

阿里云开发者社区






























综合
最新
有奖励
免费用
QwQ-32B一键部署!真正的0代码,0脚本,0门槛
阿里云发布的QwQ-32B模型通过强化学习显著提升了推理能力,核心指标达到DeepSeek-R1满血版水平。用户可通过阿里云系统运维管理(OOS)一键部署OpenWebUI+Ollama方案,轻松将Q
K8S异常诊断之俺的内存呢
本文讲述作者如何解决客户集群中出现的OOM(Out of Memory)和Pod驱逐问题。文章不仅详细记录了问题的发生背景、现象特征,还深入探讨了排查过程中的关键步骤和技术细节。

技术小白如何利用DeepSeek半小时开发微信小程序?
通过通义灵码的“AI程序员”功能,即使没有编程基础也能轻松创建小程序或网页。借助DeepSeek V3和R1满血版模型,用户只需用自然语言描述需求,就能自动生成代码并优化程序。例如,一个文科生仅通过描


一篇关于DeepSeek模型先进性的阅读理解
本文以DeepSeek模型为核心,探讨了其技术先进性、训练过程及行业影响。首先介绍DeepSeek的快速崛起及其对AI行业的颠覆作用。DeepSeek通过强化学习(RL)实现Time Scaling
【最佳实践系列】通过AppFlow,支持飞书机器人调用百炼应用
本文介绍了如何创建并配置飞书应用及机器人,主要包括三个步骤:1. 登录飞书开发者后台,创建企业自建应用并添加机器人卡片和API权限;2. 创建AppFlow连接流,配置飞书平台凭证和百炼鉴权凭证,发布
DeepSeek个人站点一键部署流程演示

阿里云百炼已上线超强推理开源模型QwQ-32B,尺寸更小,性能比肩DeepSeek满血版
通义千问团队推出了320亿参数的QwQ-32B模型,通过大规模强化学习和多阶段训练,在数学、编程及通用能力上达到或超越了DeepSeek-R1等先进模型。QwQ-32B模型已在阿里云百炼上线,支持AP
Flink CDC任务从savepoint/checkpoints状态中恢复作业错误问题
flink CDC任务监听mysql数据。只要不是从savepoint/checkpoint中恢复都是能成功运行并监听数据的但是只要从savepoint/checkpoint中恢复作业就会报如下错误
人人懂AI之从机器学习到大模型
本书面向广大IT从业者,作者将尽可能通俗易懂的把机器学习、深度学习、神经网络等基本原理讲解清楚,并分享大语言模型、知识库等当下很火爆的AIGC应用,探讨大语言模型“知识茧房”问题及解法。期望本书能成为

Manus:或将成为AI Agent领域的标杆
随着人工智能技术的飞速发展,AI Agent(智能体)作为人工智能领域的重要分支,正逐渐从概念走向现实,并在各行各业展现出巨大的应用潜力。在众多AI Agent产品中,Manus以其独特的技术优势和市
自动化AutoTalk第十七期-基础设施自动化IaC实践之企业案例
企业视角下的自动化业务效率化 1、实操1:TF+Docker+Gitlab+GitlabRunner构建代码管理基础 2、实操2:资源遗产配置及应用

lmstudio拉起qwq-32b-q3_k_m.gguf模型报错?
我在modelscope下载了qwq-32b-q3_k_m.gguf模型用lmstudio拉起后发现prompt配置里的模版jinja报错解析 Jinja 模板失败: Parser Error: E
Serverless+AI 轻松玩转高频 AIGC 场景
本书旨在整理和介绍函数计算如何构建各类 AI 应用,以及如何基于函数计算结合其他云产品来部署各种 AI 大模型。主要内容包括:【构建个人专属AI助手】【AI生图】、【AI内容创作】、【打造多形态全天候

VMware Workstation 17.6.3 发布下载,现在完全免费无论个人还是商业用途
VMware Workstation 17.6.3 发布下载,现在完全免费无论个人还是商业用途
真正的0代码,0脚本,0门槛,QwQ-32B一键部署!
阿里云最新发布的QwQ-32B模型通过强化学习显著提升了推理能力,在多个核心指标上达到DeepSeek-R1满血版水平,超越了DeepSeek-R1-Distill-Qwen-32B。用户可通过阿里云
本地部署DeepSeek模型技术指南
DeepSeek模型是一种先进的深度学习模型,广泛应用于自然语言处理等领域。本文详细指导如何在本地部署DeepSeek模型,涵盖环境准备(硬件和软件要求、依赖库安装)、模型下载与配置、部署(创建Fla
高效部署通义万相Wan2.1:ComfyUI文生/图生视频实战,工作流直取!
通义万相Wan2.1开源不到一周,已登顶HuggingFace Model 和 Space 榜双榜首,在HuggingFace和ModelScope平台的累计下载量突破100万次,社区热度持续攀升!为
快速调用 Deepseek API!【超详细教程】
Deepseek 强大的功能,在本教程中,将指导您如何获取 DeepSeek API 密钥,并演示如何使用该密钥调用 DeepSeek API 以进行调试。
基于 DIFY 的自动化数据分析实战
本文介绍如何使用DIFY搭建数据分析自动化流程,实现从输入需求到查询数据库、LLM分析再到可视化输出的全流程。基于经典的employees数据集和DIFY云端环境,通过LLM-SQL解析、SQL执行、
Docker Desktop 4.38 安装与配置全流程指南(Windows平台)
Docker Desktop 是容器化应用开发与部署的一体化工具,支持本地创建、管理和运行 Docker 容器。4.38 版本新增 GPU 加速、WSL 2 性能优化和 Kubernetes 1.28
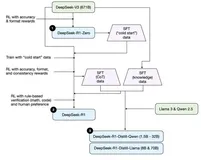
使用A10单卡24G复现DeepSeek R1强化学习过程
本文描述DeepSeek的三个模型的学习过程,其中DeepSeek-R1-Zero模型所涉及的强化学习算法,是DeepSeek最核心的部分之一会重点展示。
在ECS上使用百炼部署满血版DeepSeek R1
本文为您介绍如何在ECS实例上部署Open WebUI,并通过大模型服务平台百炼API调用DeepSeek-R1模型推理服务。帮助您快速体验满血版DeepSeek-R1模型。
零门槛、百万token免费用,即刻拥有DeepSeek-R1满血版,还有实践落地调用场景等你来看
DeepSeek 是热门的推理模型,能在少量标注数据下显著提升推理能力,尤其擅长数学、代码和自然语言等复杂任务。本文涵盖四种部署方案,可以让你快速体验云上调用 DeepSeek-R1 满血版的 API
从0到1彻底掌握Trae:手把手带你实战开发AI Chatbot,提升开发效率的必备指南!
Trae是字节跳动推出的一款免费的AI集成的开发环境,集成了Claude3.5与GPT-4o等主流AI模型,提供AI问答、智能代码生成、智能代码补全,多模态输入等功能。支持界面全中文化,为中文开发者提
还在蹲Manus的邀请码?别等了!开源版Manus为你快速创建AI工位,给AI一台电脑,然后你就玩去吧!
OpenManus 是 MetaGPT 的开源 AI 平台,支持多语言模型和工具链,执行代码、处理文件等任务,具备实时反馈。OWL 基于 CAMEL-AI,支持角色分配、任务分解和记忆功能,实现高效任

云上一键部署通义千问 QwQ-32B 模型,阿里云 PAI 最佳实践
3月6日阿里云发布并开源了全新推理模型通义千问 QwQ-32B,在一系列权威基准测试中,千问QwQ-32B模型表现异常出色,几乎完全超越了OpenAI-o1-mini,性能比肩Deepseek-R1,
进行GPU算力管理
本篇主要简单介绍了在AI时代由‘大参数、大数据、大算力’需求下,对GPU算力管理和分配带来的挑战。以及面对这些挑战,GPU算力需要从单卡算力管理、单机多卡算力管理、多机多卡算力管理等多个方面发展出来的
本地部署DeepSeek模型
要在本地部署DeepSeek模型,需准备Linux(推荐Ubuntu 20.04+)或兼容的Windows/macOS环境,配备NVIDIA GPU(建议RTX 3060+)。安装Python 3.8
大模型推理主战场:通信协议的标配
DeepSeek加速了模型平权,大模型推理需求激增,性能提升主战场从训练转向推理。SSE(Server-Sent Events)和WebSocket成为大模型应用的标配网络通信协议。SSE适合服务器单
Heygem:开源数字人克隆神器!1秒视频生成4K超高清AI形象,1080Ti显卡也能轻松跑
Heygem 是硅基智能推出的开源数字人模型,支持快速克隆形象和声音,30秒内完成克隆,60秒内生成4K超高清视频,适用于内容创作、直播、教育等场景。
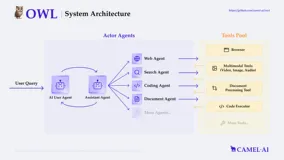
OWL:告别繁琐任务!开源多智能体系统实现自动化协作,效率提升10倍
OWL 是基于 CAMEL-AI 框架开发的多智能体协作系统,通过智能体之间的动态交互实现高效的任务自动化,支持角色分配、任务分解和记忆功能,适用于代码生成、文档撰写、数据分析等多种场景。
三分钟让Dify接入Ollama部署的本地大模型!
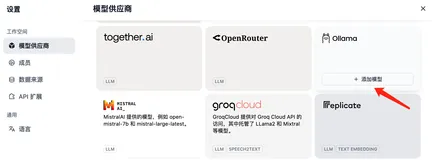
本文介绍了如何运行 Ollama 并在 Dify 中接入 Ollama 模型。通过命令 `ollama run qwen2:0.5b` 启动 Ollama 服务,访问 `http://localhos
1分钟集成DeepSeek满血版!搭建智能运维助手
阿里云 AI 搜索开放平台面向企业及开发者提供丰富的组件化AI搜索服务,本文将重点介绍基于AI搜索开放平台内置的 DeepSeek-R1 系列大模型,如何搭建 Elasticsearch AI Ass
从零开始即刻拥有 DeepSeek-R1 满血版并使用 Dify 部署 AI 应用
本文介绍了如何使用阿里云提供的DeepSeek-R1大模型解决方案,通过Chatbox和Dify平台调用百炼API,实现稳定且高效的模型应用。首先,文章详细描述了如何通过Chatbox配置API并开始
Trae 接入 Claude 3.7:AI 编程工具界的“卷王”,完全免费使用!
Trae 是一款完全免费的AI编程工具,现已接入 Claude 3.7 模型,提供代码生成、调试等强大功能,支持多模态输入和上下文理解,用户可享受24小时高速服务,无需担心付费限制。Trae 支持多平
VMware ESXi 6.7 U3v (ESXi670-202503001.zip) 下载
VMware ESXi 6.7 U3v 是一款专为服务器虚拟化设计的裸机 Hypervisor,提供高效、可靠的硬件资源管理。它支持更高的硬件利用率、增强的安全性和简化的 IT 管理,帮助企业降低运营

WhisperChain:开源 AI 实时语音转文字工具!自动消噪优化文本,效率翻倍
WhisperChain 是一款基于 Whisper.cpp 和 LangChain 的开源语音识别工具,能够实时将语音转换为文本,并自动清理和优化文本内容,适用于会议记录、写作辅助等多种场景。
深度评测 | 仅用3分钟,百炼调用满血版 Deepseek-r1 API,百万Token免费用,简直不要太爽。
仅用3分钟,百炼调用满血版Deepseek-r1 API,享受百万免费Token。阿里云提供零门槛、快速部署的解决方案,支持云控制台和Cloud Shell两种方式,操作简便。Deepseek-r1满

小鱼深度评测 | 通义灵码2.0,不仅可跨语言编码,自动生成单元测试,更炸裂的是集成DeepSeek模型且免费使用,太炸裂了。
小鱼深度评测 | 通义灵码2.0,不仅可跨语言编码,自动生成单元测试,更炸裂的是集成DeepSeek模型且免费使用,太炸裂了。

【赵渝强老师】达梦数据库的目录结构
本文介绍了达梦数据库(DM 8)安装成功后的目录结构查看方法,通过Linux的`tree`命令展示各目录功能,如`bin`存放可执行文件、`data`为数据库实例目录等。还提供了视频讲解及`data`
无需登录+离线调试,Apipost完胜Apifox?
在API调试工具领域,强制登录与离线支持的优劣一直备受关注。本文以Apipost和Apifox为例,通过三组实验对比两者在快速调试、断网环境及敏感接口调试中的表现。Apipost凭借游客模式和本地存储

warning: You ran ‘git add’ with neither ‘-A (—all)’ or ‘—ignore-removal’,报错如何解决 git报错 ‘git add —ignore-removal <pathspec>优雅草卓伊凡
warning: You ran ‘git add’ with neither ‘-A (—all)’ or ‘—ignore-removal’,报错如何解决 git报错 ‘git add —igno

鸿蒙开发:了解应用级配置信息
在实际的开发中,如果有共用的资源,建议大家都放到AppScope目录下,对于一些应用级别的信息,比如应用的名字,还有应用的图标,虽然说在Moulde下也可以配置,但是为了更方便的管理,这里比较推荐以A

Docker——阿里云服务器利用docker搭建redis集群
本文详细记录了使用Docker搭建Redis集群的过程,包括检查Docker和Docker Compose的安装、创建Redis配置文件、编写`docker-compose.yml`文件、启动Redi
【YashanDB知识库】由于hist_head$中analyze time小于tab$中analyze time导致的sql语句执行慢
【YashanDB知识库】由于hist_head$中analyze time小于tab$中analyze time导致的sql语句执行慢
【YashanDB知识库】yashandb执行包含带oracle dblink表的sql时性能差
【YashanDB知识库】yashandb执行包含带oracle dblink表的sql时性能差
【YashanDB知识库】多表更新报错 YAS-04345 multi-table update is not supported
【YashanDB知识库】多表更新报错 YAS-04345 multi-table update is not supported
【YashanDB知识库】如何配置jdbc驱动使getDatabaseProductName()返回Oracle
【YashanDB知识库】如何配置jdbc驱动使getDatabaseProductName()返回Oracle
【YashanDB知识库】YAS-02025 no free space in virtual memory pool
【YashanDB知识库】YAS-02025 no free space in virtual memory pool
依托自研力量,给共享集群存储服务一个优选
YashanDB共享集群有三大关键组件,崖山集群服务(YCS)、崖山集群文件系统(YFS)、DB组件。上一篇共享集群系列文章《为何共享集群的高可用能力被频频称赞,它的机制有何不同?》深入解析了关键组件
运维实战来了!如何构建适用于YashanDB的Prometheus Exporter
今天分享的是构建YashanDB Exporter的核心设计理念和关键方法,希望也能为你的运维实战加分!
基于责任链与策略模式的轻量级PHP日志库设计
项目日志乱成一团,bug 时好时坏,服务器问题难以复现?我写了个 PHP 日志系统,第一时间发现问题,避免跑路。实现了责任链模式+策略模式,让日志存储更灵活,支持多种输出方式。
【YashanDB数据库】YAS-02143 invalid username/password, login denied
YAS-02143 invalid username/password, login denied
【YashanDB数据库】YAS-02079 archive log mode must be enabled when database is in replication mode
YAS-02079 archive log mode must be enabled when database is in replication mode
【YashanDB数据库】YAS-02032 column type is incompatible with referenced column type
YAS-02032 column type is incompatible with referenced column type
【YashanDB数据库】YAS-02024 lock wait timeout, wait time 0 milliseconds
YAS-02024 lock wait timeout, wait time 0 milliseconds
【YashanDB数据库】大事务回滚导致其他操作无法执行,报错YAS-02016 no free undo blocks
大事务回滚导致其他操作无法执行,报错YAS-02016 no free undo blocks






