
阿里云开发者社区






大家在互动










综合
最新
有奖励
免费用
让你的文档从静态展示到一键部署可操作验证
通过函数计算的能力让阿里云的文档从静态展示升级为动态可操作验证,用户在文档中单击一键部署可快速完成代码的部署及测试。这一改变已在函数计算的活动沙龙中得到用户的认可。
一键生成视频!用 PAI-EAS 部署 AI 视频生成模型 SVD 工作流
本教程将带领大家免费领取阿里云PAI-EAS的免费试用资源,并且带领大家在 ComfyUI 环境下使用 SVD的模型,根据任何图片生成一个小短视频。
倚天使用|YODA倚天应用迁移神器,让跨架构应用迁移变得简单高效
YODA(Yitian Optimal Development Assistant,倚天应用迁移工具)旨在帮助用户更加高效、便捷地实现跨平台、跨结构下的应用迁移,大幅度缩短客户在新平台上端到端性能验
Paimon 与 Spark 的集成(二):查询优化
通过一系列优化,我们将 Paimon x Spark 在 TpcDS 上的性能提高了37+%,已基本和 Parquet x Spark 持平,本文对其中的关键优化点进行了详细介绍。
ECS实例选型最佳实践
本课程主要讲解在客户明确自身业务功能、性能、稳定性需求,以及成本成本约束后去了解各规格族/规格特性,匹配自身需求选择所需服务器类型。实例规格选型最佳实践,就是为了帮助用户结合自身业务需求中性能、价格、
Higress 基于自定义插件访问 Redis
本文介绍了Higress,一个支持基于WebAssembly (WASM) 的边缘计算网关,它允许用户使用Go、C++或Rust编写插件来扩展其功能。文章特别讨论了如何利用Redis插件实现限流、缓存

创建to do list应用教程
阿里云讲师手把手带你部署to do list,本实验支持使用 个人账号资源 或 领取免费试用额度 进行操作,建议优先选用通过已领取的云工开物高校计划学生300元优惠券购买个人账号资源的方案,如您具备免
conda数据源在昨天失效返回404,当前依赖的包无法安装和使用
问题描述conda数据源在失效返回404当前依赖的包无法安装和使用失效的镜像通道地址conda-forge: http://mirrors.aliyun.com/anaconda/cloud
阿里云百炼大模型产品实践

PAI-EAS 一键启动ComfyUI!SVD 图片一键生成视频 stable video diffusion 教程 SVD工作流
PAI-EAS 一键启动ComfyUI!SVD 图片一键生成视频 stable video diffusion 教程 SVD工作流

阿里云产品手册2024版
阿里云作为数字经济的重要建设者,不断加深硬核科技实力,通过自身能力助力客户实现高质量发展,共创数字新世界。阿里云产品手册 2024 版含产品大图、关于阿里云、引言、安全合规等内容,覆盖人工智能与机器学

ModelScope qwen7b、14b、72b lora微调分别需要的显存和cpu内存是多少?
ModelScope qwen7b、14b、72b lora微调分别需要的显存和cpu内存是多少

All in One:Prometheus 多实例数据统一管理最佳实践
当管理多个Prometheus实例时,阿里云Prometheus托管版相比社区版提供了更可靠的数据采集和便捷的管理。本文比较了全局聚合实例与数据投递方案,两者在不同场景下各有优劣。
Higress 全新 Wasm 运行时,性能大幅提升
本文介绍 Higress 将 Wasm 插件的运行时从 V8 切换到 WebAssembly Micro Runtime (WAMR) 的最新进展。

【活动推荐】Alibaba Cloud Linux实践操作学习赛,有电子证书及丰厚奖品!
参与开放原子基金会的[龙蜥社区Alibaba Cloud Linux实践操作学习赛](https://competition.atomgit.com/competitionInfo),获取电子证书。报




阿里云高级技术专家李鹏:AI基础设施的演进与挑战 | GenAICon 2024
阿里云高级技术专家、阿里云异构计算AI推理团队负责人李鹏将在主会场第二日上午的AI Infra专场带来演讲,主题为《AI基础设施的演进与挑战》。
第十三期乘风伯乐奖--寻找百位乘风者伯乐,邀请新博主入驻即可获奖
乘风伯乐奖,面向阿里云开发者社区已入驻乘风者计划的博主(技术/星级/专家),邀请用户入驻乘风者计划即可获得乘风者定制周边等实物奖励。本期面向阿里云开发者社区寻找100位乘风伯乐,邀请人数月度TOP 1
RocketMQ 之 IoT 消息解析:物联网需要什么样的消息技术?
RocketMQ 5.0 是为应对物联网(IoT)场景而发布的云原生消息中间件,旨在解决 IoT 中大规模设备连接、数据处理和边缘计算的需求。


购买阿里云活动内云服务器之后设置密码、安全组、增加带宽、挂载云盘教程
当我们通过阿里云的活动购买完云服务器之后,并不是立马就能使用了,还需要我们设置云服务器密码,配置安全组等基本操作之后才能使用,有的用户还需要购买并挂载数据盘到云服务器上,很多新手用户由于是初次使用阿里


电子好书发您分享《从零开始玩转AIGC 从零开始玩转AIGC》
探索AIGC世界的指南:《从零开始玩转AIGC》,阿里云提供的电子书,引领读者踏入AI内容生成的领域。[阅读链接](https://developer.aliyun.com/ebook/8330/11
< 知识拓展:前端代码规范 >
前端开发中,随着工具组件的多样化,代码的“千人千面”现象带来了管理和维护的挑战。因此,制定代码规范变得至关重要,它能提升代码质量,便于团队协作。命名规范要求文件和目录使用小写和下划线或驼峰式,HTML

电子好书发您分享《代码管理实践10讲 代码管理实践10讲》
**《代码管理实践10讲》电子书分享:**深入探讨代码管理关键技巧,助力开发者提升协作效率和代码质量。[阅读全文](https://developer.aliyun.com/ebook/8331/11
电子好书发您分享《PolarDB分布式版架构介绍 PolarDB分布式版架构介绍》
《PolarDB分布式版架构介绍》电子书分享,深入解析阿里云PolarDB的分布式设计,包括计算存储分离、高可用架构及分布式特性,助力理解云原生数据库技术。[阅读链接](https://develop

用ModelScope平台开发的项目打包后执行错误
最近用ModelScope平台开发了一个人脸识别项目使用了识别模型damo/cv_tinynas_head-detection_damoyolo和damo/cv_ir50_face-recognit
< 在Vue中,为什么 v-if 和 v-for 不建议一起使用 ? >
在Vue指令中,最经常被用于做逻辑操作的指令,莫过于 `v-if` 和 `v-for`。但是它们之间的能否一起使用呢? 这个问题有时候会被面试官问起,用于测试应试者对这两个指令的了解。 接下来,对

如何实现AI检测与反检测原理
AI检测器用于识别AI生成的文本,如ChatGPT,通过困惑度和爆发性指标评估文本。低困惑度和低爆发性可能指示AI创作。OpenAI正研发AI文本水印系统,但尚处早期阶段。现有检测器对长文本较准确,但
< elementUi 中 树状侧边栏,机构单位 - 岗位 字典 >
本文介绍了如何在Vue + ElementUI环境中,利用Tree组件和Dropdown下拉菜单实现组织单位、岗位的树状数据可视化展示及操作。案例展示了包含头部搜索、节点下拉菜单功能的树形控件,支持增

Submail邮箱API发送邮件的方法步骤
Submail提供邮箱API,助开发人员快捷集成邮件发送功能。步骤包括:1) 注册Submail账号获取API密钥;2) 使用Composer引入SDK;3) 初始化SDK并设置密钥;4) 设置邮件参
< 了解 HTTP 这一篇就够了 :什么是 HTTP ?HTTP 和 HTTPS 有什么区别 ? >
在前端开发中,是和浏览器打交道最为频繁的行业之一。但是大部分卷王们,可能仅仅是知道如何使用浏览器,只是知道 URL 跳转到浏览器变成一个完整的网页。 本篇文章将讲述 什么是HTTP、 HTTP 和 H

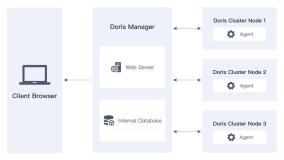
Doris Manager 24.0 版本正式发布!
Doris Manager 24.0,SelectDB 的 Apache Doris 集群管理工具,迎来重大更新,包括管控模式升级至安全的 Agent 模式、新增任务审计、主机监控、计算节点部署支持等
Apache Doris 2.1.2 版本正式发布!
Apache Doris 2.1.2 版本正式发布!该版本提交了若干改进项以及问题修复,进一步提升了系统的性能及稳定性,欢迎大家下载体验!
服务器中毒怎么办?企业数据安全需重视
互联网企业包括基础层、服务层和终端层,后者涉及网络服务、内容提供、应用服务等。随着业务发展,企业积累了大量数据,数据安全成为关注焦点,尤其是防范服务器中毒导致的数据泄露。中毒迹象包括文件消失、程序异常

通义灵码关于Python mmap标准库回答前后矛盾不正确,想问问是什么原因?
以下是我测试的结果 我的提问python 3.9版本mmap标准库有readline方法码 我的提问”python mmap 库自身提供名为 readline 的方法吗“或”python 3.9
【Redis系列笔记】持久化
Redis的确是将数据存储在内存的,但是也会有相关的持久化机制将内存持久化备份到磁盘,以便于重启时数据能够重新恢复到内存中,避免数据丢失的风险。有三种持久化方式——RDB,AOF,混合持久化。RDB持
PyTorch实战:图像分类任务的实现与优化
【4月更文挑战第17天】本文介绍了使用PyTorch实现图像分类任务的步骤,包括数据集准备(如使用CIFAR-10数据集)、构建简单的CNN模型、训练与优化模型以及测试模型性能。在训练过程中,使用了交
< 每日小技巧:Vue常用修饰符 >
在Vue开发中,我们时常会发现 `Vue指令`有些数据被拿到之后,需要进行处理才能直接使用, 又或者是有些事件、属性需要二次处理,才能直接使用。 但是有没有一种可以直接配合(修饰)Vue指令操作的功能
PyTorch进阶:模型保存与加载,以及断点续训技巧
【4月更文挑战第17天】本文介绍了PyTorch中模型的保存与加载,以及断点续训技巧。使用`torch.save`和`torch.load`可保存和加载模型权重和状态字典。保存模型时,可选择仅保存轻量
构建你的第一个PyTorch神经网络模型
【4月更文挑战第17天】本文介绍了如何使用PyTorch构建和训练第一个神经网络模型。首先,准备数据集,如MNIST。接着,自定义神经网络模型`SimpleNet`,包含两个全连接层和ReLU激活函数
快来与 CodeQwen1.5 结对编程!
今天,来自 Qwen1.5 开源家族的新成员,代码专家模型 CodeQwen1.5开源!CodeQwen1.5 基于 Qwen 语言模型初始化,拥有 7B 参数的模型,其拥有 GQA 架构,经过了 ~
如何在阿里云服务器快速搭建部署Nginx环境
以下是内容的摘要: 本文档主要介绍了在阿里云上购买和配置服务器的步骤,包括注册阿里云账号、实名认证、选择和购买云服务器、配置安全组、使用Xshell和Xftp进行远程连接和文件传输,以及安装和配置N
深入理解PyTorch自动微分:反向传播原理与实现
【4月更文挑战第17天】本文深入解析PyTorch的自动微分机制,重点讨论反向传播的原理和实现。反向传播利用链式法则计算神经网络的梯度,包括前向传播、梯度计算、反向传播及参数更新。PyTorch通过`
<Javascript技巧: Javascript 是个难泡的妞,学点技巧征服 “ 她 ” >
在前端开发中,无论是否使用框架,在代码编写上,都与 Javascript 息息相关。本篇文章将带领大家学习 JS的相关技巧,征服 Javascript 这个高冷的 “ 妞 ”!
阿里云服务器购买之后发票如何申请?申请发票流程及常见问题参考
申请发票是很多用户尤其是企业级用户在购买完阿里云服务器之后非常关注的问题,对于初次购买阿里云服务器的用户来说,往往并不清楚如何找阿里云申请发票,本文以图文形式为大家介绍阿里云服务器购买完成之后申请发票
静态IP代理和动态IP代理的区别是什么?
在网络通信中,IP地址标识设备位置。静态IP代理提供固定的IP地址,确保稳定性与匿名性,适用于企业网络,而动态IP代理使用可变IP,提供灵活性,常用于爬虫和数据采集。静态IP代理稳定但易被识别封锁,动
PyTorch模型训练:优化器与损失函数的选择
【4月更文挑战第17天】PyTorch中的优化器(如SGD, Adam, RMSprop)和损失函数(如MSE Loss, Cross Entropy Loss)对模型训练效果有显著影响。优化器选择应
PyTorch中的数据加载与预处理
【4月更文挑战第17天】了解PyTorch中的数据加载与预处理至关重要。通过`Dataset`和`DataLoader`,我们可以自定义数据集、实现批处理、数据混洗及多线程加载。`transforms
PyTorch入门指南:从安装到基础操作
【4月更文挑战第17天】PyTorch入门指南介绍了安装、Tensor操作、自动微分、神经网络构建及训练。安装PyTorch可通过官网选择相应环境的预构建包或使用conda命令。Tensor是基本计算
PyTorch深度学习基础:张量(Tensor)详解
【4月更文挑战第17天】本文详细介绍了PyTorch中的张量,它是构建和操作深度学习数据的核心。张量是多维数组,用于存储和变换数据。PyTorch支持CPU和GPU张量,后者能加速大规模数据处理。创建
云效流水线使用记录
在云效Flow中配置空任务,添加步骤并保存运行。遇到构建失败问题,日志显示Maven在指定目录找不到`pom.xml`。解决方案包括检查工作空间路径、源代码拉取、Maven命令、启用详细日志和查阅Ma

TensorFlow的扩展库:TensorFlow Probability与TensorFlow Quantum
【4月更文挑战第17天】TensorFlow的扩展库TensorFlow Probability和TensorFlow Quantum开辟了机器学习和量子计算新纪元。TensorFlow Probab
域名解析遇到的问题,解答都在这里
在阿里云服务器进行DNS解析时可能遇到的问题包括DNS解析慢、失败、域名被墙、污染、NS记录错误、A/CNAME记录错误、DNS缓存、云解析服务故障、域名授权及防火墙限制。解决方法涉及检查设置、使用阿
社区供稿 | 140B参数、可商用!OpenBuddy 发布首个开源千亿中文 MoE 模型的早期预览版
我们很自豪地于今天发布OpenBuddy最新一代千亿MoE大模型的早期预览版本:OpenBuddy-Mixtral-22Bx8-preview0-65k。此次发布的早期预览版对应约50%的训练进度。
TensorFlow的保存与加载模型
【4月更文挑战第17天】本文介绍了TensorFlow中模型的保存与加载。保存模型能节省训练时间,便于部署和复用。在TensorFlow中,可使用`save_model_to_hdf5`保存模型结构,
TensorFlow分布式训练:加速深度学习模型训练
【4月更文挑战第17天】TensorFlow分布式训练加速深度学习模型训练,通过数据并行和模型并行利用多机器资源,减少训练时间。优化策略包括配置计算资源、优化数据划分和减少通信开销。实际应用需关注调试
TensorFlow与GPU加速:提升深度学习性能
【4月更文挑战第17天】本文介绍了TensorFlow如何利用GPU加速深度学习, GPU的并行处理能力适合处理深度学习中的矩阵运算,显著提升性能。TensorFlow通过CUDA和cuDNN库支持G





