
阿里云开发者社区






大家在互动










综合
最新
有奖励
免费用
一文解读:阿里云AI基础设施的演进与挑战
对于如何更好地释放云上性能助力AIGC应用创新?“阿里云弹性计算为云上客户提供了ECS GPU DeepGPU增强工具包,帮助用户在云上高效地构建AI训练和AI推理基础设施,从而提高算力利用效率。”李
Apache RocketMQ ACL 2.0 全新升级
RocketMQ ACL 2.0 不管是在模型设计、可扩展性方面,还是安全性和性能方面都进行了全新的升级。旨在能够为用户提供精细化的访问控制,同时,简化权限的配置流程。欢迎大家尝试体验新版本,并应用在
案例分析|线程池相关故障梳理&总结
本文作者梳理和分享了线程池类的故障,分别从故障视角和技术视角两个角度来分析总结,故障视角可以看到现象和教训,而技术视角可以透过现象看到本质更进一步可以看看如何避免。

一文浅谈CodeReview中的一些思考
CodeReview在日常的开发过程中越来越被重视,它在提高代码质量同时促进团队成员之间的知识共享和技能提升方面发挥了诸多作用,本文将主要围绕CodeReview展开,简单聊聊在CodeReview过
飞天技术沙龙 | AI原生应用架构专场

阿里云云原生开源开发者沙龙北京站 PPT 合集


乘风问答官5月排位赛开启!
2024年5月起乘风问答官专属活动全新起航鼓励问答官们积极给予高质量的解答和参与讨论给社区带来更好的体验~2024年5月问答官专属每周积分活动、每月排位赛开启欢迎问答官们参与。 面对对象 所有乘风问
围绕 transformers 构建现代 NLP 开发环境
本文将从“样本处理”,“模型开发”,“实验管理”,“工具链及可视化“ 几个角度介绍基于 tranformers 库做的重新设计,并简单聊聊个人对“软件2.0”的看法。
10倍性能提升-SLS Prometheus 时序存储技术演进
本文将介绍近期SLS Prometheus存储引擎的技术更新,在兼容 PromQL 的基础上实现 10 倍以上的性能提升。同时技术升级带来的成本红利也将回馈给使用SLS 时序引擎的上万内外部客户。
VLDB顶会论文解读 | PolarDB MySQL高性能强一致集群核心技术详解
在VLDB2023会议上,阿里云瑶池数据库团队的论文介绍了PolarDB-SCC,这是一个创新的云原生数据库系统,确保了低延迟的全局强一致读取。PolarDB-SCC解决了传统主从架构中只读节点可能返
SLS 查询新范式:使用 SPL 对日志进行交互式探索
像 Unix 命令一样支持多级管道级联,像加工预览一样实时处理查询结果,更便捷的交互,更丰富的算子,更灵活的探索半结构化日志,快来试试使用 SPL 语言查询日志数据吧~
得物 ZooKeeper SLA 也可以 99.99%丨最佳实践
在本文中,作者探讨了ZooKeeper(ZK)的一个内存占用问题,特别是当有大量的Watcher和ZNode时,导致的内存消耗。
流水线运行出错排查难?AI 来帮你
目前云效流水线 Flow 内 Java 构建、Node.js 构建、Java 单元测试、Node.js 单元测试这 4 个步骤均接入了智能排查的能力。
让研发规范管得住 - 我们为什么在流水线之上又做了研发流程?
研发规范的目标,是为了解决或降低出现软件危机的风险。但传统流水线受限于工具的定位,无法解决研发规范的落地问题,需要在更高的层面来解决。阿里云云效团队经过内部启发后推出的新产品:云效应用交付平台 App
为什么要用 Tair 来服务低延时场景 - 从购物车升级说起
“购物车升级”是今年双十一期间提升用户体验的关键项目,展示了大淘宝技术团队致力于通过技术突破消费者和商家体验的天花板。低延迟是这些挑战中的核心,内存数据库Tair因其高吞吐、大连接数、热点请求处理、异
数据管理的艺术:PolarDB开源版详评与实战部署策略(一)
PolarDB-X是阿里巴巴自研的高性能云原生分布式数据库,基于共享存储的Shared-nothing架构,支持MySQL生态,具备金融级高可用、分布式水平扩展、HTAP混合负载等能力。它通过CN(计
高峰无忧,探索PolarDB PG版Serverless的弹性魅力
在数字经济时代,数据库成为企业命脉,面对爆炸式增长的数据,企业面临管理挑战。云原生和Serverless技术革新数据库领域,PolarDB PG Serverless作为阿里云的云原生数据库解决方案,
【云效流水线 Flow 测评】驾驭云海:五大场景下的云效Flow实战部署评测
云效是一款企业级持续集成和持续交付工具,提供免费、高可用的服务,集成阿里云多种服务,支持蓝绿、分批、金丝雀等发布策略。其亮点包括快速定位问题、节省维护成本、丰富的企业级特性及与团队协作的契合。基础版和
MaxCompute 近实时增全量处理一体化新架构和使用场景介绍
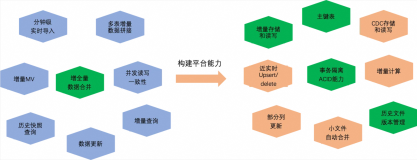
本文主要介绍基于 MaxCompute 的离线近实时一体化新架构如何来支持这些综合的业务场景,提供近实时增全量一体的数据存储和计算(Transaction Table2.0)解决方案。
保姆级python项目离线部署服务器教程只需这一篇就够了(建议收藏)
这篇文章提供了详尽的Python项目在离线Linux(CentOS)服务器上的部署教程。作者首先介绍了环境背景,强调了无网络环境和使用有网络的CentOS虚拟机准备安装包的重要性。教程分为两部分:外网


Llama 3开源!魔搭社区手把手带你推理,部署,微调和评估
Meta发布了 Meta Llama 3系列,是LLama系列开源大型语言模型的下一代。在接下来的几个月,Meta预计将推出新功能、更长的上下文窗口、额外的模型大小和增强的性能,并会分享 Llama

基于Ollama+AnythingLLM轻松打造本地大模型知识库
Ollama是开源工具,简化了在本地运行大型语言模型(ile优化模型运行,支持GPU使用和热加载。它轻量、易用,可在Mac和Linux上通过Docker快速部署。AnythingLLM是Mintple
Python小项目:利用tkinter开发测手速小游戏
这个小游戏使用Tkinter创建了一个简单的图形用户界面,用户点击“开始”按钮开始测试,然后点击“停止”按钮停止测试并显示反应时间。你可以根据需要进一步定制化游戏的界面和功能。
Python人工智能与机器学习
【4月更文挑战第11天】Python在AI和ML领域占主导地位,得益于其简洁语法、强大库支持和活跃社区。关键应用包括数据预处理(Pandas, NumPy)、模型训练(scikit-learn, Te
【专栏】Python在人工智能领域的应用现状、优势及未来趋势
【4月更文挑战第27天】本文探讨了Python在人工智能领域的应用现状、优势及未来趋势。Python作为数据科学、机器学习、深度学习和自然语言处理的首选语言,拥有丰富的库如NumPy、Pandas、T

阿里云 MaxCompute MaxFrame 开启免费邀测,统一 Python 开发生态
阿里云 MaxCompute MaxFrame 正式开启邀测,统一 Python 开发生态,打破大数据及 AI 开发使用边界。
DataWorks比如自定义函数 fx 发布到生产环境后,怎么正常发布到生产环境呢?
DataWorks比如自定义函数 fx 发布到生产环境后有其他计算任务 ab 调用了这个 fx 函数。运维中心调度计算任务 ab 时 报错说找不到 fx 函数通过 sc 脚本创建的自定义函数怎么正常
103-Django开发投票选举系统
这是一个基于 Python 3.11 和 Django 的全功能投票选举系统,提供用户认证、首页展示、投票功能、投票内容管理、数据统计与展示、用户管理和权限分配。系统支持第三方登录、搜索过滤、投票详情
DataWorks开发生产环境是分离的,怎么实现生产环境下产生的创建呢?
DataWorks开发生产环境是分离的怎么实现生产环境下产生的创建呢我是新建了一个 sc 脚本在里面 create sql function。提交该任务或者不提交到运维中心执行调用该函数的的任务都报
DataWorks回滚此次写入, 采用每次写入一行方式提交. 因为:java.怎么办?
DataWorks回滚此次写入, 采用每次写入一行方式提交. 因为:java.sql.BatchUpdateException: 磁盘空间不足 在dataworks做交换运行的时候
DataWorks创建同步任务需要新建资源组,然后新建资源组的前提是,具体我要购买什么资源呢?
DataWorks创建同步任务需要新建资源组然后新建资源组的前提是需要购买资源具体我要购买什么资源呢
DataWorks每次都调度失败,提示找不到函数。这是什么情况呢?
DataWorks使用CREATE SQL FUNCTION语法在dataworks中创建了函数但是在其他调度任务中引用该函数时每次都调度失败提示找不到函数。这是什么情况呢
DataWorks调度任务中归并节点今天报错如图所示。请问下此类问题如何排查并解决呢?
DataWorks调度任务中归并节点今天报错如图所示。我根据错误排查发现报错的节点在对应的TaskInput中请问下此类问题如何排查并解决呢
DataWorks这边上传jar的资源,每次都是进度条大概10%的时候进度消失了这是什么原因?
DataWorks这边上传jar的资源每次都是进度条大概10%的时候进度消失了jar的大小也就60M。这是什么原因
DataWorks这个加载第三方包的函数在pyodps节点中,似乎不支持,是什么情况?
DataWorks这个加载第三方包的函数在pyodps节点中提示NameError name load_resource_package is not defined,似乎不支持是什么情况
DataWorks同步过来的数据格式中。在同步到maxcompute的情况下,是否需要提前建表?
DataWorks同步过来的数据格式中。有一个五个附加列比如有一个为_executetime就是binlog时间戳。在同步到maxcompute的情况下是否需要提前建表提前建表是不是要手动加上这五个
DataWorks整库(即数据库变更数据同步到MaxCompute)在数据开发时也能配置内存大小吗?
DataWorks整库即数据库变更数据同步到MaxCompute在数据开发时也能配置内存大小啊但是他不能配置Flush间隔 和 MaxCompute通道资源设置
DataWorks单表和多表的资源设置(内存和并发数)这些应该如何配置?
DataWorks单表和多表的资源设置内存和并发数这些应该如何配置有无衡量标准比如每秒多少数据量配多少内存大小。或者说经验性的。1G的内存大小大概能支撑多少数据量。
DataWorks相同的ODPS SQL代码,开发环境中的记录insert顺序是好的这是什么问题?
DataWorks相同的ODPS SQL代码开发环境中的记录insert顺序是好的符合预期但是生产环境没有按照预想的情况来insert。这是什么问题有left join操作
datawork实时同步有何区别?
datawork实时同步,【单表Topic到单表TopicETL】和【数据库变更数据同步到MaxCompute】有何区别如果说【单表Topic到单表TopicETL】没有中间的ETL过程是不是就是和
DataWorks这个报错什么意思?
DataWorks这个报错什么意思failed: ODPS-0130071:[1,36] Semantic analysis exception - variable now_date cannot

