
阿里云开发者社区






大家在互动










综合
最新
有奖励
免费用
一文解读:阿里云AI基础设施的演进与挑战
对于如何更好地释放云上性能助力AIGC应用创新?“阿里云弹性计算为云上客户提供了ECS GPU DeepGPU增强工具包,帮助用户在云上高效地构建AI训练和AI推理基础设施,从而提高算力利用效率。”李
Apache RocketMQ ACL 2.0 全新升级
RocketMQ ACL 2.0 不管是在模型设计、可扩展性方面,还是安全性和性能方面都进行了全新的升级。旨在能够为用户提供精细化的访问控制,同时,简化权限的配置流程。欢迎大家尝试体验新版本,并应用在
案例分析|线程池相关故障梳理&总结
本文作者梳理和分享了线程池类的故障,分别从故障视角和技术视角两个角度来分析总结,故障视角可以看到现象和教训,而技术视角可以透过现象看到本质更进一步可以看看如何避免。

飞天技术沙龙 | AI原生应用架构专场

阿里云云原生开源开发者沙龙北京站 PPT 合集


乘风问答官5月排位赛开启!
2024年5月起乘风问答官专属活动全新起航鼓励问答官们积极给予高质量的解答和参与讨论给社区带来更好的体验~2024年5月问答官专属每周积分活动、每月排位赛开启欢迎问答官们参与。 面对对象 所有乘风问
围绕 transformers 构建现代 NLP 开发环境
本文将从“样本处理”,“模型开发”,“实验管理”,“工具链及可视化“ 几个角度介绍基于 tranformers 库做的重新设计,并简单聊聊个人对“软件2.0”的看法。
10倍性能提升-SLS Prometheus 时序存储技术演进
本文将介绍近期SLS Prometheus存储引擎的技术更新,在兼容 PromQL 的基础上实现 10 倍以上的性能提升。同时技术升级带来的成本红利也将回馈给使用SLS 时序引擎的上万内外部客户。
SLS 查询新范式:使用 SPL 对日志进行交互式探索
像 Unix 命令一样支持多级管道级联,像加工预览一样实时处理查询结果,更便捷的交互,更丰富的算子,更灵活的探索半结构化日志,快来试试使用 SPL 语言查询日志数据吧~
得物 ZooKeeper SLA 也可以 99.99%丨最佳实践
在本文中,作者探讨了ZooKeeper(ZK)的一个内存占用问题,特别是当有大量的Watcher和ZNode时,导致的内存消耗。
流水线运行出错排查难?AI 来帮你
目前云效流水线 Flow 内 Java 构建、Node.js 构建、Java 单元测试、Node.js 单元测试这 4 个步骤均接入了智能排查的能力。
数据管理的艺术:PolarDB开源版详评与实战部署策略(一)
PolarDB-X是阿里巴巴自研的高性能云原生分布式数据库,基于共享存储的Shared-nothing架构,支持MySQL生态,具备金融级高可用、分布式水平扩展、HTAP混合负载等能力。它通过CN(计
高峰无忧,探索PolarDB PG版Serverless的弹性魅力
在数字经济时代,数据库成为企业命脉,面对爆炸式增长的数据,企业面临管理挑战。云原生和Serverless技术革新数据库领域,PolarDB PG Serverless作为阿里云的云原生数据库解决方案,
让研发规范管得住 - 我们为什么在流水线之上又做了研发流程?
研发规范的目标,是为了解决或降低出现软件危机的风险。但传统流水线受限于工具的定位,无法解决研发规范的落地问题,需要在更高的层面来解决。阿里云云效团队经过内部启发后推出的新产品:云效应用交付平台 App
为什么要用 Tair 来服务低延时场景 - 从购物车升级说起
“购物车升级”是今年双十一期间提升用户体验的关键项目,展示了大淘宝技术团队致力于通过技术突破消费者和商家体验的天花板。低延迟是这些挑战中的核心,内存数据库Tair因其高吞吐、大连接数、热点请求处理、异
【云效流水线 Flow 测评】驾驭云海:五大场景下的云效Flow实战部署评测
云效是一款企业级持续集成和持续交付工具,提供免费、高可用的服务,集成阿里云多种服务,支持蓝绿、分批、金丝雀等发布策略。其亮点包括快速定位问题、节省维护成本、丰富的企业级特性及与团队协作的契合。基础版和
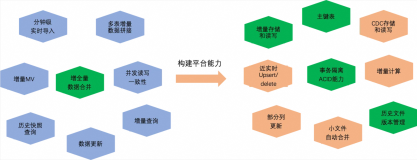
MaxCompute 近实时增全量处理一体化新架构和使用场景介绍
本文主要介绍基于 MaxCompute 的离线近实时一体化新架构如何来支持这些综合的业务场景,提供近实时增全量一体的数据存储和计算(Transaction Table2.0)解决方案。
保姆级python项目离线部署服务器教程只需这一篇就够了(建议收藏)
这篇文章提供了详尽的Python项目在离线Linux(CentOS)服务器上的部署教程。作者首先介绍了环境背景,强调了无网络环境和使用有网络的CentOS虚拟机准备安装包的重要性。教程分为两部分:外网


Llama 3开源!魔搭社区手把手带你推理,部署,微调和评估
Meta发布了 Meta Llama 3系列,是LLama系列开源大型语言模型的下一代。在接下来的几个月,Meta预计将推出新功能、更长的上下文窗口、额外的模型大小和增强的性能,并会分享 Llama

基于Ollama+AnythingLLM轻松打造本地大模型知识库
Ollama是开源工具,简化了在本地运行大型语言模型(ile优化模型运行,支持GPU使用和热加载。它轻量、易用,可在Mac和Linux上通过Docker快速部署。AnythingLLM是Mintple
Python小项目:利用tkinter开发测手速小游戏
这个小游戏使用Tkinter创建了一个简单的图形用户界面,用户点击“开始”按钮开始测试,然后点击“停止”按钮停止测试并显示反应时间。你可以根据需要进一步定制化游戏的界面和功能。
OpenKruise v1.6 版本解读:增强多域管理能力
OpenKruise 在 2024.3 发布了最新的 v1.6 版本(ChangeLog),本文对新版本的核心特性做整体介绍。
Python人工智能与机器学习
【4月更文挑战第11天】Python在AI和ML领域占主导地位,得益于其简洁语法、强大库支持和活跃社区。关键应用包括数据预处理(Pandas, NumPy)、模型训练(scikit-learn, Te
【专栏】Python在人工智能领域的应用现状、优势及未来趋势
【4月更文挑战第27天】本文探讨了Python在人工智能领域的应用现状、优势及未来趋势。Python作为数据科学、机器学习、深度学习和自然语言处理的首选语言,拥有丰富的库如NumPy、Pandas、T

如何快速提取出一个文件里面全部指定类型的文件的全部路径
该文介绍了如何使用一个工具进行文件批量复制。工具可以从百度网盘(提取码:qwu2)或蓝奏云(提取码:2r1z)下载。打开工具后切换到第五模块,使用Ctrl+5快捷键进入文件批量复制功能。点击“搜索添加
DataWorks参数是不是有问题?
DataWorksopenAPI --> UpdateFile --> 传参的这个 InputParameters 参数是不是有问题当前我发现1、通过【Api】去添加的输入参数界面显示
DataWorks这边的年月日应该取的业务日期,现在我想修改一下调度参数,之前的分区会自动改吗?
DataWorks这边的年月日应该取的业务日期但是我取成定时时间的年月日了现在我想修改一下调度参数之前的分区会自动改吗
请问一下dataworks可以统一调整所有的周期任务的脏数据设置吗?
请问一下dataworks可以统一调整所有的周期任务的脏数据设置吗我们现在要把所有脏数据的配置全部为不容忍脏数据还是说要one by one调整配置再发布
DataWorks有一个分表的全增量同步的任务,可以设置有些表的任务不进行增量同步吗?
DataWorks有一个分表的全增量同步的任务我有些表是之前的数据每天不会新增了但是我看这些表还是会定时运行增量同步可以设置有些表的任务不进行增量同步吗
DataWorks早上有一些定期任务一直是wait状态,申请不到资源,能帮忙看一下吗?
DataWorks早上有一些定期任务一直是wait状态申请不到资源卡在那里七八个小时了重新提交也不行能帮忙看一下吗
Java医院绩效考核系统源码B/S+avue+MySQL助力医院实现精细化管理
医院绩效考核系统目标是实现对科室、病区财务指标、客户指标、流程指标、成长指标的全面考核、分析,并与奖金分配、学科建设水平评价挂钩。
dataworks 在做数据同步得时候 不能制定源系统数据库得列 作为目标库得列是分区键吗?
dataworks 在做数据同步得时候 不能制定源系统数据库得列 作为目标库得列是分区键嘛 源是mysql 目标库是hive
DataWorks调度资源组与集成资源内部的实例 就不能搞成允许客户共用吗?
DataWorks调度资源组与集成资源内部的实例 就不能搞成允许客户共用 资源组内部实例应该可以允许客户共用的。因为又得出一笔服务器费用 。刚才讨论到这块 很烦。大哥们。希望改一下策略吧
dataworks是在数据开发->workflow->通用->shell节点里写吗?
dataworks里执行eascmd命令是在数据开发->workflow->通用->shell节点里写吗我运行eascmd找不到命令
DataWorks新建实时同步时,如果源数据的某一个字段为空时,怎么同步到目标字段?
DataWorks新建实时同步时,如果源数据的某一个字段为空时,怎么同步到目标字段如附件所示 Loghub1 是输入源数据,其中有个字段 fm ,这个字段有时候没有值,我想在没有值时,同步到 输出源
DataWorks中maxcompute分组count的结果 t1是什么原因?
DataWorks中maxcompute分组count的结果 t1和在t1基础上同样分组sum结果就不一致了是什么原因select a,b,count(distinct c) as cntfrom
DataWorks【数据质量】界面试跑规则报怎么处理?
DataWorks【数据质量】界面试跑规则报【The parameter is incorrect. getYunAccountAndAK is not exist in tenant server
[译][AI OpenAI-doc] 延迟优化
本指南涵盖了一系列核心原则,您可以应用这些原则来改善在各种LLM相关用例中的延迟。这些技术来自于与广泛的客户和开发人员在生产应用程序上的合作,因此无论您正在构建什么——从细粒度的工作流程到端到端的聊天
![[译][AI OpenAI-doc] 延迟优化](https://ucc.alicdn.com/tbo73ymmu5nmu_20240513_802c2d330d8f44d1bed5bdb43be55cba.png?x-oss-process=image/resize,h_160,m_lfit)
DataWorks之前数据集成都是公共资源的,现在给取消不让用了吗,只能单独花钱买独立的?
DataWorks之前数据集成都是公共资源的现在给取消不让用了吗只能单独花钱买独立的https://help.aliyun.com/zh/dataworks/product-overview/ann
DataWorks明明表结构复制过去的 怎么会字段个数不一样那 我还数了 一样多啊 这是什么问题?
DataWorks明明表结构复制过去的 怎么会字段个数不一样那 我还数了 一样多啊 这是什么问题这也是一一对应的
DataWorks使用partition.drop() 下载哪个库,下载partition的那个库?
DataWorks使用partition.drop() 下载哪个库下载partition的那个库就是当一张表的分区存在是我要去删除这个表的分区table.delete_partition(dtbiz
DataWorks想测一下某个节点的下游能不能正常运行,如何运行能,不想跑数据?
DataWorks想测一下某个节点的下游能不能正常运行如何运行能不想跑数据下游第一层的全部节点不是查看执行计划我想加个字短我想测试下下游会不会冲突不是查看执行计划我想加个字段我想测试下下游会不会冲突
DataWorks自动生成逻辑表,功能是在哪里啊?
DataWorks自动生成逻辑表功能是在哪里啊https://help.aliyun.com/zh/dataworks/use-cases/synchronize-data-from-tables-

