
阿里云开发者社区






大家在互动










综合
最新
有奖励
免费用

FunASR 语音大模型在 Arm Neoverse 平台上的优化实践
Arm 架构的服务器通常具备低功耗的特性,能带来更优异的能效比。相比于传统的 x86 架构服务器,Arm 服务器在相同功耗下能够提供更高的性能。这对于大模型推理任务来说尤为重要,因为大模型通常需要大量
让你的文档从静态展示到一键部署可操作验证
通过函数计算的能力让阿里云的文档从静态展示升级为动态可操作验证,用户在文档中单击一键部署可快速完成代码的部署及测试。这一改变已在函数计算的活动沙龙中得到用户的认可。
一键生成视频,用 PAI-EAS 部署 AI 视频生成模型 SVD 工作流
本教程将带领大家免费领取阿里云PAI-EAS的免费试用资源,并且带领大家在 ComfyUI 环境下使用 SVD的模型,根据任何图片生成一个小短视频。
卓越工程布道:掌握条件判断的模式
本文是普适性的经验分享,并非按规范局限在 JavaScript 前端视角 做出的总结,除JavaScript外还深入结合了ActionScript 3.0、PHP、C / C++、Basic非纯粹OO
飞天技术沙龙 | AI原生应用架构专场

阿里云云原生开源开发者沙龙北京站 PPT 合集


乘风问答官5月排位赛开启!
2024年5月起乘风问答官专属活动全新起航鼓励问答官们积极给予高质量的解答和参与讨论给社区带来更好的体验~2024年5月问答官专属每周积分活动、每月排位赛开启欢迎问答官们参与。 面对对象 所有乘风问
OpenKruise v1.6 版本解读:增强多域管理能力
OpenKruise 在 2024.3 发布了最新的 v1.6 版本(ChangeLog),本文对新版本的核心特性做整体介绍。
最佳实践|如何使用c++开发redis module
本文将试着总结Tair用c++开发redis module中遇到的一些问题并沉淀为最佳实践,希望对redis module的使用者和开发者带来一些帮助(部分最佳实践也适用于c和其他语言)。
围绕 transformers 构建现代 NLP 开发环境
本文将从“样本处理”,“模型开发”,“实验管理”,“工具链及可视化“ 几个角度介绍基于 tranformers 库做的重新设计,并简单聊聊个人对“软件2.0”的看法。
VLDB顶会论文解读 | PolarDB MySQL高性能强一致集群核心技术详解
在VLDB2023会议上,阿里云瑶池数据库团队的论文介绍了PolarDB-SCC,这是一个创新的云原生数据库系统,确保了低延迟的全局强一致读取。PolarDB-SCC解决了传统主从架构中只读节点可能返
1 名工程师轻松管理 20 个工作流,创业企业用 Serverless 让数据处理流程提效
为应对挑战,语势科技采用云工作流CloudFlow和函数计算FC,实现数据处理流程的高效管理与弹性伸缩,提升整体研发效能。
阿里云数据库内核 Apache Doris 基于 Workload Group 的负载隔离能力解读
阿里云数据库内核 Apache Doris 基于 Workload Group 的负载隔离能力解读

SLS 查询新范式:使用 SPL 对日志进行交互式探索
像 Unix 命令一样支持多级管道级联,像加工预览一样实时处理查询结果,更便捷的交互,更丰富的算子,更灵活的探索半结构化日志,快来试试使用 SPL 语言查询日志数据吧~
得物 ZooKeeper SLA 也可以 99.99%丨最佳实践
在本文中,作者探讨了ZooKeeper(ZK)的一个内存占用问题,特别是当有大量的Watcher和ZNode时,导致的内存消耗。
流水线运行出错排查难?AI 来帮你
目前云效流水线 Flow 内 Java 构建、Node.js 构建、Java 单元测试、Node.js 单元测试这 4 个步骤均接入了智能排查的能力。
高峰无忧,探索PolarDB PG版Serverless的弹性魅力
在数字经济时代,数据库成为企业命脉,面对爆炸式增长的数据,企业面临管理挑战。云原生和Serverless技术革新数据库领域,PolarDB PG Serverless作为阿里云的云原生数据库解决方案,
【云效流水线 Flow 测评】驾驭云海:五大场景下的云效Flow实战部署评测
云效是一款企业级持续集成和持续交付工具,提供免费、高可用的服务,集成阿里云多种服务,支持蓝绿、分批、金丝雀等发布策略。其亮点包括快速定位问题、节省维护成本、丰富的企业级特性及与团队协作的契合。基础版和
MaxCompute 近实时增全量处理一体化新架构和使用场景介绍
本文主要介绍基于 MaxCompute 的离线近实时一体化新架构如何来支持这些综合的业务场景,提供近实时增全量一体的数据存储和计算(Transaction Table2.0)解决方案。
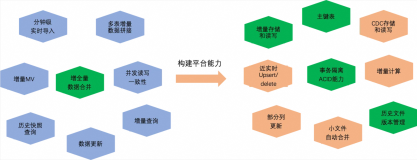
Serverless 应用引擎产品使用之在阿里函数计算中,使数据库和阿里云函数计算位于同一个内网中如何解决
阿里云Serverless 应用引擎(SAE)提供了完整的微服务应用生命周期管理能力,包括应用部署、服务治理、开发运维、资源管理等功能,并通过扩展功能支持多环境管理、API Gateway、事件驱动等
保姆级python项目离线部署服务器教程只需这一篇就够了(建议收藏)
这篇文章提供了详尽的Python项目在离线Linux(CentOS)服务器上的部署教程。作者首先介绍了环境背景,强调了无网络环境和使用有网络的CentOS虚拟机准备安装包的重要性。教程分为两部分:外网

Llama 3开源!魔搭社区手把手带你推理,部署,微调和评估
Meta发布了 Meta Llama 3系列,是LLama系列开源大型语言模型的下一代。在接下来的几个月,Meta预计将推出新功能、更长的上下文窗口、额外的模型大小和增强的性能,并会分享 Llama

国内独家|阿里云瑶池发布ClickHouse企业版:云原生Serverless新体验
全面升级为云原生架构,支持云原生按需弹性Serverless能力,解决了长期困扰用户的集群扩展效率和平滑性问题。


基于Ollama+AnythingLLM轻松打造本地大模型知识库
Ollama是开源工具,简化了在本地运行大型语言模型(ile优化模型运行,支持GPU使用和热加载。它轻量、易用,可在Mac和Linux上通过Docker快速部署。AnythingLLM是Mintple
云原生数据仓库产品使用合集之在云数据仓库ADB中,GROUP BY操作中出现NULL值,如何解决
阿里云AnalyticDB提供了全面的数据导入、查询分析、数据管理、运维监控等功能,并通过扩展功能支持与AI平台集成、跨地域复制与联邦查询等高级应用场景,为企业构建实时、高效、可扩展的数据仓库解决方案
Python小项目:利用tkinter开发测手速小游戏
这个小游戏使用Tkinter创建了一个简单的图形用户界面,用户点击“开始”按钮开始测试,然后点击“停止”按钮停止测试并显示反应时间。你可以根据需要进一步定制化游戏的界面和功能。
Python人工智能与机器学习
【4月更文挑战第11天】Python在AI和ML领域占主导地位,得益于其简洁语法、强大库支持和活跃社区。关键应用包括数据预处理(Pandas, NumPy)、模型训练(scikit-learn, Te
数据管理DMS操作报错合集之阿里云DMS控制台上展示出了已经删除的数据库信息,如何解决
数据管理DMS(Data Management Service)是阿里云提供的数据库管理和运维服务,它支持多种数据库类型,包括RDS、PolarDB、MongoDB等。在使用DMS进行数据库操作时,可
【专栏】Python在人工智能领域的应用现状、优势及未来趋势
【4月更文挑战第27天】本文探讨了Python在人工智能领域的应用现状、优势及未来趋势。Python作为数据科学、机器学习、深度学习和自然语言处理的首选语言,拥有丰富的库如NumPy、Pandas、T
【MySQL-10】数据库函数-案例演示【字符串/数值/日期/流程控制函数】(代码演示&可cv代码)
【MySQL-10】数据库函数-案例演示【字符串/数值/日期/流程控制函数】(代码演示&可cv代码)

阿里云 MaxCompute MaxFrame 开启免费邀测,统一 Python 开发生态
阿里云 MaxCompute MaxFrame 正式开启邀测,统一 Python 开发生态,打破大数据及 AI 开发使用边界。
一台机器最多能支持多少条 TCP 连接? 这个公式是什么?怎么计算,64gb的Linux服务器,可以
一台机器最多能支持多少条 TCP 连接? 这个公式是什么怎么计算64gb的Linux服务器可以支持多少条
一条 TCP 连接需要消耗多大的内存 ,像mysql这种连接数,和用户登录这种session信息,也
一条 TCP 连接需要消耗多大的内存像mysql这种连接数和用户登录这种session信息也是一条tcp连接吗
好看的html网站维护源码
好看的html网站维护源码,源码由HTML+CSS+JS组成,记事本打开源码文件可以进行内容文字之类的修改,双击html文件可以本地运行效果,也可以上传到服务器里面,

并发在JAVA可以显式使用线程池或者stream fork/join隐式去做,二者适合什么样的场景
并发在JAVA可以显式使用线程池或者stream fork/join隐式去做能说下二者分别适合什么样的场景么
50
假设传输带传送的是水果,接收者需要凑齐 100 个后才能装袋,但是传送带可能把这 100 个水果分批传送,比如第一批传送 20 个,第二批传送 50 个,第三批传送 30 个。接收者不需要和传送带保持
49
假设传输带传送的是水果,接收者需要凑齐 100 个后才能装袋,但是传送带可能把这 100 个水果分批传送,比如第一批传送 20 个,第二批传送 50 个,第三批传送 30 个。接收者不需要和传送带保持
48
假设传输带传送的是水果,接收者需要凑齐 100 个后才能装袋,但是传送带可能把这 100 个水果分批传送,比如第一批传送 20 个,第二批传送 50 个,第三批传送 30 个。接收者不需要和传送带保持
47
假设传输带传送的是水果,接收者需要凑齐 100 个后才能装袋,但是传送带可能把这 100 个水果分批传送,比如第一批传送 20 个,第二批传送 50 个,第三批传送 30 个。接收者不需要和传送带保持
46
假设传输带传送的是水果,接收者需要凑齐 100 个后才能装袋,但是传送带可能把这 100 个水果分批传送,比如第一批传送 20 个,第二批传送 50 个,第三批传送 30 个。接收者不需要和传送带保持
45
假设传输带传送的是水果,接收者需要凑齐 100 个后才能装袋,但是传送带可能把这 100 个水果分批传送,比如第一批传送 20 个,第二批传送 50 个,第三批传送 30 个。接收者不需要和传送带保持
44
假设传输带传送的是水果,接收者需要凑齐 100 个后才能装袋,但是传送带可能把这 100 个水果分批传送,比如第一批传送 20 个,第二批传送 50 个,第三批传送 30 个。接收者不需要和传送带保持
43
假设传输带传送的是水果,接收者需要凑齐 100 个后才能装袋,但是传送带可能把这 100 个水果分批传送,比如第一批传送 20 个,第二批传送 50 个,第三批传送 30 个。接收者不需要和传送带保持
42
假设传输带传送的是水果,接收者需要凑齐 100 个后才能装袋,但是传送带可能把这 100 个水果分批传送,比如第一批传送 20 个,第二批传送 50 个,第三批传送 30 个。接收者不需要和传送带保持
对于分布式系统中NPC。N,网络延迟P,进程暂停C时钟漂移 你有什么好的理解或解决方案呢。
对于分布式系统中的难以逾越的三座大山NPC。NNetwork Delay网络延迟PProcess Pause进程暂停CClock Drift时钟漂移 你有什么好的理解或解决方案呢。
40
为什么流格式套接字可以达到高质量的数据传输呢?这是因为它使用了 TCP 协议(The Transmission Control Protocol,传输控制协议),TCP 协议会控制你的数据按照顺序到达
39
为什么流格式套接字可以达到高质量的数据传输呢?这是因为它使用了 TCP 协议(The Transmission Control Protocol,传输控制协议),TCP 协议会控制你的数据按照顺序到达
38
为什么流格式套接字可以达到高质量的数据传输呢?这是因为它使用了 TCP 协议(The Transmission Control Protocol,传输控制协议),TCP 协议会控制你的数据按照顺序到达
37
为什么流格式套接字可以达到高质量的数据传输呢?这是因为它使用了 TCP 协议(The Transmission Control Protocol,传输控制协议),TCP 协议会控制你的数据按照顺序到达
36
为什么流格式套接字可以达到高质量的数据传输呢?这是因为它使用了 TCP 协议(The Transmission Control Protocol,传输控制协议),TCP 协议会控制你的数据按照顺序到达
35
为什么流格式套接字可以达到高质量的数据传输呢?这是因为它使用了 TCP 协议(The Transmission Control Protocol,传输控制协议),TCP 协议会控制你的数据按照顺序到达
34
为什么流格式套接字可以达到高质量的数据传输呢?这是因为它使用了 TCP 协议(The Transmission Control Protocol,传输控制协议),TCP 协议会控制你的数据按照顺序到达
33
为什么流格式套接字可以达到高质量的数据传输呢?这是因为它使用了 TCP 协议(The Transmission Control Protocol,传输控制协议),TCP 协议会控制你的数据按照顺序到达
32
为什么流格式套接字可以达到高质量的数据传输呢?这是因为它使用了 TCP 协议(The Transmission Control Protocol,传输控制协议),TCP 协议会控制你的数据按照顺序到达
31
为什么流格式套接字可以达到高质量的数据传输呢?这是因为它使用了 TCP 协议(The Transmission Control Protocol,传输控制协议),TCP 协议会控制你的数据按照顺序到达
基于51单片机的车辆倒车雷达报警系统
该文描述了一个基于51单片机的超声波倒车雷达系统设计,要求包括:2cm至4m的测量范围,3mm精度,集成DS18B20温度传感器以校准声速,使用LCD1602显示距离和温度,具备按键设置预警距离及蜂鸣
30
1、流格式套接字(SOCK_STREAM) 流格式套接字(Stream Sockets)也叫“面向连接的套接字”,在代码中使用 SOCK_STREAM 表示。 SOCK_STREAM 是一种可靠的、双
29
1、流格式套接字(SOCK_STREAM) 流格式套接字(Stream Sockets)也叫“面向连接的套接字”,在代码中使用 SOCK_STREAM 表示。 SOCK_STREAM 是一种可靠的、双
28
1、流格式套接字(SOCK_STREAM) 流格式套接字(Stream Sockets)也叫“面向连接的套接字”,在代码中使用 SOCK_STREAM 表示。 SOCK_STREAM 是一种可靠的、双
27
1、流格式套接字(SOCK_STREAM) 流格式套接字(Stream Sockets)也叫“面向连接的套接字”,在代码中使用 SOCK_STREAM 表示。 SOCK_STREAM 是一种可靠的、双
26
1、流格式套接字(SOCK_STREAM) 流格式套接字(Stream Sockets)也叫“面向连接的套接字”,在代码中使用 SOCK_STREAM 表示。 SOCK_STREAM 是一种可靠的、双
25
1、流格式套接字(SOCK_STREAM) 流格式套接字(Stream Sockets)也叫“面向连接的套接字”,在代码中使用 SOCK_STREAM 表示。 SOCK_STREAM 是一种可靠的、双
24
1、流格式套接字(SOCK_STREAM) 流格式套接字(Stream Sockets)也叫“面向连接的套接字”,在代码中使用 SOCK_STREAM 表示。 SOCK_STREAM 是一种可靠的、双
23
1、流格式套接字(SOCK_STREAM) 流格式套接字(Stream Sockets)也叫“面向连接的套接字”,在代码中使用 SOCK_STREAM 表示。 SOCK_STREAM 是一种可靠的、双
22
1、流格式套接字(SOCK_STREAM) 流格式套接字(Stream Sockets)也叫“面向连接的套接字”,在代码中使用 SOCK_STREAM 表示。 SOCK_STREAM 是一种可靠的、双
21
1、流格式套接字(SOCK_STREAM) 流格式套接字(Stream Sockets)也叫“面向连接的套接字”,在代码中使用 SOCK_STREAM 表示。 SOCK_STREAM 是一种可靠的、双
20
这个世界上有很多种套接字,Internet 套接字、Unix套接字、X.25 套接字等。 这里我们讨论 Internet 套接字,它是最具代表性的,也是最经典最常用的。我们经常提及的套接字,基本也都是

19
这个世界上有很多种套接字,Internet 套接字、Unix套接字、X.25 套接字等。 这里我们讨论 Internet 套接字,它是最具代表性的,也是最经典最常用的。我们经常提及的套接字,基本也都是

18
这个世界上有很多种套接字,Internet 套接字、Unix套接字、X.25 套接字等。 这里我们讨论 Internet 套接字,它是最具代表性的,也是最经典最常用的。我们经常提及的套接字,基本也都是

17
这个世界上有很多种套接字,Internet 套接字、Unix套接字、X.25 套接字等。 这里我们讨论 Internet 套接字,它是最具代表性的,也是最经典最常用的。我们经常提及的套接字,基本也都是

16
这个世界上有很多种套接字,Internet 套接字、Unix套接字、X.25 套接字等。 这里我们讨论 Internet 套接字,它是最具代表性的,也是最经典最常用的。我们经常提及的套接字,基本也都是

15
这个世界上有很多种套接字,Internet 套接字、Unix套接字、X.25 套接字等。 这里我们讨论 Internet 套接字,它是最具代表性的,也是最经典最常用的。我们经常提及的套接字,基本也都是

14
这个世界上有很多种套接字,Internet 套接字、Unix套接字、X.25 套接字等。 这里我们讨论 Internet 套接字,它是最具代表性的,也是最经典最常用的。我们经常提及的套接字,基本也都是

13
这个世界上有很多种套接字,Internet 套接字、Unix套接字、X.25 套接字等。 这里我们讨论 Internet 套接字,它是最具代表性的,也是最经典最常用的。我们经常提及的套接字,基本也都是


