
阿里云开发者社区






大家在互动










综合
最新
有奖励
免费用
一文解读:阿里云AI基础设施的演进与挑战
对于如何更好地释放云上性能助力AIGC应用创新?“阿里云弹性计算为云上客户提供了ECS GPU DeepGPU增强工具包,帮助用户在云上高效地构建AI训练和AI推理基础设施,从而提高算力利用效率。”李
Apache RocketMQ ACL 2.0 全新升级
RocketMQ ACL 2.0 不管是在模型设计、可扩展性方面,还是安全性和性能方面都进行了全新的升级。旨在能够为用户提供精细化的访问控制,同时,简化权限的配置流程。欢迎大家尝试体验新版本,并应用在
案例分析|线程池相关故障梳理&总结
本文作者梳理和分享了线程池类的故障,分别从故障视角和技术视角两个角度来分析总结,故障视角可以看到现象和教训,而技术视角可以透过现象看到本质更进一步可以看看如何避免。

给技术新人的ODPS优化建议
数据开发基本都是从陌生到熟悉,但是写多了就会发现各种好用的工具/函数,也会发现各种坑,本文分享了作者从拿到数据到数据开发到数据监控的一些实操经验。
【一文看懂】Havenask单机模式创建
本次分享内容为Havenask单机模式,由下面3个部分组成(Hape工具介绍、创建单机版Havenask、Hape问题排查),希望可以帮助大家更好了解和使用Havenask。
计算新品速递 | 专为高性能计算而生,HPC优化实例正式商业化

阿里云云原生开源开发者沙龙北京站 PPT 合集

飞天技术沙龙 | AI原生应用架构专场

乘风问答官5月排位赛开启!
2024年5月起乘风问答官专属活动全新起航鼓励问答官们积极给予高质量的解答和参与讨论给社区带来更好的体验~2024年5月问答官专属每周积分活动、每月排位赛开启欢迎问答官们参与。 面对对象 所有乘风问
一文浅谈CodeReview中的一些思考
CodeReview在日常的开发过程中越来越被重视,它在提高代码质量同时促进团队成员之间的知识共享和技能提升方面发挥了诸多作用,本文将主要围绕CodeReview展开,简单聊聊在CodeReview过
为什么要用 Tair 来服务低延时场景 - 从购物车升级说起
“购物车升级”是今年双十一期间提升用户体验的关键项目,展示了大淘宝技术团队致力于通过技术突破消费者和商家体验的天花板。低延迟是这些挑战中的核心,内存数据库Tair因其高吞吐、大连接数、热点请求处理、异
最佳实践|如何使用c++开发redis module
本文将试着总结Tair用c++开发redis module中遇到的一些问题并沉淀为最佳实践,希望对redis module的使用者和开发者带来一些帮助(部分最佳实践也适用于c和其他语言)。
VLDB顶会论文解读 | PolarDB MySQL高性能强一致集群核心技术详解
在VLDB2023会议上,阿里云瑶池数据库团队的论文介绍了PolarDB-SCC,这是一个创新的云原生数据库系统,确保了低延迟的全局强一致读取。PolarDB-SCC解决了传统主从架构中只读节点可能返
1 名工程师轻松管理 20 个工作流,创业企业用 Serverless 让数据处理流程提效
为应对挑战,语势科技采用云工作流CloudFlow和函数计算FC,实现数据处理流程的高效管理与弹性伸缩,提升整体研发效能。
如何设计与构建 FinOps 流程、团队、体系与目标
企业 FinOps 实施不是一蹴而就的项目,如果您正在推进企业云原生 FinOps 落地,除了选择合适的技术手段,企业内部的流程和体系建设也尤为重要。
Spring AI 抢先体验,5 分钟玩转 Java AI 应用开发
Spring Cloud Alibaba AI 以 Spring AI 为基础,并在此基础上提供阿里云通义系列大模型全面适配,让用户在 5 分钟内开发基于通义大模型的 Java AI 应用。
【一文看懂】Havenask创建表
本次分享内容为Havenask的创建表,共3个部分组成(直写表与全量表、 创建直写表、创建全量表),希望可以帮助大家更好了解和使用Havenask。

数据管理的艺术:PolarDB开源版详评与实战部署策略(一)
PolarDB-X是阿里巴巴自研的高性能云原生分布式数据库,基于共享存储的Shared-nothing架构,支持MySQL生态,具备金融级高可用、分布式水平扩展、HTAP混合负载等能力。它通过CN(计
高峰无忧,探索PolarDB PG版Serverless的弹性魅力
在数字经济时代,数据库成为企业命脉,面对爆炸式增长的数据,企业面临管理挑战。云原生和Serverless技术革新数据库领域,PolarDB PG Serverless作为阿里云的云原生数据库解决方案,
PolarDB PostgreSQL版Serverless技术原理解读
数据库是现代企业IT系统中非常重要的一部分。在创建数据库时,客户往往需要比较保守地去配置数据库集群的资源,包括CPU、内存、存储以及连接数等多种参数配置,以确保业务能够在波峰和波谷都能平稳运行。在这种


数据管理的艺术:PolarDB开源版详评与实战部署策略(二)
PolarDB-PG是阿里云的一款云原生关系型数据库,100%兼容PostgreSQL,支持Oracle语法,采用Shared-Storage存储计算分离架构,提供极致弹性、毫秒级延迟的HTAP能力。
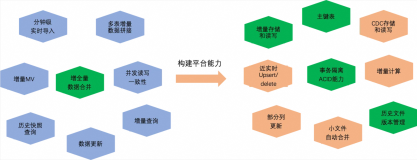
MaxCompute 近实时增全量处理一体化新架构和使用场景介绍
本文主要介绍基于 MaxCompute 的离线近实时一体化新架构如何来支持这些综合的业务场景,提供近实时增全量一体的数据存储和计算(Transaction Table2.0)解决方案。
保姆级python项目离线部署服务器教程只需这一篇就够了(建议收藏)
这篇文章提供了详尽的Python项目在离线Linux(CentOS)服务器上的部署教程。作者首先介绍了环境背景,强调了无网络环境和使用有网络的CentOS虚拟机准备安装包的重要性。教程分为两部分:外网


Llama 3开源!魔搭社区手把手带你推理,部署,微调和评估
Meta发布了 Meta Llama 3系列,是LLama系列开源大型语言模型的下一代。在接下来的几个月,Meta预计将推出新功能、更长的上下文窗口、额外的模型大小和增强的性能,并会分享 Llama

基于Ollama+AnythingLLM轻松打造本地大模型知识库
Ollama是开源工具,简化了在本地运行大型语言模型(ile优化模型运行,支持GPU使用和热加载。它轻量、易用,可在Mac和Linux上通过Docker快速部署。AnythingLLM是Mintple
Python小项目:利用tkinter开发测手速小游戏
这个小游戏使用Tkinter创建了一个简单的图形用户界面,用户点击“开始”按钮开始测试,然后点击“停止”按钮停止测试并显示反应时间。你可以根据需要进一步定制化游戏的界面和功能。
Python人工智能与机器学习
【4月更文挑战第11天】Python在AI和ML领域占主导地位,得益于其简洁语法、强大库支持和活跃社区。关键应用包括数据预处理(Pandas, NumPy)、模型训练(scikit-learn, Te
OpenKruise v1.6 版本解读:增强多域管理能力
OpenKruise 在 2024.3 发布了最新的 v1.6 版本(ChangeLog),本文对新版本的核心特性做整体介绍。
【专栏】Python在人工智能领域的应用现状、优势及未来趋势
【4月更文挑战第27天】本文探讨了Python在人工智能领域的应用现状、优势及未来趋势。Python作为数据科学、机器学习、深度学习和自然语言处理的首选语言,拥有丰富的库如NumPy、Pandas、T

Java公立医院绩效考核管理系统 医院绩效考核系统的优势有哪些?
医院绩效管理系统解决方案紧扣新医改形势下医院绩效管理的要求,以“工作量为基础的考核方案”为核心思想,结合患者满意度、服务质量、技术难度、工作效率、医德医风等管理发展目标的考核体系,形成医院的内部绩效考
XML DOM - 访问节点
`getElementsByTagName()` 方法从 `xmlDoc` 加载 "books.xml",创建一个包含匹配节点的节点列表。该列表可遍历以访问每个节点,实现对 XML
南开、字节开源StoryDiffusion让多图漫画和长视频更连贯
【5月更文挑战第13天】南开大学和字节跳动合作开发的StoryDiffusion技术,通过创新的一致性自注意力和语义运动预测器,提升了多图漫画和长视频的连贯性生成。该技术解决了内容一致性问题,增强了文
苹果推出理解、转化模型ReALM,性能超GPT-4
【5月更文挑战第13天】苹果发布ReALM模型,将参考解析转化为语言建模,超越GPT-4。ReALM通过将非文本实体转为文本处理,解决了AI在处理特定问题时的局限。实验显示,ReALM在多种参考解析任
在12个视频理解任务中,Mamba先打败了Transformer
【5月更文挑战第13天】Mamba,一种状态空间模型,在12个视频理解任务中超越Transformer,显示其在视频编码、解码、生成和分类等角色上的高效性能。研究发现Mamba在视频分类任务中的准确率
索引
Lua中的赋值语句用于改变变量或表域的值。可以同时对多个变量赋值,如`a, b = 10, 2x`。赋值时,Lua先计算右边值再分配给左边变量,允许交换变量值,如`x, y = y, x`。若变量与值
赋值语句
Lua中的赋值用于改变变量或表域,支持同时对多个变量赋值。例如:`a, b = 10, 2x`。赋值时,Lua先计算右值再分配。可以交换变量值如:`x, y = y, x`。当变量与值数量不匹配时,
可变参数
Lua函数用于任务执行和值计算,支持可变参数,如`add(...)`,参数`...`表示变长参数列表。在函数内部,`{...}`转化为数组,可用于遍历和操作所有参数。例如,`add(3,4,5,6,7
机器精度
Julia 的 eps 函数揭示了浮点数的机器精度,即最小可表示的间隔。对于 Float32,此间隔为 2.0^-23,Float64 为 2.0^-52。eps(x) 返回 x 到其相邻浮点数的距离
特殊的浮点值
在编程中,特殊浮点值包括正无穷 (`Inf`)、负无穷 (`-Inf`) 和非数字 (`NaN`),它们不对应实数轴上的点。`Inf` 比所有有限浮点数大,`-Inf` 比所有有限浮点数小,`NaN`
Julia 数据类型
Julia中的数据类型包括整数、浮点数和字面量。类型转换通过T(x)、convert(T,x)或x % T实现,其中错误转换会抛出InexactError。示例展示了Int8转换,显示了不同类型转换的
使用Go和JavaScript爬取股吧动态信息的完整指南
本文介绍了如何使用Go和JavaScript构建网络爬虫,从股吧网站抓取实时股市信息。通过设置代理服务器以应对反爬策略,利用`got`库执行JavaScript提取动态数据,如用户讨论和市场分析。示例

云效流水线 Flow 评测报告
作为运维工程师,我有使用Jenkins和GitLab CI/CD的经验。Flow在新人上手方面表现出色,界面清晰,文档支持良好。产品功能全面,支持多种语言和环境,性能稳定,且具备开放性,能自定义和扩展
深入探索Spring Boot的监控、管理和测试功能及实战应用
【5月更文挑战第14天】Spring Boot是一个快速开发框架,提供了一系列的功能模块,包括监控、管理和测试等。本文将深入探讨Spring Boot中监控、管理和测试功能的原理与应用,并提供实际应用
【项目--Hi3559A】如何在Hi3559A上运行自己的yolov3模型(修改类别、网络结构)
【项目--Hi3559A】如何在Hi3559A上运行自己的yolov3模型(修改类别、网络结构)
【linux 学习】在Linux中经常用到的cmake、make、make install等命令解析
【linux 学习】在Linux中经常用到的cmake、make、make install等命令解析
【项目--Hi3559A】(caffe-yolov3)yolov3的darknet模型转caffe模型详细教程
【项目--Hi3559A】(caffe-yolov3)yolov3的darknet模型转caffe模型详细教程

深入PHP内核:理解Opcode缓存与性能优化
【5月更文挑战第14天】 在动态语言的世界里,PHP一直因其高性能的执行效率和广泛的社区支持而备受青睐。随着Web应用的复杂性增加,对性能的要求也越来越高。本文将探讨PHP的Opcode缓存机制,解析
《手把手教你》系列技巧篇(四十四)-java+ selenium自动化测试-处理https 安全问题或者非信任站点-下篇(详解教程)
【5月更文挑战第8天】这篇文档介绍了如何在IE、Chrome和Firefox浏览器中处理不信任证书的问题。作者北京-宏哥分享了如何通过编程方式跳过浏览器的证书警告,直接访问不受信任的HTTPS网站。文
Kubernetes 集群监控与性能优化实践
【5月更文挑战第14天】 在微服务架构日益普及的当下,Kubernetes 已成为容器编排的事实标准。然而,随着集群规模的扩大和业务复杂度的增加,监控系统的性能及稳定性变得至关重要。本文将深入探讨 K
安卓应用性能优化实战
【5月更文挑战第14天】 在当今移动应用竞争激烈的市场中,一款应用的性能直接影响用户体验和留存率。特别是对于安卓平台,由于设备多样性和应用生态环境的复杂性,性能优化显得尤为重要。本文将深入探讨安卓应用
阿里云服务器租用价格参考,云服务器收费标准与实时活动价格整理
阿里云服务器租用价格参考,本文更新了阿里云服务器最新的租赁费用,包括云服务器实时的活动价格与云服务器收费标准。经济型e实例云服务器4核16G10M带宽配置30.00元/1个月、90.00元/3个月,独

构建高效稳定的云基础设施:DevOps与容器技术的融合
【5月更文挑战第14天】 在当今快速发展的软件行业中,持续集成、持续部署(CI/CD)和微服务架构已成为提高软件交付速度和质量的关键。本文将探讨如何通过结合DevOps理念和容器技术,构建一个高效、稳
深度学习在图像识别中的应用和挑战
【5月更文挑战第14天】 随着人工智能的飞速发展,深度学习技术已成为推动计算机视觉领域革新的主要动力。本文将深入探讨深度学习在图像识别任务中的关键应用,并剖析当前面临的技术挑战与潜在解决方案。我们将从
常见的web漏洞,网站漏洞该怎么办
随着互联网的发展,网站安全成为企业和个人关注焦点,尤其网站漏洞可能导致数据泄露、系统崩溃等严重后果。本文介绍了四种常见网站漏洞:XSS、SQL注入、文件包含和CSRF,以及它们的危害。为解决这些问题,
未来技术纵横谈:区块链、物联网与虚拟现实的融合前景
【5月更文挑战第14天】 随着科技不断进步,新兴技术如区块链、物联网(IoT)和虚拟现实(VR)正逐渐改变我们的生活和工作方式。本文将深入探讨这些技术的发展趋势,并分析它们在不同应用场景中的融合潜力。

