce,Spark则为内存计算提供快速处理能力
阿里云 MaxCompute MaxFrame 开启免费邀测,统一 Python 开发生态
阿里云 MaxCompute MaxFrame 正式开启邀测,统一 Python 开发生态,打破大数据及 AI 开发使用边界。
阿里云ClickHouse企业版正式商业化,为开发者提供容灾性更好、性价比更高的实时数仓
2024年4月23日,阿里云联合 ClickHouse Inc. 成功举办了企业版商业化发布会。阿里云 ClickHouse 企业版是阿里云和 ClickHouse 原厂 ClickHouse. In
阿里云服务器计算型c7与c8y、通用型g7与g8y、内存型r7与r8y区别及选择参考
在阿里云目前的活动中,除了轻量应用服务器和经济型e、通用算力型u1实例的云服务器之外,性能更高的云服务器实例规格有计算型c7与c8y、通用型g7与g8y、内存型r7与r8y,这些实例规格更适合企业级用
在SeaTa中数据库postgresql的空间字段不能写入吗?
我用seata 部署 postgresql 数据库 数据库表里有涉及空间数据字段报错 报错如下 ps: 只要注释掉插入数据行中的空间字段就正常加上空间字段就报错 数据库postgresql表 C
云服务器中的mysql数据库为什么会被清空掉。
云服务器中的mysql数据库为什么会被清空掉。我自己在学习一个项目昨天登录还好好的今天登上去发现数据库中我自己建的库和表都没了。为什么会发生这样的问题我自己的ip和密码也没给过别人。
干货|代理IP协议有何区别?深入了解 SOCKS5、HTTP 代理
HTTP和HTTPS是互联网主要的两大协议,HTTP是基础的简单请求-响应协议,常用于TCP上,但数据传输不安全。HTTPS是HTTP的安全版本,添加了SSL层进行加密和身份验证,提供更高的安全性,用
干货|代理IP协议有何区别?深入了解 SOCKS5、HTTP 代理
SOCKS5和HTTP是两种代理协议,前者是通用型,支持多种网络流量,提供身份验证、IPv6支持及UDP兼容性,更适合实时数据传输。HTTP代理专用于HTTP协议,适用于Web资源请求。SOCKS5在
什么是基于协议的代理ip,代理ip的种类及区别
本文探讨了基于协议的代理IP类型,包括HTTP、HTTPS和SOCKS5代理。HTTP代理虽常见但不安全,数据未加密;HTTPS代理提供SSL加密,更安全,适合网页抓取和保护隐私;SOCKS5代理是通
C#/ASP.NET应用程序配置文件app.config/web.config的增、删、改操作
C#/ASP.NET应用程序配置文件app.config/web.config的增、删、改操作
Android应用] 问题2:ERROR: unknown virtual device name:
Android应用] 问题2:ERROR: unknown virtual device name:

