
阿里云开发者社区






大家在互动










综合
最新
有奖励
免费用

社区供稿 | FunASR 语音大模型在 Arm Neoverse 平台上的优化实践
Arm 架构的服务器通常具备低功耗的特性,能带来更优异的能效比。相比于传统的 x86 架构服务器,Arm 服务器在相同功耗下能够提供更高的性能。这对于大模型推理任务来说尤为重要,因为大模型通常需要大量
让你的文档从静态展示到一键部署可操作验证
通过函数计算的能力让阿里云的文档从静态展示升级为动态可操作验证,用户在文档中单击一键部署可快速完成代码的部署及测试。这一改变已在函数计算的活动沙龙中得到用户的认可。
一键生成视频!用 PAI-EAS 部署 AI 视频生成模型 SVD 工作流
本教程将带领大家免费领取阿里云PAI-EAS的免费试用资源,并且带领大家在 ComfyUI 环境下使用 SVD的模型,根据任何图片生成一个小短视频。
ECS实例选型最佳实践
本课程主要讲解在客户明确自身业务功能、性能、稳定性需求,以及成本成本约束后去了解各规格族/规格特性,匹配自身需求选择所需服务器类型。实例规格选型最佳实践,就是为了帮助用户结合自身业务需求中性能、价格、
Redis核心开发者的新征程:阿里云与Valkey社区的技术融合与创新
阿里云瑶池数据库团队后续将持续参与Valkey社区,如过往在Redis社区一样耕耘,为开源社区作出持续贡献。

PAI-EAS 一键启动ComfyUI!SVD 图片一键生成视频 stable video diffusion 教程 SVD工作流
PAI-EAS 一键启动ComfyUI!SVD 图片一键生成视频 stable video diffusion 教程 SVD工作流

阿里云产品手册2024版
阿里云作为数字经济的重要建设者,不断加深硬核科技实力,通过自身能力助力客户实现高质量发展,共创数字新世界。阿里云产品手册 2024 版含产品大图、关于阿里云、引言、安全合规等内容,覆盖人工智能与机器学

flinkcdc3.0整库同步mysql的数据到starrocks中全量能过去增量过不去怎么排查?
flinkcdc3.0整库同步mysql的数据到starrocks中 全量能过去增量过不去怎么排查?
阿里云百炼大模型产品实践
RocketMQ 事件驱动:云时代的事件驱动有啥不同?
本文深入探讨了云时代 EDA 的新内涵及它在云时代再次流行的主要驱动力,包括技术驱动力和商业驱动力,随后重点介绍了 RocketMQ 5.0 推出的子产品 EventBridge,并通过几个云时代事件
阿里云 ClickHouse 企业版商业化发布会
阿里云 ClickHouse 企业版是阿里云和ClickHouse原厂 ClickHouse. Inc 独家合作的存算分离的云原生版本,支持资源按需弹性 Serverless,帮助企业降低成本的同时,


宜搭:提交表单前,如何校验另一张表单的数据?
大神帮忙实现用宜搭实现一个功能写一个详细的操作步骤提交表单A前根据表单A上的限制条件C查询另一张表单B的数据D校验这个D是否小于等于0如果D小于等于0系统禁止用户提交并提示“没有了”
通义灵码牵手阿里云函数计算 FC ,打造智能编码新体验
近日,通义灵码正式进驻函数计算 FC WebIDE,让使用函数计算产品的开发者在其熟悉的云端集成开发环境中,无需再次登录即可使用通义灵码的智能编程能力,实现开发效率与代码质量的双重提升。

手把手教你捏一个自己的Agent
Modelscope AgentFabric是一个基于ModelScope-Agent的交互式智能体应用,用于方便地创建针对各种现实应用量身定制智能体,目前已经在生产级别落地。
基于Ollama+AnythingLLM轻松打造本地大模型知识库
Ollama是开源工具,简化了在本地运行大型语言模型(ile优化模型运行,支持GPU使用和热加载。它轻量、易用,可在Mac和Linux上通过Docker快速部署。AnythingLLM是Mintple
云效流水线智能排查功能实测:AI赋能DevOps,精准定位与高效修复实战评测
云效持续集成流水线Flow是阿里云提供的企业级CICD工具,免费且注册即用。它具备高可用性、免运维、深度集成阿里云服务、多样化发布策略及丰富的企业级特性。产品亮点包括智能排查功能,能快速定位问题,提高
使用Redis实例搭建网上商城的商品相关性分析程序
本教程将指导您如何快速创建实例并搭建网上商城的商品相关性分析程序。(ApsaraDB for Redis)是兼容开源Redis协议标准的数据库服务,基于双机热备架构及集群架构,可满足高吞吐、低延迟及弹

号外号外!ClickHouse企业版正式商业化啦!
阿里云将于2024年4月23日14:00举办《ClickHouse企业版商业化发布会》直播,探讨阿里云ClickHouse企业版的架构、功能与优势,以及未来一年的产品规划。直播还将分享ClickHou

Llama 3开源!魔搭社区手把手带你推理,部署,微调和评估
Meta发布了 Meta Llama 3系列,是LLama系列开源大型语言模型的下一代。在接下来的几个月,Meta预计将推出新功能、更长的上下文窗口、额外的模型大小和增强的性能,并会分享 Llama

第十三期乘风伯乐奖--寻找百位乘风者伯乐,邀请新博主入驻即可获奖
乘风伯乐奖,面向阿里云开发者社区已入驻乘风者计划的博主(技术/星级/专家),邀请用户入驻乘风者计划即可获得乘风者定制周边等实物奖励。本期面向阿里云开发者社区寻找100位乘风伯乐,邀请人数月度TOP 1
PolarDB +AnalyticDB Zero-ETL :免费同步数据到ADB,享受数据流通新体验
Zero-ETL是阿里云瑶池数据库提供的服务,旨在简化传统ETL流程的复杂性和成本,提高数据实时性。降低数据同步成本,允许用户快速在AnalyticDB中对PolarDB数据进行分析,降低了30%的数
Flink CDC产品常见问题之look up hint 没有生效如何解决
Flink CDC(Change Data Capture)是一个基于Apache Flink的实时数据变更捕获库,用于实现数据库的实时同步和变更流的处理;在本汇总中,我们组织了关于Flink CDC
亮数据:数据采集行业痛点的利器
在数据驱动的时代,企业需高效采集大量数据以作出明智决策,但面临IP限制、验证码识别和效率低下的挑战。BrightData应运而生,提供丰富的代理IP资源、高匿名性和稳定性保障,以及智能IP更换策略,有

阿里云数据库 SelectDB 内核 Apache Doris 2.1.0 版本发布:开箱盲测性能大幅优化,复杂查询性能提升 100%
亲爱的社区小伙伴们,Apache Doris 2.1.0 版本已于 2024 年 3 月 8 日正式发布,新版本开箱盲测性能大幅优化,在复杂查询性能方面提升100%,新增Arrow Flight接口加
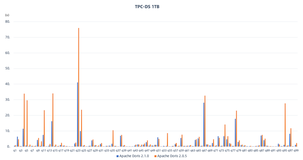
阿里云数据库内核 Apache Doris 兼容 Presto、Trino、ClickHouse、Hive 等近十种 SQL 方言,助力业务平滑迁移
阿里云数据库 SelectDB 内核 Doris 的 SQL 方言转换工具, Doris SQL Convertor 致力于提供高效、稳定的 SQL 迁移解决方案,满足用户多样化的业务需求。兼容 Pr


钱大妈生鲜如何利用 CCR 实现 Apache Doris 集群读写分离
钱大妈基于 阿里云 SelectDB 内核 Apache Doris 搭建了实时数仓,为业务提供实时精准分析的数据查询及分析服务。凭借 Apache Doris 强大的性能,钱大妈能够实时监控生鲜产品
Flink CDC在阿里云DataWorks数据集成应用实践
本文整理自阿里云 DataWorks 数据集成团队的高级技术专家 王明亚(云时)老师在 Flink Forward Asia 2023 中数据集成专场的分享。

一键开启 GPU 闲置模式,基于函数计算低成本部署 Google Gemma 模型服务
本文介绍如何使用函数计算 GPU 实例闲置模式低成本、快速的部署 Google Gemma 模型服务。
Serverless 应用引擎常见问题之改配置变慢如何解决
Serverless 应用引擎(Serverless Application Engine, SAE)是一种完全托管的应用平台,它允许开发者无需管理服务器即可构建和部署应用。以下是Serverless
Serverless 应用引擎常见问题之做的web服务计费如何解决
Serverless 应用引擎(Serverless Application Engine, SAE)是一种完全托管的应用平台,它允许开发者无需管理服务器即可构建和部署应用。以下是Serverless
网络安全与信息安全:保护数据的关键
【4月更文挑战第24天】本文将探讨网络安全与信息安全的重要性,以及如何通过识别网络安全漏洞、应用加密技术和提高安全意识来保护数据。我们将讨论当前的威胁和挑战,以及如何通过采取预防措施和使用最新技术来应
网络安全与信息安全:保护数据的关键策略
【4月更文挑战第24天】 在数字化时代,数据成为了新的货币。然而,随着网络攻击的日益猖獗,如何确保信息的安全和隐私成为了一个亟待解决的问题。本文将深入探讨网络安全漏洞的概念、加密技术的重要性以及提升安
PHP中的命名空间深入解析
【4月更文挑战第24天】在PHP的编程世界中,命名空间是一个重要的概念,它解决了在大型项目中可能出现的类名或函数名冲突的问题。本文将深入探讨PHP中的命名空间,包括其基本概念、使用方法以及其在代码组织
构建未来:云原生架构在企业数字化转型中的关键作用
【4月更文挑战第24天】 随着企业加速其数字化转型之旅,云原生架构已成为实现敏捷性、可扩展性和持续创新的关键推动力。本文将探讨云原生技术如何助力企业构建灵活的IT环境,支持快速部署新服务,并提高整体业
构建高效机器学习模型:从数据预处理到模型优化
【4月更文挑战第24天】在机器学习的实践中,构建一个高效的模型不仅需要选择合适的算法,还需要对数据进行恰当的预处理以及对模型参数进行细致的调优。本文将深入探讨如何通过数据清洗、特征工程、模型选择和超参
未来技术的融合潮流:区块链、物联网和虚拟现实的交汇点
【4月更文挑战第24天】 随着科技的不断进步,新兴技术如区块链、物联网(IoT)和虚拟现实(VR)正在重塑我们的世界。这些技术不仅单独发展,而且越来越多地相互结合,创造出前所未有的应用场景。本文将探讨
未来技术纵横谈:区块链、物联网与虚拟现实的融合与创新
【4月更文挑战第24天】 随着科技的迅猛发展,新兴技术如区块链、物联网(IoT)、虚拟现实(VR)等正在重塑我们的生活和工作方式。这些技术不仅在自身领域内不断演进,而且开始相互渗透,形成新的应用趋势。
移动应用的未来之路:Flutter框架与跨平台开发
【4月更文挑战第24天】 在移动应用的世界中,快速迭代和跨平台兼容性是成功的关键。Google推出的开源UI工具包——Flutter,以其高性能、美观的界面和一次编码多平台部署的特性,正成为开发者的新
构建高性能微服务架构:后端开发的新趋势
【4月更文挑战第24天】 在现代软件开发的浪潮中,微服务架构已经成为了企业追求敏捷、可扩展和容错性的关键解决方案。本文将深入剖析如何构建一个高性能的微服务系统,涵盖关键的设计原则、技术选型以及性能优化
Java 并发编程:理解线程池
【4月更文挑战第24天】 在处理多任务和高并发场景时,Java 提供了强大的并发工具——线程池。本文将深入探讨线程池的概念、原理以及如何使用 Java 实现高效且可维护的线程管理。通过分析线程池的优势
安卓应用开发:构建高效用户界面的策略
【4月更文挑战第24天】 在竞争激烈的移动应用市场中,一个流畅且响应迅速的用户界面(UI)是吸引和保留用户的关键。针对安卓平台,开发者面临着多样化的设备和系统版本,这增加了构建高效UI的复杂性。本文将
基于 MaxCompute MaxFrame 实现分布式 Pandas 处理
阿里云分布式计算框架 MaxCompute MaxFrame 兼容 Pandas 接口且自动进行分布式处理,在保证强大数据处理能力的同时,可以大幅度提高数据处理规模及计算效率。
Claude3是什么?
Claude 3最近备受各大媒体瞩目,成为了AI领域备受关注的新宠。在ChatGPT推出更高版本之前,Claude 3已经被公认为是语言类AI工具中的佼佼者,特别在处理逻辑性和长篇上下文方面表现突出。

oceanbase数据库这个也配置了 难道是服务器问题吗?
https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000000510458 oceanbase数据库这个也配置了
如何在 Windows 上安装SSMS,保姆级教程来了!
安装SQL Server Management Studio (SSMS) 的过程包括:从安装界面或微软官网下载SSMS安装包,点击运行,选择安装选项,等待安装完成,并通过SSMS连接到数据库以验证安
如下 请问有OceanBase数据库的这个安装包吗?
有OceanBase数据库的 mydumper-0.12.7-2-zstd.el7.x86_64.rpm 这个安装包嘛麻烦发下我这边一直下载不下来
如下,这是OceanBase数据库的具体日志,请问怎么解决?
https://ask.oceanbase.com/https://ask.oceanbase.com/t/topic/35607035 这是OceanBase数据库的具体日志请问怎么解决

