
阿里云开发者社区






大家在互动










综合
最新
有奖励
免费用

社区供稿 | FunASR 语音大模型在 Arm Neoverse 平台上的优化实践
Arm 架构的服务器通常具备低功耗的特性,能带来更优异的能效比。相比于传统的 x86 架构服务器,Arm 服务器在相同功耗下能够提供更高的性能。这对于大模型推理任务来说尤为重要,因为大模型通常需要大量
让你的文档从静态展示到一键部署可操作验证
通过函数计算的能力让阿里云的文档从静态展示升级为动态可操作验证,用户在文档中单击一键部署可快速完成代码的部署及测试。这一改变已在函数计算的活动沙龙中得到用户的认可。
一键生成视频!用 PAI-EAS 部署 AI 视频生成模型 SVD 工作流
本教程将带领大家免费领取阿里云PAI-EAS的免费试用资源,并且带领大家在 ComfyUI 环境下使用 SVD的模型,根据任何图片生成一个小短视频。
OpenKruise v1.6 版本解读:增强多域管理能力
OpenKruise 在 2024.3 发布了最新的 v1.6 版本(ChangeLog),本文对新版本的核心特性做整体介绍。
乘风问答官5月排位赛开启!
2024年5月起乘风问答官专属活动全新起航鼓励问答官们积极给予高质量的解答和参与讨论给社区带来更好的体验~2024年5月问答官专属每周积分活动、每月排位赛开启欢迎问答官们参与。 面对对象 所有乘风问
PAI-EAS 一键启动ComfyUI!SVD 图片一键生成视频 stable video diffusion 教程 SVD工作流
PAI-EAS 一键启动ComfyUI!SVD 图片一键生成视频 stable video diffusion 教程 SVD工作流

代码管理实践10讲
本书旨在为读者提供做好代码评审、分支、安全惯例的实践技巧。内容由阿里云云效代码团队编制,主要面向开发工程师、测试工程师和技术管理者,以提升整个开发过程中的代码质量和安全性。

表单新加了个字段A,历史数据要添加字段A的值问题
表单新加了个字段A历史数据要添加字段A的值管理页的批量修改这种方式是否是目前最好的方式了尝试过通过api接口的方式速度是快的但更新后只能在列表页看到字段A的数据详情页是看不到字段A的数据的。研究了下
Havenask进阶系列第4节:分词器开发
Havenask是阿里巴巴自主研发的大规模分布式搜索引擎,主要专注于智能搜索和海量数据实时检索,其核心能力广泛应用于阿里巴巴内部的众多业务,如淘宝、天猫商品搜索,盒马搜索,菜鸟物流订单实时检索等。并于


【云效流水线 Flow 测评】驾驭云海:五大场景下的云效Flow实战部署评测
云效是一款企业级持续集成和持续交付工具,提供免费、高可用的服务,集成阿里云多种服务,支持蓝绿、分批、金丝雀等发布策略。其亮点包括快速定位问题、节省维护成本、丰富的企业级特性及与团队协作的契合。基础版和
一文解析 ODPS SQL 任务优化方法原理
本文重点尝试从ODPS SQL的逻辑执行计划和Logview中的执行计划出发,分析日常数据研发过程中各种优化方法背后的原理,覆盖了部分调优方法的分析,从知道怎么优化,到为什么这样优化,以及还能怎样优化
10倍性能提升-SLS Prometheus 时序存储技术演进
本文将介绍近期SLS Prometheus存储引擎的技术更新,在兼容 PromQL 的基础上实现 10 倍以上的性能提升。同时技术升级带来的成本红利也将回馈给使用SLS 时序引擎的上万内外部客户。
一文熟悉PolarDB-PG 分区表核心特性
在 PolarDB-PG 数据库中,分区表 (Partitioned Table) 使您能够将非常大的表分解为更小且更易于管理的部分,这个部分称为分区 (Partition) 。 每个分区都是一个独立
Serverless 成本再优化:Knative 支持抢占式实例
Knative 是一款云原生、跨平台的开源 Serverless 应用编排框架,而抢占式实例是公有云中性价比较高的资源。Knative 与抢占式实例的结合可以进一步降低用户资源使用成本。本文介绍如何在
Serverless 应用引擎产品使用之在阿里函数计算中,使数据库和阿里云函数计算位于同一个内网中如何解决
阿里云Serverless 应用引擎(SAE)提供了完整的微服务应用生命周期管理能力,包括应用部署、服务治理、开发运维、资源管理等功能,并通过扩展功能支持多环境管理、API Gateway、事件驱动等
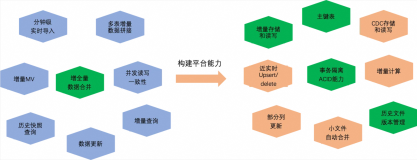
MaxCompute 近实时增全量处理一体化新架构和使用场景介绍
本文主要介绍基于 MaxCompute 的离线近实时一体化新架构如何来支持这些综合的业务场景,提供近实时增全量一体的数据存储和计算(Transaction Table2.0)解决方案。
国内独家|阿里云瑶池发布ClickHouse企业版:云原生Serverless新体验
全面升级为云原生架构,支持云原生按需弹性Serverless能力,解决了长期困扰用户的集群扩展效率和平滑性问题。

云原生数据仓库产品使用合集之在云数据仓库ADB中,GROUP BY操作中出现NULL值,如何解决
阿里云AnalyticDB提供了全面的数据导入、查询分析、数据管理、运维监控等功能,并通过扩展功能支持与AI平台集成、跨地域复制与联邦查询等高级应用场景,为企业构建实时、高效、可扩展的数据仓库解决方案
基于Ollama+AnythingLLM轻松打造本地大模型知识库
Ollama是开源工具,简化了在本地运行大型语言模型(ile优化模型运行,支持GPU使用和热加载。它轻量、易用,可在Mac和Linux上通过Docker快速部署。AnythingLLM是Mintple
数据管理DMS操作报错合集之阿里云DMS控制台上展示出了已经删除的数据库信息,如何解决
数据管理DMS(Data Management Service)是阿里云提供的数据库管理和运维服务,它支持多种数据库类型,包括RDS、PolarDB、MongoDB等。在使用DMS进行数据库操作时,可
在 ECS 上启动 minikube 失败的解决办法
在尝试启动Minikube时遇到初始化失败的错误,可能由于 kubelet 或系统配置问题。通过指定 Kubernetes 版本 (`--kubernetes-version=v1.23.8`) 和镜
阿里云ClickHouse企业版正式商业化,为开发者提供容灾性更好、性价比更高的实时数仓
2024年4月23日,阿里云联合 ClickHouse Inc. 成功举办了企业版商业化发布会。阿里云 ClickHouse 企业版是阿里云和 ClickHouse 原厂 ClickHouse. In
【Docker系列】Docker-核心概念/常用命令与项目部署实践
【4月更文挑战第1天】 Docker是容器化技术,打包应用及依赖,实现快速部署。核心概念包括镜像、容器和仓库。镜像是只读模板,容器是镜像运行实例,仓库用于存储和分发镜像。常用命令如`docker s
一文带你快速学会SpringBoot工程下MaBatis对数据的增删改查功能!
在SpringBoot项目中,已配置好Mybatis和Lombok,数据库tb_user有四条初始数据。需求是按ID删除用户。首先在UserMapper接口添加@Delete注解的删除方法,然后在单元
云原生数据仓库产品使用合集之ADB MySQL湖仓版和 StarRocks 的使用场景区别,或者 ADB 对比 StarRocks 的优劣势
阿里云AnalyticDB提供了全面的数据导入、查询分析、数据管理、运维监控等功能,并通过扩展功能支持与AI平台集成、跨地域复制与联邦查询等高级应用场景,为企业构建实时、高效、可扩展的数据仓库解决方案
Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker 避坑
在Ubuntu 18.04.6 WSL中学习Docker时遇到了“Cannot connect to the Docker daemon”错误。通过安装`service`并使用`sudo servic
阿里云服务器计算型c7与c8y、通用型g7与g8y、内存型r7与r8y区别及选择参考
在阿里云目前的活动中,除了轻量应用服务器和经济型e、通用算力型u1实例的云服务器之外,性能更高的云服务器实例规格有计算型c7与c8y、通用型g7与g8y、内存型r7与r8y,这些实例规格更适合企业级用
云原生数据仓库产品使用合集之ADB如何确保数据库的可用性
阿里云AnalyticDB提供了全面的数据导入、查询分析、数据管理、运维监控等功能,并通过扩展功能支持与AI平台集成、跨地域复制与联邦查询等高级应用场景,为企业构建实时、高效、可扩展的数据仓库解决方案
Kubernetes(K8s)与虚拟GPU(vGPU)协同:实现GPU资源的高效管理与利用
本文探讨了如何使用Kubernetes和虚拟GPU(vGPU)实现异构GPU的协同调度。Kubernetes是一个容器编排平台,通过设备插件、资源规格、调度器扩展和节点标签实现GPU资源管理。vGPU
云原生数据仓库产品使用合集之阿里云云原生数据仓库AnalyticDB PostgreSQL版的重分布时间主要取决的是什么
阿里云AnalyticDB提供了全面的数据导入、查询分析、数据管理、运维监控等功能,并通过扩展功能支持与AI平台集成、跨地域复制与联邦查询等高级应用场景,为企业构建实时、高效、可扩展的数据仓库解决方案
云原生数据仓库产品使用合集之在使用 ADB 进行数据分析处理时,出现分区倾斜的情况,如何解决
阿里云AnalyticDB提供了全面的数据导入、查询分析、数据管理、运维监控等功能,并通过扩展功能支持与AI平台集成、跨地域复制与联邦查询等高级应用场景,为企业构建实时、高效、可扩展的数据仓库解决方案
MaxCompute产品使用合集之大数据计算MaxCompute底层加速查询的原理是什么
MaxCompute作为一款全面的大数据处理平台,广泛应用于各类大数据分析、数据挖掘、BI及机器学习场景。掌握其核心功能、熟练操作流程、遵循最佳实践,可以帮助用户高效、安全地管理和利用海量数据。以下是
云原生数据仓库产品使用合集之如何使用ADB MySQL湖仓版声纹特征提取服务
阿里云AnalyticDB提供了全面的数据导入、查询分析、数据管理、运维监控等功能,并通过扩展功能支持与AI平台集成、跨地域复制与联邦查询等高级应用场景,为企业构建实时、高效、可扩展的数据仓库解决方案
阿里云购买云服务器、注册域名、备案及绑定图文教程参考
本文为大家介绍了2024年购买阿里云服务器和注册域名,绑定以及备案的教程,适合需要在阿里云购买云服务器、注册域名并备案的用户参考,新手用户可通过此文您了解在从购买云服务器到完成备案的流程。
clickhouse SQL优化
clickhouse 是 OLAP 数据库,但其具有独特的索引设计,所以如果拿 MySQL 或者其他 RDB 的优化经验来优化 clickhouse 可能得不到很好的效果,所以特此单独整理一篇文档,用
MVVM LiveData+DataBinding+Lifecycle+ViewModel架构
MVVM LiveData+DataBinding+Lifecycle+ViewModel架构
一次通过dump文件分析OutOfMemoryError异常代码定位过程
OutOfMemoryError是Java程序中常见的异常,通常出现在内存不足时,导致程序无法运行。借助MAT内存分析工具分析可能的内存泄漏代码问题定位。

活动预告 | 5月16日 Streaming Lakehouse Meetup · Online 与你相约!
5月16日 Streaming Lakehouse Meetup · Online 与你相约!

大数据计算MaxCompute昨天按照命令执行,有createinstance权限了,麻烦再看一下?
大数据计算MaxCompute昨天按照命令执行有createinstance权限了但是今天又报了自定义函数没有read的权限按照命令执行执行grant Read on project hung
大数据计算MaxCompute实时增量采集MYSQL binlog用的是streamx 的 吗?
大数据计算MaxCompute实时增量采集MYSQL binlog用的是streamx 的 streamx-pump我看gitee上的描述这个组件还在规划中
大数据计算MaxCompute文档上写是这样用的,为啥我得出的结果不一样呢?
大数据计算MaxCompute文档上写是这样用的为啥我得出的结果不一样呢odps.df.expr.core.Count 这个对象的文档有吗我不知道odps这个包有哪些对象方法属性
给出一个文档说把OSS作为数据源同步到MaxCompute,但是我操作的时候看着只能同步一个文件吗?
给出一个文档说把OSS作为数据源同步到MaxCompute但是我操作的时候看着只能同步一个文件吗https://help.aliyun.com/zh/dataworks/user-guide/oss
大数据计算MaxCompute边儿如何从 OSS 对象存储获取到上传的文件并进行相应的处理任务?
大数据计算MaxCompute目前有一个场景大致流程如下 用户通过前端界面上传 PDF/DOC 等文件文件会上传到 OSS 对象存储将用户上传的文件信息及上传记录保存到 MaxCompute 表中会
大数据计算MaxCompute odps中的Table有些什么方法呢?
大数据计算MaxCompute odps中的Table有些什么方法呢哪里有比较详细的文档Table object has no attribute get_count
应用研发平台EMAS中这个没有对应的kts的集成方式?
参考链接https://help.aliyun.com/document_detail/436887.html?spma2c4g.436889.0.0.1b8c6865TLFNei#section-
大数据计算MaxCompute设置分区表为长期存储,pt<日期 这个语法有计划考虑直接支持吗?
大数据计算MaxCompute设置分区表为长期存储pt<日期 这个语法有计划考虑直接支持吗一个一个写确实挺麻烦的ALTER TABLE mf_flink_upsert partition(d
大数据计算MaxCompute这个参数显示超过最大值了,这个在哪配置能提高参数的最大值吗?
大数据计算MaxCompute这个参数显示超过最大值了这个在哪配置能提高参数的最大值吗http://logview.odps.aliyun.com/logview/?hhttp://service.
大数据计算MaxCompute修改成任务责任人之后,分析师角色没有权限查询权限了怎么办?
大数据计算MaxCompute修改成任务责任人之后分析师角色没有权限查询权限了FAILED: ODPS-0420095: Access Denied - Authorization Failed [
大数据计算MaxCompute是不是代表用的是包年包月资源组的资源?
大数据计算MaxCompute包年包月队列的作业运维处查到了这个运行的作业是不是代表用的是包年包月资源组的资源还会有有按次收费的可能吗
承上启下:基于全域漏斗分析的主搜深度统一粗排
文章首先介绍了淘宝搜索的多阶段检索系统,包括召回、粗排和精排阶段。粗排模型的目标是优化商品的排序,以提高在召回集合中选择优质商品的能力。文章提到,粗排模型与精排模型的目标有所不同,粗排更注重腰部商品的

