

阿里云开发者社区






大家在互动










综合
最新
有奖励
免费用
QwQ-32B一键部署!真正的0代码,0脚本,0门槛
阿里云发布的QwQ-32B模型通过强化学习显著提升了推理能力,核心指标达到DeepSeek-R1满血版水平。用户可通过阿里云系统运维管理(OOS)一键部署OpenWebUI+Ollama方案,轻松将Q

魔搭×通义灵码:0代码基础、0门槛在线编程做应用
本节课主要介绍了如何利用 Notebook IDE 环境和通义灵码工具来具体开发 AI 产品,通过前面的介绍,可以感受到好的开发环境和开发工具往往可以让开发过程事半功倍,也可以更快更好地解决一些实际问
技术小白如何利用DeepSeek半小时开发微信小程序?
通过通义灵码的“AI程序员”功能,即使没有编程基础也能轻松创建小程序或网页。借助DeepSeek V3和R1满血版模型,用户只需用自然语言描述需求,就能自动生成代码并优化程序。例如,一个文科生仅通过描

Hologres Dynamic Table快速入门
本文由Hologres PD赵红梅分享,主题为Dynamic Table快速入门。内容分为三部分:一是介绍Dynamic Table,包括其在实时数仓中的应用场景及技术实现;二是讲解Dynamic T
【最佳实践系列】AI程序员让我变成全栈:基于阿里云百炼DeepSeek的跨语言公告系统实战
本文介绍了如何在Java开发中通过跨语言编程,利用阿里云百炼服务平台的DeepSeek大模型生成公告内容,并将其嵌入前端页面。
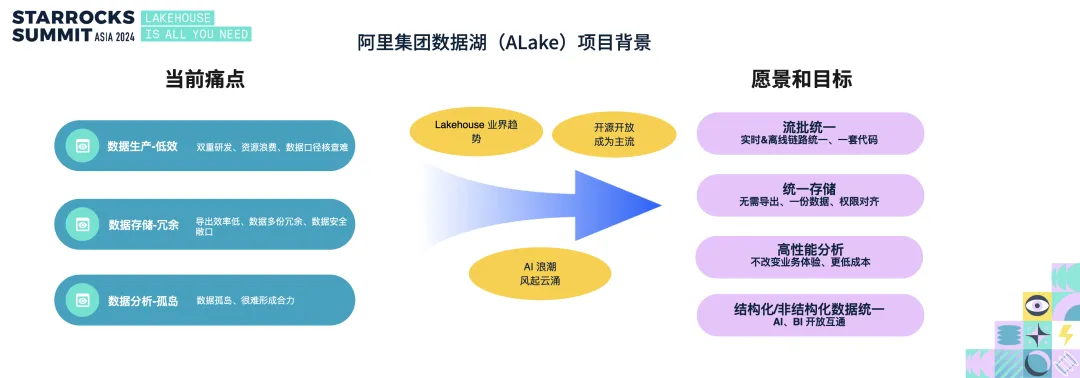
StarRocks + Paimon 在阿里集团 Lakehouse 的探索与实践
阿里集团在推进湖仓一体化建设过程中,依托 StarRocks 强大的 OLAP 查询能力与 Paimon 的高效数据入湖特性,实现了流批一体、存储成本大幅下降、查询性能数倍提升的显著成效: A+ 业务
快速使用 DeepSeek-R1 满血版
DeepSeek是一款基于Transformer架构的先进大语言模型,以其强大的自然语言处理能力和高效的推理速度著称。近年来,DeepSeek不断迭代,从DeepSeek-V2到参数达6710亿的De

DeepSeek个人站点一键部署流程演示

Flink CDC任务从savepoint/checkpoints状态中恢复作业错误问题
flink CDC任务监听mysql数据。只要不是从savepoint/checkpoint中恢复都是能成功运行并监听数据的但是只要从savepoint/checkpoint中恢复作业就会报如下错误
人人懂AI之从机器学习到大模型
本书面向广大IT从业者,作者将尽可能通俗易懂的把机器学习、深度学习、神经网络等基本原理讲解清楚,并分享大语言模型、知识库等当下很火爆的AIGC应用,探讨大语言模型“知识茧房”问题及解法。期望本书能成为

基于阿里百炼的DeepSeek-R1满血版模型调用【零门槛保姆级2084小游戏开发实战】
本文介绍基于阿里百炼的DeepSeek-R1满血版模型调用,提供零门槛保姆级2048小游戏开发实战。文章分为三部分:定位与核心优势、实战部署操作指南、辅助实战开发。通过详细步骤和案例展示,帮助开发者高

一键部署Dify+DeepSeek On DMS,实现【联网搜索满血版】DeepSeek
一键部署 Dify + DeepSeek On DMS,开箱即用,VPC 部署,数据不出域更安全,结合夸克搜索,实现【联网搜索满血版】 DeepSeek,全方位融合阿里生态,一键开启企业 GenAI

操作系统停服应用指南
随着信息技术的快速发展,操作系统作为支撑应用程序和服务运行的基础层,承担着至关重要的角色。然而,操作系统和其他软件系统类似,都将经历生命周期的不同阶段,包括引入、增长、成熟和最终的停服。处于生命周期的

基于 DIFY 的自动化数据分析实战
本文介绍如何使用DIFY搭建数据分析自动化流程,实现从输入需求到查询数据库、LLM分析再到可视化输出的全流程。基于经典的employees数据集和DIFY云端环境,通过LLM-SQL解析、SQL执行、
阿里云百炼已上线超强推理开源模型QwQ-32B,尺寸更小,性能比肩DeepSeek满血版
通义千问团队推出了320亿参数的QwQ-32B模型,通过大规模强化学习和多阶段训练,在数学、编程及通用能力上达到或超越了DeepSeek-R1等先进模型。QwQ-32B模型已在阿里云百炼上线,支持AP
VMware Workstation 17.6.3 发布下载,现在完全免费无论个人还是商业用途
VMware Workstation 17.6.3 发布下载,现在完全免费无论个人还是商业用途
指南:Claude 3.7 怎么样?国内如何使用Claude 3.7 Sonnet?
本文主要介绍了Claude 3.7 Sonnet模型的发布教你如何订阅使用Claude 3.7 Sonnect及其新功能,特别是Claude Code工具的推出。
Heygem:开源数字人克隆神器!1秒视频生成4K超高清AI形象,1080Ti显卡也能轻松跑
Heygem 是硅基智能推出的开源数字人模型,支持快速克隆形象和声音,30秒内完成克隆,60秒内生成4K超高清视频,适用于内容创作、直播、教育等场景。
高效部署通义万相Wan2.1:ComfyUI文生/图生视频实战,工作流直取!
通义万相Wan2.1开源不到一周,已登顶HuggingFace Model 和 Space 榜双榜首,在HuggingFace和ModelScope平台的累计下载量突破100万次,社区热度持续攀升!为
快速调用 Deepseek API!【超详细教程】
Deepseek 强大的功能,在本教程中,将指导您如何获取 DeepSeek API 密钥,并演示如何使用该密钥调用 DeepSeek API 以进行调试。
满血上阵,DeepSeek x 低代码创造专属知识空间
本文介绍了如何结合阿里云百炼和魔笔平台,快速构建一个智能化的专属知识空间。通过利用DeepSeek R1等先进推理模型,实现高效的知识管理和智能问答系统。 5. **未来扩展**:探讨多租户隔离、终端
用DeepSeek,就在阿里云!四种方式助您快速使用 DeepSeek-R1 满血版!更有内部实战指导!
DeepSeek自发布以来,凭借卓越的技术性能和开源策略迅速吸引了全球关注。DeepSeek-R1作为系列中的佼佼者,在多个基准测试中超越现有顶尖模型,展现了强大的推理能力。然而,由于其爆火及受到黑客
从0到1彻底掌握Trae:手把手带你实战开发AI Chatbot,提升开发效率的必备指南!
Trae是字节跳动推出的一款免费的AI集成的开发环境,集成了Claude3.5与GPT-4o等主流AI模型,提供AI问答、智能代码生成、智能代码补全,多模态输入等功能。支持界面全中文化,为中文开发者提
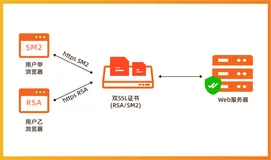
阿里云WoSign“国密RSA双SSL证书”应用实践
阿里云WoSign品牌SSL证书是阿里云平台热销的国产品牌证书之一,支持签发国密合规的SM2算法SSL证书以及全球信任的RSA算法SSL证书,能够满足平台用户不同的SSL证书应用需求,同时为用户提供国
Botgroup.chat:超有趣的开源 AI 聊天室!多个 AI 在线互怼,一键搭建你的专属 AI 社群
Botgroup.chat 是一款基于 React 和 Cloudflare Pages 的开源 AI 聊天应用,支持多个 AI 角色同时参与对话,提供类似群聊的交互体验。
在ECS上使用百炼部署满血版DeepSeek R1
本文为您介绍如何在ECS实例上部署Open WebUI,并通过大模型服务平台百炼API调用DeepSeek-R1模型推理服务。帮助您快速体验满血版DeepSeek-R1模型。
本地部署DeepSeek模型技术指南
DeepSeek模型是一种先进的深度学习模型,广泛应用于自然语言处理等领域。本文详细指导如何在本地部署DeepSeek模型,涵盖环境准备(硬件和软件要求、依赖库安装)、模型下载与配置、部署(创建Fla
阿里妈妈基于 Flink+Paimon 的 Lakehouse 应用实践
本文总结了阿里妈妈数据技术专家陈亮在Flink Forward Asia 2024大会上的分享,围绕广告业务背景、架构设计及湖仓方案演进展开。内容涵盖广告生态运作、实时数仓挑战与优化,以及基于Paim

Browser Use:40.7K Star!一句话让AI完全接管浏览器!自动规划完成任务,多标签页同时管理
Browser Use 是一款专为大语言模型设计的智能浏览器自动化工具,支持多标签页管理、视觉识别、内容提取等功能,并能记录和重复执行特定动作,适用于多种应用场景。


2025阿里云智惠采购季,WoSign SSL国产证书折上折满减优惠
**2025阿里云“智慧采购季,就上阿里云”活动火热进行中!** 3月1日至31日,阿里云WoSign品牌SSL证书新老用户同享折上折满减优惠。DV SSL证书低至220元/年起,轻松实现HTTPS加

云产品评测|快速体验AI时代下的BI——Quick BI
Quick BI是阿里云推出的智能商业分析工具,连续多年入选Gartner ABI魔力象限。它通过“大模型”、“零代码”和“增强分析”等技术,将复杂的数据转化为直观的可视化体验。用户可轻松创建数据集、
云产品评测|云安全这道坎,企业该怎么迈?阿里云「安全体检」实测报告
随着云计算的普及,云安全问题日益突出。阿里云提供的免费“安全体检”工具,能够自动化检测系统漏洞、风险配置和病毒攻击,帮助用户及时发现并修复潜在的安全隐患。通过实际测试,该工具在基础漏洞检测方面表现出色
2025年NVIDIA RTX 4090服务器租赁价格与选型详解
随着AI训练、深度学习与图形渲染需求激增,NVIDIA RTX 4090显卡成为算力租赁市场的热门选择。本文从价格体系、配置适配、成本优化三方面解析4090服务器租赁策略,涵盖短租长租价格差异、主流平
三分钟让Dify接入Ollama部署的本地大模型!
本文介绍了如何运行 Ollama 并在 Dify 中接入 Ollama 模型。通过命令 `ollama run qwen2:0.5b` 启动 Ollama 服务,访问 `http://localhos
新用户100万token免费额度!阿里云上线DeepSeek-R1满血版
阿里云推出DeepSeek-R1满血版,新用户可享100万免费Token额度。平台支持多种模型,包括671B参数的DeepSeek-R1和通义千问。结合开源工具Chatbox,用户能轻松对接API,体
Manus:或将成为AI Agent领域的标杆
随着人工智能技术的飞速发展,AI Agent(智能体)作为人工智能领域的重要分支,正逐渐从概念走向现实,并在各行各业展现出巨大的应用潜力。在众多AI Agent产品中,Manus以其独特的技术优势和市
Trae 接入 Claude 3.7:AI 编程工具界的“卷王”,完全免费使用!
Trae 是一款完全免费的AI编程工具,现已接入 Claude 3.7 模型,提供代码生成、调试等强大功能,支持多模态输入和上下文理解,用户可享受24小时高速服务,无需担心付费限制。Trae 支持多平
零门槛、百万token免费用,即刻拥有DeepSeek-R1满血版,还有实践落地调用场景等你来看
DeepSeek 是热门的推理模型,能在少量标注数据下显著提升推理能力,尤其擅长数学、代码和自然语言等复杂任务。本文涵盖四种部署方案,可以让你快速体验云上调用 DeepSeek-R1 满血版的 API
从零开始即刻拥有 DeepSeek-R1 满血版并使用 Dify 部署 AI 应用
本文介绍了如何使用阿里云提供的DeepSeek-R1大模型解决方案,通过Chatbox和Dify平台调用百炼API,实现稳定且高效的模型应用。首先,文章详细描述了如何通过Chatbox配置API并开始
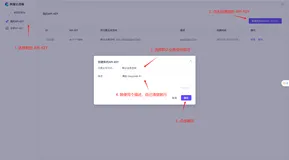
DeepSeek一体机!飞天企业版上新“AI Stack”,支持DeepSeek满血版和Qwen单机部署!
飞天企业版上新“AI Stack”,支持DeepSeek满血版和Qwen单机部署!
【上云基础系列-01】如何把控公网带宽费,实现低成本用云(基于单体架构)
本文主要面向开发者,介绍在单体架构下如何巧妙选择服务器和公网产品方案,实现低门槛用云。针对个人开发者和企业不同需求,推荐使用阿里云的ECS、EIP和CDT组合方案,特别是CDT提供的200GB/月免费
CentOS下载ISO镜像的方法
访问CentOS官方网站(https://www.centos.org/download/),在“Downloads”页面找到ISO镜像下载链接,选择所需版本和架构(如x86_64)开始下载。Cent
QwQ-32B,支持Function Call的推理模型,深度思考Agent的时代来了!
近期,Qwen 发布了 QwQ-32B - 一个在许多基准测试中性能可与 DeepSeek-R1 相媲美的推理模型。
some小窍门
本文总结了 Java 开发中的几个重要编码规范与优化建议: 1. **Map 初始化大小**:避免直接初始化 HashMap 时指定不准确的容量。 2. **线程池创建**:禁止使用 `Executo
java面试-基础语法与面向对象
本文介绍了 Java 编程中的几个核心概念。首先,详细区分了方法重载与重写的定义、发生阶段及规则;其次,分析了 `==` 与 `equals` 的区别,强调了基本类型和引用类型的比较方式;接着,对比了
《探寻计算图奥秘:动态与静态在自然语言处理中的分野》
在自然语言处理(NLP)领域,模型训练依赖计算图这一底层架构。动态计算图以灵活性见长,适合调试与开发,但运行效率较低;静态计算图则以高效性和全局优化能力著称,利于大规模训练和部署,但调试复杂且灵活性受
《自然语言处理架构的隐秘力量:FFN深度揭秘》
前馈神经网络(FFN)是自然语言处理(NLP)领域中不可或缺的组件,尤其在Transformer等架构中发挥重要作用。FFN通过非线性变换和特征提取,增强模型对复杂语义的理解能力,同时平衡注意力机制输
《揭开多头注意力机制的神秘面纱:解锁自然语言处理的超能力》
多头注意力机制是自然语言处理(NLP)领域的核心技术,基于人类大脑选择性关注的灵感,通过多个“注意力头”从不同角度分析输入数据,显著提升模型对语言的理解和表达能力。它在Transformer架构中广泛
《深度剖析:BERT与GPT——自然语言处理架构的璀璨双星》
BERT与GPT系列模型是自然语言处理(NLP)领域的里程碑。基于Transformer架构,BERT通过双向编码实现深度语言理解,适用于情感分析、命名实体识别等任务;GPT则以单向生成见长,能够创作
数据库的行级锁与表锁?
表锁: 不会出现死锁,发生锁的冲突几率高,并发性低。 存储引擎在进行SQL数据读写请求前,会对涉及到的表进行加锁。 其中锁分为共享读锁和独占写锁:读锁会阻塞写,写锁会阻塞读和写。 行级锁: 会出
为什么索引的数量不能太多?
当对表中的数据进行增加、删除、修改时,同时需要动态维护索引,降低了整体的维护速度。 索引需要占据物理空间,如果要建立聚簇索引,那么需要的空间就会更大,因为会将数据存储于叶子节点。 创建索引和维护索引要
创建索引的注意事项?
非空字段:索引字段不能有NULL,如果有NULL值将不会包含在索引中。 索引字段越小越好:数据库的数据存储以页为单位一页存储的数据越多一次IO操作获取的数据越大效率越高。 唯一、不为空、经常被查询的字
事务的四大特性?
原子性:指事务包含的所有操作要么全部成功,要么全部失败回滚,因此事务的操作如果成功就必须完全应用到数据库,如果操作失败则不能对数据库有任何影响。 一致性:指事务开始前和结束后,数据库的完整性约束没有被
InnoDB与MyISAM实现索引方式的区别?
首先两者都是用的是B+树索引,但二者的实现方式不同。 对于主键索引,InnoDB中叶子节点保存了完整的数据记录,而MyISAM中索引文件与数据文件是分离的,叶子节点上的索引文件仅保存了数据记录的地址.
什么是聚簇索引及其优缺点?
聚簇索引并不是单独的索引类型,而是一种数据存储方式。 B+树索引分为聚簇索引和非聚簇索引,主键索引就是聚簇索引的一种,非聚簇索引有复合索引、前缀索引、唯一索引。 在innodb存储引擎中,表数据本身就
MySQL索引有哪些类型?
● 普通索引:最基本的索引,没有任何限制。 ● 唯一索引:索引列的值必须唯一,但可以有空值。可以创建组合索引,则列值的组合必须唯一。 ● 主键索引:是特殊的唯一索引,不可以有空值,且表中只存在一个该值
数据库索引采用B+树不采用B树的原因?
● B+树更便于遍历:由于B+树的数据都存储在叶子结点中,分支结点均为索引,方便扫库,只需要扫一遍叶子结点即可,但是B树因为其分支结点同样存储着数据,我们要找到具体的数据,需要进行一次中序遍历按序来扫
关系型与非关系型数据库的区别
关系型数据库是依据关系模型来创建的数据库,所谓关系模型就是“一对一”、“一对多”、“对多对”等。常见的关系型数据库有Oracle、MySQL、SQL Server等。非关系型数据库主要基于“非关系型模
什么是死信交换机 ? 如何为队列绑定死信交换机 ?
死 信交换机和正常的交换机没有什么不同 , 如果一个包含死信的队列配置了dead-letter-exchange属性,指定了一个交换机,那么队列中的死信就会投递到这个交换机中,而这个交换机称为死信交换
什么情况下消息会成为死信 ?
当一个队列中的消息满足下列情况之一时,就会成为死信(dead letter): ● 消费者使用basic.reject或 basic.nack声明消费失败,并且消息的requeue参数设置为false
消息的重复消费问题如何解决
在使用RabbitMQ进行消息收发的时候, 如果发送失败或者消费失败会自动进行重试, 那么就有可能会导致消息的重复消费 , 具体的解决方案其实非常简单, 为每条消息设置一个唯一的标识id , 将已经消
使用RabbitMQ如何保证消息不丢失 ?
消息从发送,到消费者接收,会经理多个过程 , 其中的每一步都可能导致消息丢失 针对这些问题,RabbitMQ分别给出了解决方案: ● 消息发送到交换机丢失 : 发布者确认机制publisher-co
为什么会选择使用RabbitMQ ? 有什么好处 ?
选择使用RabbitMQ是因为RabbitMQ的功能比较丰富 , 支持各种消息收发模式(简单队列模式, 工作队列模式 , 路由模式 , 直接模式 , 主题模式等) , 支持延迟队列 , 惰性队列而且天
断路器/熔断器? 断路器的状态有哪些
● closed:关闭状态,断路器放行所有请求,并开始统计异常比例、慢请求比例。超过阈值则切换到open状态 ● open:打开状态,服务调用被熔断,访问被熔断服务的请求会被拒绝,快速失败,直接走降级
负载均衡如何实现
服务调用过程中的负载均衡一般使用SpringCloud的Ribbon 组件实现 , Feign的底层已经自动集成了Ribbon , 使用起来非常简单 客户端调用的话一般会通过网关, 通过网关实现请求的
什么是微服务?微服务的优缺点是什么?
微服务就是一个独立的职责单一的服务应用程序,一个模块 1.优点:松耦合,聚焦单一业务功能,无关开发语言,团队规模降低 , 扩展性好, 天然支持分库2.缺点:随着服务数量增加,管理复杂,部署复杂,服务器
Spring Cloud 5大组件有哪些?
早期我们一般认为的Spring Cloud五大组件是 ● Eureka : 注册中心 ● Ribbon : 负载均衡 ● Feign : 远程调用 ● Hystrix : 服务熔断 ● Zuul/G
Spring Boot的核心注解是哪个?他由哪几个注解组成的?
Spring Boot的核心注解是@SpringBootApplication , 他由几个注解组成 : ● @SpringBootConfiguration: 组合了- @Configuratio
SpringBoot启动流程
springboot项目在启动的时候, 首先会执行启动引导类里面的SpringApplication.run(AdminApplication.class, args)方法 这个run方法主要做的事情
SpringBoot自动装配的原理
在SpringBoot项目的启动引导类上都有一个注解@SpringBootApplication 这个注解是一个复合注解, 其中有三个注解构成 , 分别是 ● @SpringBootConfigura
Redis分布式锁如何实现 ?
Redis分布式锁主要依靠一个SETNX指令实现的 , 这条命令的含义就是“SET if Not Exists”,即不存在的时候才会设置值。 只有在key不存在的情况下,将键key的值设置为value
什么是缓存雪崩 ? 怎么解决 ?
缓存雪崩/缓存失效 指的是大量的缓存在同一时间失效,大量请求落到数据库 导致数据库瞬间压力飙升。 造成这种现象的 原因是,key的过期时间都设置成一样了。 解决方案是,key的过期时间引入随机因素
什么是缓存击穿 ? 怎么解决 ?
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大 解决方案 : ● 热点数据提前预热 ●
什么是缓存穿透 ? 怎么解决 ?
缓存穿透是指查询一条数据库和缓存都没有的一条数据,就会一直查询数据库,对数据库的访问压力就会增大,缓存穿透的解决方案 有以下2种解决方案 : ● 缓存空对象:代码维护较简单,但是效果不好。 ● 布
Redis和Mysql如何保证数据⼀致?
1. 先更新Mysql,再更新Redis,如果更新Redis失败,可能仍然不⼀致 2. 先删除Redis缓存数据,再更新Mysql,再次查询的时候在将数据添加到缓存中 这种⽅案能解决1 ⽅案的问题,但
Redis分片集群中数据是怎么存储和读取的 ?
Redis集群采用的算法是哈希槽分区算法。Redis集群中有16384个哈希槽(槽的范围是 0 -16383,哈希槽),将不同的哈希槽分布在不同的Redis节点上面进行管理,也就是说每个Redis节点
什么是 Redis 主从同步?
Redis 的主从同步(replication)机制,允许 Slave 从 Master 那里,通过网络传输拷贝到完整的数据备份,从而达到主从机制。 主数据库可以进行读写操作,当发生写操作的时候自动将
Redis集群有哪些方案
1. 主从复制集群 : 读写分离, 一主多从 , 解决高并发读的问题 2. 哨兵集群 : 主从集群的结构之上 , 加入了哨兵用于监控集群状态 , 主节点出现故障, 执行主从切换 , 解决高可用问题 3
Redis的数据淘汰策略有哪些 ?
Redis 提供 8 种数据淘汰策略: 淘汰易失数据(具有过期时间的数据) 1. volatile-lru(least recently used):从已设置过期时间的数据集(server.db[i]
Redis的数据过期策略有哪些 ?
1. 惰性删除 :只会在取出 key 的时候才对数据进行过期检查。这样对 CPU 最友好,但是可能会造成太多过期 key 没有被删除。数据到达过期时间,不做处理。等下次访问该数据时,我们需要判断
Redis的数据持久化策略有哪些 ?
Redis 提供了两种方式,实现数据的持久化到硬盘。 1. RDB 持久化(全量),是指在指定的时间间隔内将内存中的数据集快照写入磁盘。 2. AOF持久化(增量),以日志的形式记录服务器所处理的每一
MongoDB实战演练
本文介绍了基于Spring Boot和MongoDB实现文章评论功能的完整流程。主要包括需求分析、表结构设计、技术选型(如mongodb-driver与SpringDataMongoDB)、项目搭建及
索引是越多越好嘛? 什么样的字段需要建索引, 什么样的字段不需要 ?
需要创建索引情况 1. 主键自动建立主键索引 2. 频繁作为查询条件的字段应该创建索引 3. 多表关联查询中,关联字段应该创建索引 (on 两边都要创建索引) 4. 查询中排序的字段,应该创建索引 5
什么情况下索引会失效 ?
MySQL 索引通常是被用于提高 WHERE 条件的数据行匹配时的搜索速度,编写合理化的SQL能够提高SQL的执行效率 1. 不要在列上使用函数和进行运算 2. 不要在列上使用函数,这将导致索引失效而
什么是左前缀原则
在mysql建立联合索引时会遵循左前缀匹配的原则,即最左优先,在检索数据时从联合索引的最左边开始匹配,组合索引的第一个字段必须出现在查询组句中,这个索引才会被用到 ; 例如 : create ind
什么叫覆盖索引
覆盖索引是指只需要在一棵索引树上就能获取SQL所需的所有列数据 , 因为无需回表查询效率更高 实现覆盖索引的常见方法是:将被查询的字段,建立到联合索引里去。 执行如下查询语句 : select nam
什么是回表查询
当我们为一张表的name字段建立了索引 , 执行如下查询语句 : select name,age from user where name='Alice' 那么获取到数据的过程为 : 1. 根据n
MYSQL支持的存储引擎有哪些, 有什么区别
MYSQL存储引擎有很多, 常用的就二种 : MyISAM和InnerDB , 者两种存储引擎的区别 ; ● MyISAM支持256TB的数据存储 , InnerDB只支持64TB的数据存储 ● M
索引的底层数据结构
索引是在存储引擎中实现的,也就是说不同的存储引擎,会使用不同的索引 MyISAM和InnoDB存储引擎:只⽀支持B+ TREE索引, 也就是说默认使用BTREE,不能够更换 MEMORY/HEAP存储
Mysql的索引
MYSQL索引主要有 : 单列索引 , 组合索引和空间索引 , 用的比较多的就是单列索引和组合索引 , 空间索引我这边没有用到过 单列索引 : 在MYSQL数据库表的某一列上面创建的索引叫单列索引 ,
Spring MVC常用的注解
@RequestMapping:用于处理请求 url 映射的注解,可用于类或方法上。用于类上,则表示类中 的所有响应请求的方法都是以该地址作为父路径。 @RequestBody:注解实现接收http
SpringMVC的执行流程
1. 用户发送请求至前端控制器DispatcherServlet; 2. DispatcherServlet收到请求后,调用HandlerMapping处理器映射器,请求获取Handle; 3. 处


