

阿里云开发者社区






























综合
最新
有奖励
免费用
QwQ-32B一键部署!真正的0代码,0脚本,0门槛
阿里云发布的QwQ-32B模型通过强化学习显著提升了推理能力,核心指标达到DeepSeek-R1满血版水平。用户可通过阿里云系统运维管理(OOS)一键部署OpenWebUI+Ollama方案,轻松将Q
K8S异常诊断之俺的内存呢
本文讲述作者如何解决客户集群中出现的OOM(Out of Memory)和Pod驱逐问题。文章不仅详细记录了问题的发生背景、现象特征,还深入探讨了排查过程中的关键步骤和技术细节。

技术小白如何利用DeepSeek半小时开发微信小程序?
通过通义灵码的“AI程序员”功能,即使没有编程基础也能轻松创建小程序或网页。借助DeepSeek V3和R1满血版模型,用户只需用自然语言描述需求,就能自动生成代码并优化程序。例如,一个文科生仅通过描


一篇关于DeepSeek模型先进性的阅读理解
本文以DeepSeek模型为核心,探讨了其技术先进性、训练过程及行业影响。首先介绍DeepSeek的快速崛起及其对AI行业的颠覆作用。DeepSeek通过强化学习(RL)实现Time Scaling
【最佳实践系列】通过AppFlow,支持飞书机器人调用百炼应用
本文介绍了如何创建并配置飞书应用及机器人,主要包括三个步骤:1. 登录飞书开发者后台,创建企业自建应用并添加机器人卡片和API权限;2. 创建AppFlow连接流,配置飞书平台凭证和百炼鉴权凭证,发布
快速使用 DeepSeek-R1 满血版
DeepSeek是一款基于Transformer架构的先进大语言模型,以其强大的自然语言处理能力和高效的推理速度著称。近年来,DeepSeek不断迭代,从DeepSeek-V2到参数达6710亿的De

DeepSeek个人站点一键部署流程演示

Flink CDC任务从savepoint/checkpoints状态中恢复作业错误问题
flink CDC任务监听mysql数据。只要不是从savepoint/checkpoint中恢复都是能成功运行并监听数据的但是只要从savepoint/checkpoint中恢复作业就会报如下错误
人人懂AI之从机器学习到大模型
本书面向广大IT从业者,作者将尽可能通俗易懂的把机器学习、深度学习、神经网络等基本原理讲解清楚,并分享大语言模型、知识库等当下很火爆的AIGC应用,探讨大语言模型“知识茧房”问题及解法。期望本书能成为

基于阿里百炼的DeepSeek-R1满血版模型调用【零门槛保姆级2084小游戏开发实战】
本文介绍基于阿里百炼的DeepSeek-R1满血版模型调用,提供零门槛保姆级2048小游戏开发实战。文章分为三部分:定位与核心优势、实战部署操作指南、辅助实战开发。通过详细步骤和案例展示,帮助开发者高

自动化AutoTalk第十七期-基础设施自动化IaC实践之企业案例
企业视角下的自动化业务效率化 1、实操1:TF+Docker+Gitlab+GitlabRunner构建代码管理基础 2、实操2:资源遗产配置及应用

怎么让一张流程表单提交后,自动将这张表单的数据填入另一张流程表单并提交?
最开始是想要实现创建订单后自动生成生产工单的功能。想要创建一张带有好几个产品的订单后自动生成几个产品对应的几张不同的工单后面发现好像不好实现。现在把功能改为创建1个产品订单后能自动生成产品对应的工单
Serverless+AI 轻松玩转高频 AIGC 场景
本书旨在整理和介绍函数计算如何构建各类 AI 应用,以及如何基于函数计算结合其他云产品来部署各种 AI 大模型。主要内容包括:【构建个人专属AI助手】【AI生图】、【AI内容创作】、【打造多形态全天候

快来零门槛、即刻拥有 DeepSeek-R1 满血版
随着人工智能技术的发展,DeepSeek作为一款新兴推理模型,凭借强大的技术实力和广泛的应用场景崭露头角。本文基于阿里云提供的零门槛解决方案,评测DeepSeek的部署与使用。该方案支持多模态任务,涵
阿里云百炼已上线超强推理开源模型QwQ-32B,尺寸更小,性能比肩DeepSeek满血版
通义千问团队推出了320亿参数的QwQ-32B模型,通过大规模强化学习和多阶段训练,在数学、编程及通用能力上达到或超越了DeepSeek-R1等先进模型。QwQ-32B模型已在阿里云百炼上线,支持AP
指南:Claude 3.7 怎么样?国内如何使用Claude 3.7 Sonnet?
本文主要介绍了Claude 3.7 Sonnet模型的发布教你如何订阅使用Claude 3.7 Sonnect及其新功能,特别是Claude Code工具的推出。
基于 DIFY 的自动化数据分析实战
本文介绍如何使用DIFY搭建数据分析自动化流程,实现从输入需求到查询数据库、LLM分析再到可视化输出的全流程。基于经典的employees数据集和DIFY云端环境,通过LLM-SQL解析、SQL执行、
快速调用 Deepseek API!【超详细教程】
Deepseek 强大的功能,在本教程中,将指导您如何获取 DeepSeek API 密钥,并演示如何使用该密钥调用 DeepSeek API 以进行调试。
模型上新!来通义灵码体验 QwQ-32B 推理模型!
今天,阿里云发布并开源全新的推理模型通义千问QwQ-32B。通过大规模强化学习,千问QwQ-32B在数学、代码及通用能力上实现质的飞跃,整体性能比肩DeepSeek-R1。在保持强劲性能的同时,千问Q
Heygem:开源数字人克隆神器!1秒视频生成4K超高清AI形象,1080Ti显卡也能轻松跑
Heygem 是硅基智能推出的开源数字人模型,支持快速克隆形象和声音,30秒内完成克隆,60秒内生成4K超高清视频,适用于内容创作、直播、教育等场景。
进行GPU算力管理
本篇主要简单介绍了在AI时代由‘大参数、大数据、大算力’需求下,对GPU算力管理和分配带来的挑战。以及面对这些挑战,GPU算力需要从单卡算力管理、单机多卡算力管理、多机多卡算力管理等多个方面发展出来的
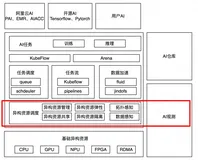
大模型推理主战场:通信协议的标配
DeepSeek加速了模型平权,大模型推理需求激增,性能提升主战场从训练转向推理。SSE(Server-Sent Events)和WebSocket成为大模型应用的标配网络通信协议。SSE适合服务器单
在ECS上使用百炼部署满血版DeepSeek R1
本文为您介绍如何在ECS实例上部署Open WebUI,并通过大模型服务平台百炼API调用DeepSeek-R1模型推理服务。帮助您快速体验满血版DeepSeek-R1模型。
真正的0代码,0脚本,0门槛,QwQ-32B一键部署!
阿里云最新发布的QwQ-32B模型通过强化学习显著提升了推理能力,在多个核心指标上达到DeepSeek-R1满血版水平,超越了DeepSeek-R1-Distill-Qwen-32B。用户可通过阿里云
从0到1彻底掌握Trae:手把手带你实战开发AI Chatbot,提升开发效率的必备指南!
Trae是字节跳动推出的一款免费的AI集成的开发环境,集成了Claude3.5与GPT-4o等主流AI模型,提供AI问答、智能代码生成、智能代码补全,多模态输入等功能。支持界面全中文化,为中文开发者提
Docker Desktop 4.38 安装与配置全流程指南(Windows平台)
Docker Desktop 是容器化应用开发与部署的一体化工具,支持本地创建、管理和运行 Docker 容器。4.38 版本新增 GPU 加速、WSL 2 性能优化和 Kubernetes 1.28
1分钟集成DeepSeek满血版!搭建智能运维助手
阿里云 AI 搜索开放平台面向企业及开发者提供丰富的组件化AI搜索服务,本文将重点介绍基于AI搜索开放平台内置的 DeepSeek-R1 系列大模型,如何搭建 Elasticsearch AI Ass
零门槛、百万token免费用,即刻拥有DeepSeek-R1满血版,还有实践落地调用场景等你来看
DeepSeek 是热门的推理模型,能在少量标注数据下显著提升推理能力,尤其擅长数学、代码和自然语言等复杂任务。本文涵盖四种部署方案,可以让你快速体验云上调用 DeepSeek-R1 满血版的 API
云上一键部署通义千问 QwQ-32B 模型,阿里云 PAI 最佳实践
3月6日阿里云发布并开源了全新推理模型通义千问 QwQ-32B,在一系列权威基准测试中,千问QwQ-32B模型表现异常出色,几乎完全超越了OpenAI-o1-mini,性能比肩Deepseek-R1,
三分钟让Dify接入Ollama部署的本地大模型!
本文介绍了如何运行 Ollama 并在 Dify 中接入 Ollama 模型。通过命令 `ollama run qwen2:0.5b` 启动 Ollama 服务,访问 `http://localhos
还在蹲Manus的邀请码?别等了!开源版Manus为你快速创建AI工位,给AI一台电脑,然后你就玩去吧!
OpenManus 是 MetaGPT 的开源 AI 平台,支持多语言模型和工具链,执行代码、处理文件等任务,具备实时反馈。OWL 基于 CAMEL-AI,支持角色分配、任务分解和记忆功能,实现高效任

OWL:告别繁琐任务!开源多智能体系统实现自动化协作,效率提升10倍
OWL 是基于 CAMEL-AI 框架开发的多智能体协作系统,通过智能体之间的动态交互实现高效的任务自动化,支持角色分配、任务分解和记忆功能,适用于代码生成、文档撰写、数据分析等多种场景。
Trae 接入 Claude 3.7:AI 编程工具界的“卷王”,完全免费使用!
Trae 是一款完全免费的AI编程工具,现已接入 Claude 3.7 模型,提供代码生成、调试等强大功能,支持多模态输入和上下文理解,用户可享受24小时高速服务,无需担心付费限制。Trae 支持多平
从零开始即刻拥有 DeepSeek-R1 满血版并使用 Dify 部署 AI 应用
本文介绍了如何使用阿里云提供的DeepSeek-R1大模型解决方案,通过Chatbox和Dify平台调用百炼API,实现稳定且高效的模型应用。首先,文章详细描述了如何通过Chatbox配置API并开始
本地部署DeepSeek模型
要在本地部署DeepSeek模型,需准备Linux(推荐Ubuntu 20.04+)或兼容的Windows/macOS环境,配备NVIDIA GPU(建议RTX 3060+)。安装Python 3.8
Browser Use:40.7K Star!一句话让AI完全接管浏览器!自动规划完成任务,多标签页同时管理
Browser Use 是一款专为大语言模型设计的智能浏览器自动化工具,支持多标签页管理、视觉识别、内容提取等功能,并能记录和重复执行特定动作,适用于多种应用场景。

CentOS下载ISO镜像的方法
访问CentOS官方网站(https://www.centos.org/download/),在“Downloads”页面找到ISO镜像下载链接,选择所需版本和架构(如x86_64)开始下载。Cent
DeepSeek一体机!飞天企业版上新“AI Stack”,支持DeepSeek满血版和Qwen单机部署!
飞天企业版上新“AI Stack”,支持DeepSeek满血版和Qwen单机部署!

QwQ-32B,支持Function Call的推理模型,深度思考Agent的时代来了!
近期,Qwen 发布了 QwQ-32B - 一个在许多基准测试中性能可与 DeepSeek-R1 相媲美的推理模型。
通义灵码对于数据结构逻辑处理异常
有如下代码 package com.qdm.datastruct.tree; /** * 表示链表中的一个节点。 * 每个节点包含一个整数数据和一个指向下一个节点的引用。 * 该类主要用于
XPipe:一款新型开源终端管理神器
XPipe 是一款创新的 Shell 连接中心和远程文件管理器,它能够让你从本地机器轻松访问整个服务器基础设施。这款工具运行在你已安装的命令行程序之上,无需在远程系统上进行任何额外配置。因此,如果你通

Chitu:清华核弹级开源!推理引擎3倍提速+50%省卡,国产芯片告别英伟达绑架
Chitu(赤兔)是清华大学与清程极智联合开源的高性能大模型推理引擎,支持多硬件适配,显著提升推理效率,适用于金融、医疗、交通等多个领域。

MT-TransformerEngine:国产训练核弹!FP8+算子融合黑科技,Transformer训练速度飙升300%
MT-TransformerEngine 是摩尔线程开源的高效训练与推理优化框架,专为 Transformer 模型设计,通过算子融合、并行加速等技术显著提升训练效率,支持 FP8 混合精度训练,适用

Open-LLM-VTuber:宅男福音!开源AI老婆离线版上线,实时语音+Live2D互动还会脸红心跳
Open-LLM-VTuber 是一个开源的跨平台语音交互 AI 伴侣项目,支持实时语音对话、视觉感知和生动的 Live2D 动态形象,完全离线运行,保护用户隐私。

【c++丨STL】map/multimap的使用
本文详细介绍了STL关联式容器中的`map`和`multimap`的使用方法。`map`基于红黑树实现,内部元素按键自动升序排列,存储键值对,支持通过键访问或修改值;而`multimap`允许存在重复
阿里云操作系统控制台:让集群管理变得轻松又高效
你是如何监控服务器状态的,一台直接看控制台,那我问你,几十台服务器组成的集群,有没有简单快捷的管理工具? 那我问你,现在有一款运维控制管理平台,可以一眼看到你的所有集群服务器的情况,要不要试一试。
SSL证书:网络安全的重要基石
在数字化时代,数据安全与隐私保护至关重要。SSL证书作为一种关键网络安全技术,通过加密和认证确保通信安全。本文从定义、工作原理、类型、应用场景到选择与维护全面解析SSL证书。其类型包括DV、OV和EV
鸿蒙开发:console日志输出
针对初学者而言,大家只需要掌握住日志打印即可,等到了鸿蒙应用开发的时候,还有一个鸿蒙原生的打印工具HiLog,到时,我们也会详细的去讲述,也会针对HiLog,封装一个通用的工具类。

PHP 日志系统的最佳搭档:一个 Go 写的远程日志收集服务
为了不再 SSH 上去翻日志,我写了个 Go 小脚本,用来接收远程日志。PHP 负责记录日志,Go 负责存储和展示,按天存储、支持 API 访问、可远程管理,终于能第一时间知道项目炸了。

【亲测有用】数据中台数仓查询中心能力演示
杭州奥零数据科技有限公司成立于2023年,专注于数据中台业务,维护开源项目AllData并提供商业版解决方案。AllData提供数据集成、存储、开发、治理及BI展示等一站式服务,支持AI大模型应用,助

小白避坑指南:国内用Colossal-AI微调DeepSeek 1.5B的完整踩坑记录(附镜像加速方案)
本文详细记录了使用Colossal-Ai对DeepSeek-Qwen模型进行微调的过程,包括模型下载、环境部署、数据集处理及代码实现等环节。重点介绍了LoRA低秩适配方法和Colossal-Ai分布式


从开发者视角找寻Postman的替代工具
作为一名软件开发者,我在API开发与测试中长期使用Postman。然而,其全英文界面、网络不稳定时的卡顿以及强制登录带来的数据隐私担忧,促使我寻找替代方案。最终,我发现Apipost这款专为中国用户设
前后端分离开发:如何高效调试API?有工具 vs 无工具全解析
在前后端分离开发中,API调试至关重要。本文探讨有无调试工具时如何高效调试API,重点分析Postman、Swagger等工具优势及无工具代码调试方法。通过实际场景如用户登录接口,对比两者特性。同时介
82.7K star!大气炫酷UI开源项目,超级火!
shadcn/ui 是一款基于 Radix UI 和 Tailwind CSS 构建的现代化 UI 组件库,专为追求设计品质与开发效率的开发者打造。不同于传统组件库,它提供完全可定制的组件代码模板,让
阿里云ModelScope平台的综合测评
ModelScope是阿里云推出的AI模型全生命周期管理平台,涵盖模型开发、训练、部署及评测全流程。其核心功能包括预训练模型库、一键式训练与部署、模型版本管理等。中文竞技场作为子平台,专注于模型性能对
生物光学叶绿素-a极化测量数据集研究
该数据集名为“Bio-optical chlorophyll-a polarization measurements”,由NASA/GSFC/SED/ESD/GCDC/OB.DAAC发布,旨在研究水体
基于阿里云的最低成本私有化部署DeepSeek
本方案详细介绍了基于阿里云的成本优化策略与部署架构,涵盖计算、存储、网络资源选型及优化技巧。核心内容包括:突发性能实例(如`ecs.g7.large`)结合预留实例券降低计算成本;高效云盘与ESSD
零成本快速搭建美观个人网站
这是一份详细的零成本个人网站搭建指南,采用 Hugo + PaperMod 主题生成静态网站并托管于 GitHub Pages,实现全自动部署与全球 CDN 加速。方案包含基础配置、内容添加、进阶美化
使用DeepSeek快速创建的个人网站
这是一份使用DeepSeek快速创建个人网站的10分钟指南。内容分为四个步骤:搭建基础架构(HTML框架)、设计核心内容区块(关于我、作品展示等)、快速配置样式(CSS美化页面)以及添加联系表单并部署
信息检索系统评估指标的层级分析:从单点精确度到整体性能度量
本文深入探讨了信息检索系统(如搜索引擎)的评估机制,从用户行为特征出发,设计了一系列量化指标以衡量搜索结果的相关性和有效性。核心内容包括精确度(Precision)、Precision@K(聚焦前K个

鸿蒙开发:ArkTs语言注释
关于注释,有一点需要注意,那就是,注释,不会被编译器或解释器执行,而本小节的重点并不是简单的教大家注释如何去写,而是在实际的项目中,我们能够真正的把注释投入到实际的开发中。

鸿蒙开发:权限管理之权限声明
本文,主要简单概述了为什么要有权限管理,以及权限管理的声明原则,这些都是基本的概念内容,大家做为了解即可,重要的是怎么声明权限,在什么位置声明权限,这一点需要掌握。

阿里云服务器是做什么的?
阿里云服务器是做什么的使用云服务器有什么用 云服务器ECShttps://www.aliyun.com/product/ecs轻量应用服务器https://www.aliyun.com/produc
阿里云服务器是什么?选ECS还是轻量应用服务器?
阿里云服务器是什么云服务器ECS和轻量应用服务器有啥区别 ECS云服务器https://www.aliyun.com/product/ecs轻量应用服务器https://www.aliyun.com
TokenSwift:90分钟生成10万Token!文本生成提速3倍,无损加速黑科技
TokenSwift 是北京通用人工智能研究院团队推出的超长文本生成加速框架,能在90分钟内生成10万Token的文本,速度提升3倍,生成质量无损,支持多种模型架构。

Evolving Agents:开源Agent革命!智能体动态进化框架上线,复杂任务一键协同搞定
Evolving Agents 是一个开源的AI Agent管理与进化框架,支持智能代理之间的通信与协作,能够根据语义理解需求动态进化,适用于文档处理、医疗保健、金融分析等多个领域。

Botgroup.chat:超有趣的开源 AI 聊天室!多个 AI 在线互怼,一键搭建你的专属 AI 社群
Botgroup.chat 是一款基于 React 和 Cloudflare Pages 的开源 AI 聊天应用,支持多个 AI 角色同时参与对话,提供类似群聊的交互体验。
MT-MegatronLM:国产训练框架逆袭!三合一并行+FP8黑科技,大模型训练效率暴涨200%
MT-MegatronLM 是摩尔线程推出的面向全功能 GPU 的开源混合并行训练框架,支持多种模型架构和高效混合并行训练,显著提升 GPU 集群的算力利用率。
MIDI-3D:单图秒变3D场景!40秒生成360度空间,多实例扩散黑科技
MIDI-3D 是一种先进的 AI 3D 场景生成技术,能够将单张图像快速转化为高保真度的 360 度 3D 场景,具有强大的全局感知能力和细节表现力,适用于游戏开发、虚拟现实、室内设计等多个领域。

APB:清华核弹级突破!长文本推理提速10倍,128K上下文碾压FlashAttention
APB 是清华大学等机构联合推出的分布式长上下文推理框架,通过稀疏注意力机制和序列并行推理方式,显著提升大模型处理长文本的效率,推理速度比 Flash Attention 快约 10 倍。

【Android】网络技术知识总结之WebView,HttpURLConnection,OKHttp,XML的pull解析方式
本文总结了Android中几种常用的网络技术,包括WebView、HttpURLConnection、OKHttp和XML的Pull解析方式。每种技术都有其独特的特点和适用场景。理解并熟练运用这些技术
Tomcat log日志解析
理解和解析Tomcat日志文件对于诊断和解决Web应用中的问题至关重要。通过分析 `catalina.out`、`localhost.log`、`localhost_access_log.*.txt`
Http自定义Header导致的跨域问题
在Web开发中,正确处理跨域问题是确保应用安全和性能的重要环节。通过在服务器端设置适当的CORS头信息,处理预检请求,并遵循最佳实践,可以有效解决自定义Header导致的跨域问题,提高应用的安全性和用
StringRedisTemplete使用
`StringRedisTemplate`是Spring Data Redis中非常实用的工具类,简化了与Redis交互的操作。通过本文的介绍,读者可以了解如何配置和使用 `StringRedisTe
Socket如何实现客户端和服务器间的通信
通过上述示例,展示了如何使用Python的Socket模块实现基本的客户端和服务器间的通信。Socket提供了一种简单且强大的方式来建立和管理网络连接,适用于各种网络编程应用。理解和掌握Socket编
基于BBO生物地理优化的三维路径规划算法MATLAB仿真
本程序基于BBO生物地理优化算法,实现三维空间路径规划的MATLAB仿真(测试版本:MATLAB2022A)。通过起点与终点坐标输入,算法可生成避障最优路径,并输出优化收敛曲线。BBO算法将路径视为栖
基于MPC在线优化的有效集法位置控制器simulink建模与仿真
本课题研究模型预测控制(MPC),一种基于模型的优化控制方法,可处理系统动态特性、输入输出约束及不确定性。通过Simulink实现MPC在线优化的有效集法位置控制器建模与仿真,并与RCNC控制器对比。
算法系列之回溯算法求解数独及所有可能解
数独求解的核心算法是回溯算法。回溯算法是一种通过逐步构建解决方案并在遇到冲突时回退的算法。具体来说,我们尝试在空格中填入一个数字,然后递归地继续填充下一个空格。如果在某个步骤中发现无法继续填充,则回退

《AI算法训练困境求解:深挖鸿蒙系统资源优势》
鸿蒙系统作为面向万物互联的操作系统,其微内核架构与分布式软总线技术为AI算法训练提供了新路径。通过资源整合与动态调配,鸿蒙可优化数据处理、模型训练及优化阶段,显著提升效率。例如,在智能家居领域,借助鸿
《鸿蒙系统中人工智能驱动的智能助手:应用模式与未来航向》
在数字化时代,人工智能与操作系统的融合成为科技变革的核心力量。鸿蒙系统作为华为自主研发的分布式操作系统,为智能助手提供了广阔舞台。通过语音交互、多模态融合、场景感知与跨设备协同,智能助手实现了便捷操控






