

阿里云开发者社区



































综合
最新
有奖励
免费用
大模型无缝切换,QwQ-32B和DeepSeek-R1 全都要
通义千问最新推出的QwQ-32B推理模型,拥有320亿参数,性能媲美DeepSeek-R1(6710亿参数)。QwQ-32B支持在小型移动设备上本地运行,并可将企业大模型API调用成本降低90%以上。

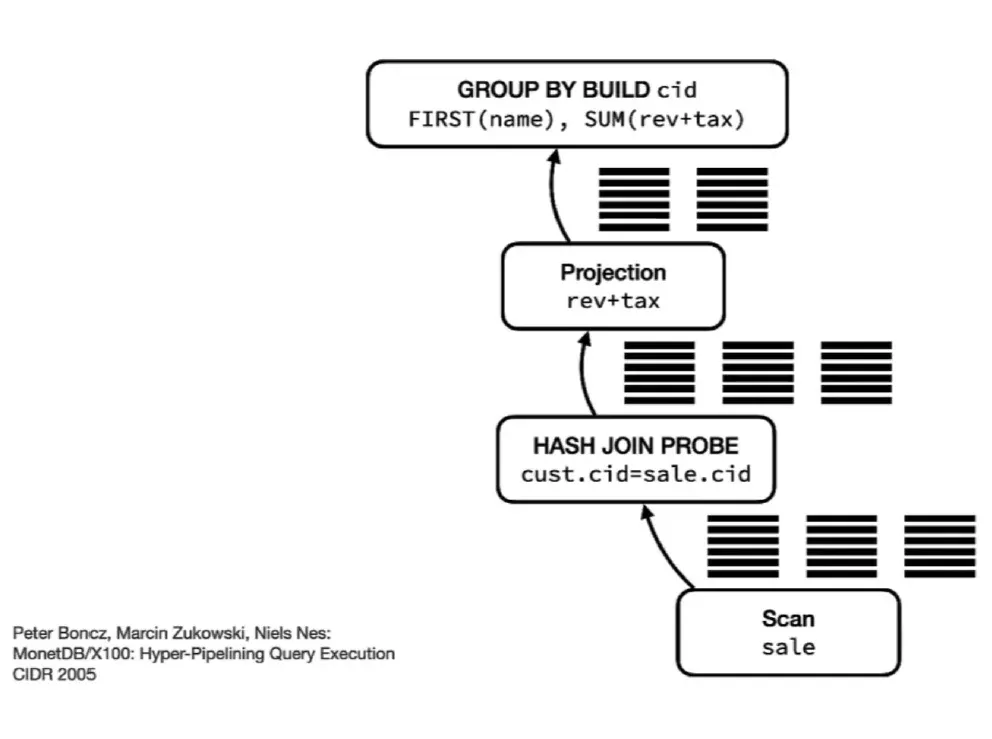
使用A10单卡24G复现DeepSeek R1强化学习过程
本文描述DeepSeek的三个模型的学习过程,其中DeepSeek-R1-Zero模型所涉及的强化学习算法,是DeepSeek最核心的部分之一会重点展示。
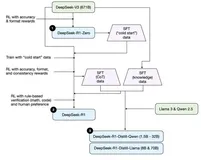
一篇关于DeepSeek模型先进性的阅读理解
本文以DeepSeek模型为核心,探讨了其技术先进性、训练过程及行业影响。首先介绍DeepSeek的快速崛起及其对AI行业的颠覆作用。DeepSeek通过强化学习(RL)实现Time Scaling
云产品评测|告别传统运维挑战!阿里云OS控制台引领智能管理新时代
阿里云OS控制台是专为运维人员设计的高效管理工具,旨在提升用户体验和简化操作流程。它不仅集成了OS Copilot等智能助手,还提供了系统诊断、订阅管理和AI组件等功能,支持API、SDK、CLI等多
满血上阵,DeepSeek x 低代码创造专属知识空间
本文介绍了如何结合阿里云百炼和魔笔平台,快速构建一个智能化的专属知识空间。通过利用DeepSeek R1等先进推理模型,实现高效的知识管理和智能问答系统。 5. **未来扩展**:探讨多租户隔离、终端
《AI 剧本生成与动画创作》解决方案测评
这篇评测介绍了2025年首个AI剧本生成与动画创作解决方案。该方案结合阿里云的函数计算、对象存储OSS和百炼大模型服务,通过API调用实现剧本生成、语音合成及字幕生成等功能,适用于教育、短视频、游戏娱
AI性能极致体验:通过阿里云平台高效调用满血版DeepSeek-R1模型
DeepSeek是近期热门的开源大语言模型(LLM),以其强大的训练和推理能力备受关注。然而,随着用户需求的增长,其官网在高并发和大数据处理场景下常面临服务不稳定的问题。本文将深度测评通过阿里云平台调
通义灵码2.0 - AI 程序员: AI 编程新时代的卓越助力
通义灵码是一款强大的AI编程助手,尤其在单元测试自动生成方面表现出色。它通过简化操作流程,快速生成覆盖广泛、质量较高的测试用例,支持直接编译与运行,显著提升开发效率。相比人工编写,通义灵码能大幅缩短时
DeepSeek个人站点一键部署流程演示

阿里云短信服务使用过程中,电信和联通都能正常接收到验证码,移动却接收不到,已经一个多月了
失败原因显示为签名实名制报备问题。应运营商要求各短信发送通道需完成对应签名的实名制报备。(IB:0310)给出的建议是请检查您使用的签名是否关联真实企业实名制资质信息若未关联请尽快提交资质审核并关联
人人懂AI之从机器学习到大模型
本书面向广大IT从业者,作者将尽可能通俗易懂的把机器学习、深度学习、神经网络等基本原理讲解清楚,并分享大语言模型、知识库等当下很火爆的AIGC应用,探讨大语言模型“知识茧房”问题及解法。期望本书能成为

基于 DIFY 的自动化数据分析实战
本文介绍如何使用DIFY搭建数据分析自动化流程,实现从输入需求到查询数据库、LLM分析再到可视化输出的全流程。基于经典的employees数据集和DIFY云端环境,通过LLM-SQL解析、SQL执行、
PolarDB for Al:打造SQL驱动的一体化数据智能基础应用
本视频为Data+AI Workshop(深圳站)活动分享,主要内容介绍聚焦SQL驱动理念,讲师深入讲解PolarDB for AI如何搭建一体化数据智能基础应用,剖析该技术在数据智能领域从数据处理到

操作系统停服应用指南
随着信息技术的快速发展,操作系统作为支撑应用程序和服务运行的基础层,承担着至关重要的角色。然而,操作系统和其他软件系统类似,都将经历生命周期的不同阶段,包括引入、增长、成熟和最终的停服。处于生命周期的

时间序列异常检测:MSET-SPRT组合方法的原理和Python代码实现
MSET-SPRT是一种结合多元状态估计技术(MSET)与序贯概率比检验(SPRT)的混合框架,专为高维度、强关联数据流的异常检测设计。MSET通过历史数据建模估计系统预期状态,SPRT基于统计推断判

阿里云百炼已上线超强推理开源模型QwQ-32B,尺寸更小,性能比肩DeepSeek满血版
通义千问团队推出了320亿参数的QwQ-32B模型,通过大规模强化学习和多阶段训练,在数学、编程及通用能力上达到或超越了DeepSeek-R1等先进模型。QwQ-32B模型已在阿里云百炼上线,支持AP
对话即服务:Spring Boot整合MCP让你的CRUD系统秒变AI助手
本文介绍了如何通过Model Context Protocol (MCP) 协议将传统Spring Boot服务改造为支持AI交互的智能系统。MCP作为“万能适配器”,让AI以统一方式与多种服务和数据
通义灵码 Rules 来了:个性化代码生成,对抗模型幻觉
通义灵码又上新外挂啦,Project Rules来了。当模型生成代码不精准,试下通义灵码 Rules,对抗模型幻觉,硬控 AI 根据你的代码风格和偏好生成代码和回复。

从零开始教你打造一个MCP客户端
Anthropic开源了一套MCP协议,它为连接AI系统与数据源提供了一个通用的、开放的标准,用单一协议取代了碎片化的集成方式。本文教你从零打造一个MCP客户端。
高效部署通义万相Wan2.1:ComfyUI文生/图生视频实战,工作流直取!
通义万相Wan2.1开源不到一周,已登顶HuggingFace Model 和 Space 榜双榜首,在HuggingFace和ModelScope平台的累计下载量突破100万次,社区热度持续攀升!为
剖析跨域问题始末及其解决方案——前端必备交叉知识(一)
跨域问题是前端开发中的常见挑战,了解并掌握不同的跨域解决方案能帮助你更高效地进行开发工作。本文对同源策略、跨域以及解决跨域的三种方案: CORS、JSONP、代理等跨域技术进行了介绍。选择合适的跨域解
pdf-craft:PDF秒转Markdown/EPUB!接入DeepSeek轻松生成电子书,自动整理目录、注释和引文
pdf-craft是一款专注于处理扫描书籍PDF的开源工具,能精准提取正文内容并转换为Markdown/EPUB格式,通过AI算法解决跨页连贯性问题,是学术研究和电子书制作的利器。
指南:Grok中文版 _Grok 3 中文版本国内在线使用
Grok中文版都让用户能够不受限制地体验到最前沿的人工智能技术。通过这个平台,国内用户能够突破网络的束缚,尽情享受AI带来的便利与乐趣。
MCP 是什么?一文看懂模型上下文协议
MCP(模型上下文协议)由Anthropic于2024年推出,旨在解决AI大模型的数据滞后问题,通过连接第三方数据源提升回答的时效性和相关性。传统联网搜索依赖公开信息,难以满足行业内部或定制化需求。M
DeepSeek一体机!飞天企业版上新“AI Stack”,支持DeepSeek满血版和Qwen单机部署!
飞天企业版上新“AI Stack”,支持DeepSeek满血版和Qwen单机部署!
阿里开源多模态全能王 Qwen2.5-Omni:创新Thinker-Talker架构,全面超越Gemini-1.5-Pro等竞品
阿里开源Qwen2.5-Omni多模态大模型,支持文本、图像、音频和视频输入,具备实时语音合成与流式响应能力,在OmniBench等基准测试中全面超越Gemini-1.5-Pro等竞品,提供免费商用授

什么是Token
Token是一种用于身份验证和授权的凭证,广泛应用于云计算、API调用、实时音视频通信等场景。它通过加密算法生成,确保请求合法性与服务安全性。Token的核心作用包括身份验证、权限控制、安全保障和无状
CentOS下载ISO镜像的方法
访问CentOS官方网站(https://www.centos.org/download/),在“Downloads”页面找到ISO镜像下载链接,选择所需版本和架构(如x86_64)开始下载。Cent
纯干货!如何用Cursor+宜搭,3天完成三周开发量(附超详细视频教学)
Cursor是热门代码编辑器之一,通过与宜搭(Yida)结合,提供了强大的低代码页面和自定义组件生成能力。方案利用Claude模型的代码生成能力及MCP支持,大幅提升开发效率。开发者可通过Cursor
Qwen2.5-VL-32B: 更聪明、更轻量!
年前,阿里通义千问团队推出了 Qwen2.5-VL 系列模型,获得了社区的广泛关注和积极反馈。在 Qwen2.5-VL 系列的基础上,研究团队使用强化学习持续优化模型,并使用 Apache 2.0 协
MCP+Hologres+LLM搭建数据分析Agent
本文探讨了LLM大模型在数据分析领域的挑战,并介绍了Hologres结合MCP协议和LLM搭建数据分析Agent的解决方案。传统LLM存在实时数据接入能力不足、上下文记忆短等问题,而Hologres通
Docker Desktop 4.38 安装与配置全流程指南(Windows平台)
Docker Desktop 是容器化应用开发与部署的一体化工具,支持本地创建、管理和运行 Docker 容器。4.38 版本新增 GPU 加速、WSL 2 性能优化和 Kubernetes 1.28
谷歌AI Gemini 2.0 pro国内使用教程, 2025最新版!
在 2025 年 2 月初,谷歌又推出了 Gemini 2.0 Pro 系列模型,进一步巩固了其在 AI 领域的领先地位,同时也正式向外界宣告,我们进入了 Gemini 2.0 时代
怎么让一张流程表单提交后,自动将这张表单的数据填入另一张流程表单并提交?
最开始是想要实现创建订单后自动生成生产工单的功能。想要创建一张带有好几个产品的订单后自动生成几个产品对应的几张不同的工单后面发现好像不好实现。现在把功能改为创建1个产品订单后能自动生成产品对应的工单
不写一行代码,用MCP+魔搭API-Inference 搭建一个本地数据助手! 附所有工具和清单
还在为大模型开发的复杂技术栈、框架不兼容和工具调用问题头疼吗?MCP(Model Context Protocol servers)来拯救你了!它用统一的技术栈、兼容主流框架和简化工具调用的方式,让大
Heygem:开源数字人克隆神器!1秒视频生成4K超高清AI形象,1080Ti显卡也能轻松跑
Heygem 是硅基智能推出的开源数字人模型,支持快速克隆形象和声音,30秒内完成克隆,60秒内生成4K超高清视频,适用于内容创作、直播、教育等场景。
RuoYi AI:1人搞定AI中台!开源全栈式AI开发平台,快速集成大模型+RAG+支付等模块
RuoYi AI 是一个全栈式 AI 开发平台,支持本地 RAG 方案,集成多种大语言模型和多媒体功能,适合企业和个人开发者快速搭建个性化 AI 应用。

指南:Claude 3.7 怎么样?国内如何使用Claude 3.7 Sonnet?
本文主要介绍了Claude 3.7 Sonnet模型的发布教你如何订阅使用Claude 3.7 Sonnect及其新功能,特别是Claude Code工具的推出。
FreeMQTT Plus: 一个新型 MQTT Broker 集群的实现
FreeMQTT Plus 是一款基于 MQTT 协议的高性能消息中间件,采用分布式架构解决单点瓶颈问题。其核心由 Nginx 负载均衡器、黑(A)节点(MQTT Broker)、白(B)节点(消息路
利用 AWS Signature:REST API 认证的安全指南
本文探讨了 AWS Signature 在保护 REST API 访问中的重要性,详解其工作原理,并提供 Java 和 Go 的实现示例。AWS Signature 通过加密技术确保请求安全,具备增强
如何快速搭建自己的个人网站?Hexo、VuePress 和 WordPress 大比拼!
晚枫和你聊聊程序员必备的个人网站!它是技术名片,能秀实力、记笔记、当博主、搞品牌。搭建工具有三种:Hexo简单快速,适合技术博客;VuePress功能丰富,可玩转动态交互;WordPress强大全面,
一个测试工程师的实战笔记:我是如何在Postman和Apipost之间做出选择的?
作为一名金融科技公司的测试负责人,每天需处理大量涉及加密验签的接口。从Postman到Apipost的转变,让我深刻体会到工具对效率的影响。Postman虽功能强大,但脚本复杂、学习成本高;而Apip
智谱AI新突破!GLM-Z1-Rumination:新一代沉思模型,推动AI助手进入"高智商+高自主"的新阶段
GLM-Z1-Rumination是智谱推出的新一代沉思模型,通过扩展强化学习训练实现长程推理能力,支持动态工具调用与自我验证机制,显著提升AI自主研究能力。

AI-ClothingTryOn:服装店老板连夜下架试衣间!基于Gemini开发的AI试衣应用,一键生成10种穿搭效果
AI-ClothingTryOn是基于Google Gemini技术的虚拟试衣应用,支持人物与服装照片智能合成,可生成多达10种试穿效果版本,并提供自定义提示词优化功能。

智谱推出深度思考模型 GLM-Z1-Air:推理速度相较DeepSeek-R1提升8倍,成本降低至1/30
GLM-Z1-Air是智谱公司基于GLM-4-Air-0414开发的深度思考模型,通过推理数据增强和对齐优化,在数理推理性能上达到顶尖水平,同时大幅提升推理效率并降低运行成本。

32B小模型竟能吊打百亿参数?GLM-4-Air-0414:智谱AutoGLM沉思背后的模型,智能体开发迎来新纪元
GLM-4-Air-0414是智谱公司推出的320亿参数开源基座模型,通过优化预训练数据和对齐策略,在工具调用、联网搜索和代码生成等智能体任务中展现出卓越性能。

Qlib:华尔街颤抖!微软开源金融AI量化投资神器,助力智能投研
Qlib是微软亚洲研究院推出的开源AI量化投资平台,提供从数据处理、模型训练到组合管理的全流程支持,内置高性能数据基础设施和多种机器学习模型。

Amodal3R:3D重建领域新突破!这个模型让残破文物完美还原,3D重建结果助力文物修复
Amodal3R是一种创新的条件式3D生成模型,通过掩码加权多头交叉注意力机制和遮挡感知层,能够从部分可见的2D图像中重建完整3D形态,仅用合成数据训练即可实现真实场景的高精度重建。

Neo-1:全球首个原子级生成式AI模型!这个AI模型把10年药物研发周期压缩到1个月
VantAI推出的Neo-1是全球首个统一分子生成与原子级结构预测的AI模型,采用潜在空间扩散技术,结合大规模训练和定制数据集,显著提升药物研发效率。

FinGPT:华尔街颤抖!用股价训练AI,开源金融大模型预测股价准确率碾压分析师,量化交易新利器
FinGPT是基于Transformer架构的开源金融大模型,通过RLHF技术和实时数据处理能力,支持情感分析、市场预测等核心功能,其LoRA微调技术大幅降低训练成本。

AutoGLM沉思:智谱AI推出首个能"边想边干"的自主智能体!深度研究+多模态交互,颠覆传统AI工作模式
AutoGLM沉思是由智谱AI推出的一款开创性AI智能体,它突破性地将深度研究能力与实际操作能力融为一体,实现了AI从被动响应到主动执行的跨越式发展。

Amazon Nova Act:网页操作全自动!亚马逊黑科技把浏览器变AI机器人,请假/订餐/写邮件一键搞定
Amazon Nova Act是亚马逊AGI实验室推出的通用AI代理系统,通过原子化分解网页操作任务并配合Playwright实现高可靠性浏览器自动化,其配套SDK支持开发者快速构建智能体应用原型。

Runway Gen-4:AI视频生成新纪元!高保真特效一键生成影视级内容
Runway Gen-4是新一代AI视频生成模型,通过参考图和文字指令即可生成具有物理真实感、叙事连贯性的高质量视频内容,支持与实拍素材无缝融合。

Linux读写锁源码分析
本文分析了读写锁的实现原理与应用场景,基于glibc 2.17源码。读写锁通过读引用计数、写线程ID、条件变量等实现,支持读优先(默认)和写优先模式。读优先时,写锁可能饥饿;写优先时,读线程需等待写锁
【Function App】如果一个拥有多个Function App的Plan遇见了High CPU问题? 如何方便定位是哪一个Function App引发的呢?
在Azure Function App测试中,若多个Function App共用同一App Service Plan资源,当出现High CPU问题时,由于Function App公开指标无法直接观测
Cpp网络编程Winsock API
本文详细介绍了使用Winsock API进行C++网络编程的过程,通过具体实例实现了一个基于TCP协议的C/S架构通信demo。文章从服务端与客户端两方面展开,涵盖网络库初始化、套接字创建、绑定IP与
Hi3DGen:2D照片秒变高精度模型,毛孔级细节完爆Blender!港中文×字节×清华联手打造3D生成黑科技
Hi3DGen是由香港中文大学、字节跳动和清华大学联合研发的高保真3D几何生成框架,通过法线图中间表示实现细节丰富的3D模型生成,其双阶段生成流程显著提升了几何保真度。

《深度探索:运用游标遍历数据库树形结构数据的艺术》
树形结构数据以层级化组织信息,广泛应用于文件系统、组织架构等领域。其复杂性在于节点间的父子关系和多层级嵌套,给数据处理带来挑战。游标作为数据库操作工具,通过逐行处理能力,可灵活遍历树形结构。其原理是基
《深度剖析:SQL中游标与临时表的数据处理对决》
在SQL数据处理中,游标与临时表是两种重要的工具。游标适合逐行处理复杂业务逻辑或顺序依赖的数据,但性能较低、资源消耗大;临时表擅长批量数据处理,可提高效率并实现数据隔离,但在动态数据处理和资源开销上存
《深度探秘:借助游标解锁SQL数据批量更新的高阶玩法》
在数据库管理中,数据批量更新是一项复杂且关键的任务。游标作为SQL中的强大工具,能够精准高效地处理大量数据。通过明确目标、初始化游标、逐行处理与更新、异常处理及事务管理等步骤,游标可实现精细化的数据操
《深度洞察:MySQL与Oracle中游标的性能分野》
游标是数据库中用于逐行处理数据的强大工具,在MySQL和Oracle中表现存在显著差异。本文从内存管理、锁机制、查询优化器及事务处理等方面分析两者区别:Oracle拥有更成熟的内存管理和复杂精细的锁机
《深度剖析SQL游标:复杂数据处理场景下的智慧抉择》
SQL游标是数据库中用于逐行处理复杂数据的有力工具,尤其在需要精细化操作的场景下(如数据关联分析、清理与审计),其独特价值得以充分体现。通过明确使用场景、优化性能、强化异常处理及事务管理,结合存储过程
RAG 调优指南:Spring AI Alibaba 模块化 RAG 原理与使用
通过遵循以上最佳实践,可以构建一个高效、可靠的 RAG 系统,为用户提供准确和专业的回答。这些实践涵盖了从文档处理到系统配置的各个方面,能够帮助开发者构建更好的 RAG 应用。
AReaL-boba:仅用200条数据复现32B模型效果!蚂蚁清华联手打造强化学习+数据蒸馏框架,7B模型数学推理碾压同级
AReaL-boba是蚂蚁技术研究院与清华大学联合推出的强化学习训练框架,通过集成SGLang推理框架和数据蒸馏技术,显著提升训练效率并降低资源消耗,其7B模型在数学推理任务中刷新同尺寸模型性能纪录。

OpenDeepSearch:搜索引擎革命!这个开源深度搜索工具让AI代理直接读懂网页,复杂问题一键拆解
OpenDeepSearch是基于开源推理模型的深度搜索工具,通过语义重排和多源整合优化检索效果,支持与AI代理无缝集成,提供快速和专业两种搜索模式。

HTTP代理:网页加速的隐形引擎
本文深入探讨HTTP代理在提升网页加载速度中的核心作用与技术原理。通过请求中转、协议优化及传输层加速,结合智能缓存、动态压缩、全球负载均衡和协议升级四大黑科技,实现显著性能提升。同时分析其潜在代价与挑
怎么实现实时无延迟的体育电竞动画直播
实时无延迟动画直播需关注技术方案、实现步骤与专业解决方案。技术上可选WebRTC(低至100-500ms延迟,互动性强)、低延迟HLS/CMAF(1-3秒延迟,兼容性好)和RTMP(传统协议,2-5秒
Chat2报表2图表!!业务管理系统智能化升级、满足创新需求的必备
作为技术管理者,我们团队曾以SQL+Java报表体系满足数据需求,但传统模式存在研发资源消耗大、响应周期长及缺乏自主分析工具三大痛点。近期体验的智能BI产品,借助AI技术显著优化了数据分析流程。通过“
AI的出现,让月入几万的程序员,要被AI取代了?
人工智能(AI)的快速发展对程序员的工作带来了挑战与机遇。AI在自动化代码生成、问题解决及效率提升方面表现出色,但程序员在复杂系统架构设计、创新思维和业务沟通上仍具不可替代的优势。AI可作为辅助工具提
5款知名度不高,但很好用的软件
本文推荐了5款小众但实用的软件工具:MouseInc可通过手势操作提升效率;TagSpaces以标签化管理文件,打破传统目录结构;燃精灵可检测微信空号,助力精准营销;GIMP作为开源图像编辑器,功能媲
官网突然“涉黄”,一场安全漏洞引发的品牌危机
流量劫持是一种常见的黑帽SEO手段,攻击者通过技术手段将用户访问请求重定向到非法网站以获取非法收益。然而,这仅仅是攻击的表象,背后可能隐藏着更大的威胁。一旦攻击者通过漏洞上传Webshell并控制服务
AI的出现,如何判定程序员的水平高不高?
本文探讨了AI时代评判程序员水平的标准,涵盖基础知识与编程能力、AI技术理解与应用能力、问题解决与创新能力及团队协作与沟通能力等多方面。同时,强调生成式人工智能认证(GAI认证)对程序员职业发展的助力
幻兽帕鲁服务端性能优化mod
这是一个非官方的《PalWorld》服务器Mod,主要用于修复内存泄漏和高CPU负载问题。目前可能存在未知Bug,建议备份游戏数据后自行测试。下载后,根据系统不同,替换对应路径下的文件即可使用。Win
AI训练师入行指南(六):模型部署
本文以“智能珠宝”为喻,探讨了模型从实验室到实际应用的全过程。首先通过格式转换(如ONNX、TensorRT)和容器化(Docker)实现模型打包与高效部署;接着构建服务化接口(RESTful API
【AI大模型】使用Python调用DeepSeek的API,原来SDK是调用这个,绝对的一分钟上手和使用
本文详细介绍了如何使用Python调用DeepSeek的API,从申请API-Key到实现代码层对话,手把手教你快速上手。DeepSeek作为领先的AI大模型,提供免费体验机会,帮助开发者探索其语言生
没有好的学历,Java开发未来的路应该怎么走?
在数字化时代,Java开发者即使没有高学历,也能通过拥抱新兴技术(如大模型应用与鸿蒙系统开发)、积累实战经验、持续学习新技能等途径实现职业突破。从参与开源项目到关注行业动态,再到规划技术专家或管理路线
蓝耘智算:开启智能算力新时代
蓝耘智算作为智能算力领域的新兴平台,为AI应用提供强大计算支持。它通过异构算力重构、丰富模型库与低代码工具,降低使用门槛,助力中小企业发展。其应用场景涵盖内容创作、金融、医疗、教育、制造及智慧城市等领
Java程序员在AI时代必会的技术:Spring AI
在AI时代,Java程序员需掌握Spring AI技术以提升竞争力。Spring AI是Spring框架在AI领域的延伸,支持自然语言处理、机器学习集成与自动化决策等场景。它简化开发流程,无缝集成Sp
开发体育直播即时比分系统:赛事收藏功能的技术实现方案
本方案展示体育即时比分系统的收藏功能实现,涵盖多端技术栈。后端采用PHP + ThinkPHP,提供API接口处理数据与用户交互;安卓端(Java)和iOS端(Objective-C)调用API实现比
RocketMQ原理—1.RocketMQ整体运行原理
本文详细解析了RocketMQ的整体运行原理,涵盖从生产者到消费者的全流程。首先介绍生产者发送消息的机制,包括Topic与MessageQueue的关系及写入策略;接着分析Broker如何通过Comm

除了postman还有什么接口测试工具
最好还是使用国内的接口测试软件,其实国内替换postman的软件有很多,这里我推荐使用yunedit-post这款接口测试工具来代替postman,因为它除了接口测试功能外,在动态参数的支持、后置处理
服务器数据恢复—NTFS分区误格式化数据怎样挽回?
NTFS文件系统下格式化在理论上不会对数据造成太大影响,但有可能造成部分文件目录结构丢失的情况。下面介绍一个人为误操作导致服务器磁盘阵列中的NTFS文件系统分区被格式化后的服务器数据恢复案例。
通义灵码助力技术求职:如何成为笔试面试冲刺的“超级助手”
在技术岗位竞争日益激烈的当下,求职季的备战已不仅是知识储备的较量,更是效率与实战能力的比拼。面对海量面试题、复杂算法挑战及快速迭代的技术框架,开发者亟需高效工具辅助突破瓶颈。阿里云推出的智能编码工具通
基于Python+Vue开发的鲜牛奶订购管理系统源码+运行
基于Python+Vue开发的鲜牛奶订购管理系统(前后端分离),这是一项为大学生课程设计作业而开发的项目。该系统旨在帮助大学生学习并掌握Python编程技能,同时锻炼他们的项目设计与开发能力。通过学习





