

阿里云开发者社区































综合
最新
有奖励
免费用
QwQ-32B一键部署!真正的0代码,0脚本,0门槛
阿里云发布的QwQ-32B模型通过强化学习显著提升了推理能力,核心指标达到DeepSeek-R1满血版水平。用户可通过阿里云系统运维管理(OOS)一键部署OpenWebUI+Ollama方案,轻松将Q
K8S异常诊断之俺的内存呢
本文讲述作者如何解决客户集群中出现的OOM(Out of Memory)和Pod驱逐问题。文章不仅详细记录了问题的发生背景、现象特征,还深入探讨了排查过程中的关键步骤和技术细节。

技术小白如何利用DeepSeek半小时开发微信小程序?
通过通义灵码的“AI程序员”功能,即使没有编程基础也能轻松创建小程序或网页。借助DeepSeek V3和R1满血版模型,用户只需用自然语言描述需求,就能自动生成代码并优化程序。例如,一个文科生仅通过描


一篇关于DeepSeek模型先进性的阅读理解
本文以DeepSeek模型为核心,探讨了其技术先进性、训练过程及行业影响。首先介绍DeepSeek的快速崛起及其对AI行业的颠覆作用。DeepSeek通过强化学习(RL)实现Time Scaling
【最佳实践系列】通过AppFlow,支持飞书机器人调用百炼应用
本文介绍了如何创建并配置飞书应用及机器人,主要包括三个步骤:1. 登录飞书开发者后台,创建企业自建应用并添加机器人卡片和API权限;2. 创建AppFlow连接流,配置飞书平台凭证和百炼鉴权凭证,发布
基于阿里百炼的DeepSeek-R1满血版模型调用【零门槛保姆级2084小游戏开发实战】
本文介绍基于阿里百炼的DeepSeek-R1满血版模型调用,提供零门槛保姆级2048小游戏开发实战。文章分为三部分:定位与核心优势、实战部署操作指南、辅助实战开发。通过详细步骤和案例展示,帮助开发者高

DeepSeek个人站点一键部署流程演示

Flink CDC任务从savepoint/checkpoints状态中恢复作业错误问题
flink CDC任务监听mysql数据。只要不是从savepoint/checkpoint中恢复都是能成功运行并监听数据的但是只要从savepoint/checkpoint中恢复作业就会报如下错误
人人懂AI之从机器学习到大模型
本书面向广大IT从业者,作者将尽可能通俗易懂的把机器学习、深度学习、神经网络等基本原理讲解清楚,并分享大语言模型、知识库等当下很火爆的AIGC应用,探讨大语言模型“知识茧房”问题及解法。期望本书能成为

快来零门槛、即刻拥有 DeepSeek-R1 满血版
随着人工智能技术的发展,DeepSeek作为一款新兴推理模型,凭借强大的技术实力和广泛的应用场景崭露头角。本文基于阿里云提供的零门槛解决方案,评测DeepSeek的部署与使用。该方案支持多模态任务,涵
lmstudio拉起qwq-32b-q3_k_m.gguf模型报错?
我在modelscope下载了qwq-32b-q3_k_m.gguf模型用lmstudio拉起后发现prompt配置里的模版jinja报错解析 Jinja 模板失败: Parser Error: E
AI网关代理LLMs最佳实践
随着 DeepSeek R1 的横空出世,又一次点燃了原本已经有点冷淡的大语言模型市场和话题,并且快速成为了现象级,各个行业,各个企业又都开启了新一轮的 AI 赋能/改进业务的浪潮。在 AI 普惠的过

Serverless+AI 轻松玩转高频 AIGC 场景
本书旨在整理和介绍函数计算如何构建各类 AI 应用,以及如何基于函数计算结合其他云产品来部署各种 AI 大模型。主要内容包括:【构建个人专属AI助手】【AI生图】、【AI内容创作】、【打造多形态全天候

阿里云百炼已上线超强推理开源模型QwQ-32B,尺寸更小,性能比肩DeepSeek满血版
通义千问团队推出了320亿参数的QwQ-32B模型,通过大规模强化学习和多阶段训练,在数学、编程及通用能力上达到或超越了DeepSeek-R1等先进模型。QwQ-32B模型已在阿里云百炼上线,支持AP
模型上新!来通义灵码体验 QwQ-32B 推理模型!
今天,阿里云发布并开源全新的推理模型通义千问QwQ-32B。通过大规模强化学习,千问QwQ-32B在数学、代码及通用能力上实现质的飞跃,整体性能比肩DeepSeek-R1。在保持强劲性能的同时,千问Q
指南:Claude 3.7 怎么样?国内如何使用Claude 3.7 Sonnet?
本文主要介绍了Claude 3.7 Sonnet模型的发布教你如何订阅使用Claude 3.7 Sonnect及其新功能,特别是Claude Code工具的推出。
Docker Desktop 4.38 安装与配置全流程指南(Windows平台)
Docker Desktop 是容器化应用开发与部署的一体化工具,支持本地创建、管理和运行 Docker 容器。4.38 版本新增 GPU 加速、WSL 2 性能优化和 Kubernetes 1.28
高效部署通义万相Wan2.1:ComfyUI文生/图生视频实战,工作流直取!
通义万相Wan2.1开源不到一周,已登顶HuggingFace Model 和 Space 榜双榜首,在HuggingFace和ModelScope平台的累计下载量突破100万次,社区热度持续攀升!为
快速调用 Deepseek API!【超详细教程】
Deepseek 强大的功能,在本教程中,将指导您如何获取 DeepSeek API 密钥,并演示如何使用该密钥调用 DeepSeek API 以进行调试。
云上一键部署通义千问 QwQ-32B 模型,阿里云 PAI 最佳实践
3月6日阿里云发布并开源了全新推理模型通义千问 QwQ-32B,在一系列权威基准测试中,千问QwQ-32B模型表现异常出色,几乎完全超越了OpenAI-o1-mini,性能比肩Deepseek-R1,
基于 DIFY 的自动化数据分析实战
本文介绍如何使用DIFY搭建数据分析自动化流程,实现从输入需求到查询数据库、LLM分析再到可视化输出的全流程。基于经典的employees数据集和DIFY云端环境,通过LLM-SQL解析、SQL执行、
从0到1彻底掌握Trae:手把手带你实战开发AI Chatbot,提升开发效率的必备指南!
Trae是字节跳动推出的一款免费的AI集成的开发环境,集成了Claude3.5与GPT-4o等主流AI模型,提供AI问答、智能代码生成、智能代码补全,多模态输入等功能。支持界面全中文化,为中文开发者提
还在蹲Manus的邀请码?别等了!开源版Manus为你快速创建AI工位,给AI一台电脑,然后你就玩去吧!
OpenManus 是 MetaGPT 的开源 AI 平台,支持多语言模型和工具链,执行代码、处理文件等任务,具备实时反馈。OWL 基于 CAMEL-AI,支持角色分配、任务分解和记忆功能,实现高效任

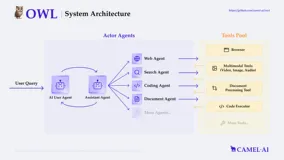
OWL:告别繁琐任务!开源多智能体系统实现自动化协作,效率提升10倍
OWL 是基于 CAMEL-AI 框架开发的多智能体协作系统,通过智能体之间的动态交互实现高效的任务自动化,支持角色分配、任务分解和记忆功能,适用于代码生成、文档撰写、数据分析等多种场景。
在ECS上使用百炼部署满血版DeepSeek R1
本文为您介绍如何在ECS实例上部署Open WebUI,并通过大模型服务平台百炼API调用DeepSeek-R1模型推理服务。帮助您快速体验满血版DeepSeek-R1模型。
本地部署DeepSeek模型
要在本地部署DeepSeek模型,需准备Linux(推荐Ubuntu 20.04+)或兼容的Windows/macOS环境,配备NVIDIA GPU(建议RTX 3060+)。安装Python 3.8
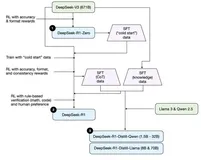
使用A10单卡24G复现DeepSeek R1强化学习过程
本文描述DeepSeek的三个模型的学习过程,其中DeepSeek-R1-Zero模型所涉及的强化学习算法,是DeepSeek最核心的部分之一会重点展示。
从零开始即刻拥有 DeepSeek-R1 满血版并使用 Dify 部署 AI 应用
本文介绍了如何使用阿里云提供的DeepSeek-R1大模型解决方案,通过Chatbox和Dify平台调用百炼API,实现稳定且高效的模型应用。首先,文章详细描述了如何通过Chatbox配置API并开始
vivo基于Paimon的湖仓一体落地实践
本文整理自vivo互联网大数据专家徐昱在Flink Forward Asia 2024的分享,基于实际案例探讨了构建现代化数据湖仓的关键决策和技术实践。内容涵盖组件选型、架构设计、离线加速、流批链路统

三分钟让Dify接入Ollama部署的本地大模型!
本文介绍了如何运行 Ollama 并在 Dify 中接入 Ollama 模型。通过命令 `ollama run qwen2:0.5b` 启动 Ollama 服务,访问 `http://localhos
阿里通义开源推理模型新王者!QwQ-32B:性能直逼671B的DeepSeek-R1
QwQ-32B 是阿里巴巴开源的新型推理模型,基于强化学习训练,具备强大的数学推理和编程能力,性能媲美更大参数量的模型。

Trae 接入 Claude 3.7:AI 编程工具界的“卷王”,完全免费使用!
Trae 是一款完全免费的AI编程工具,现已接入 Claude 3.7 模型,提供代码生成、调试等强大功能,支持多模态输入和上下文理解,用户可享受24小时高速服务,无需担心付费限制。Trae 支持多平
WhisperChain:开源 AI 实时语音转文字工具!自动消噪优化文本,效率翻倍
WhisperChain 是一款基于 Whisper.cpp 和 LangChain 的开源语音识别工具,能够实时将语音转换为文本,并自动清理和优化文本内容,适用于会议记录、写作辅助等多种场景。
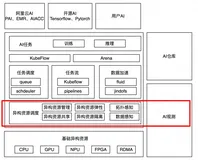
进行GPU算力管理
本篇主要简单介绍了在AI时代由‘大参数、大数据、大算力’需求下,对GPU算力管理和分配带来的挑战。以及面对这些挑战,GPU算力需要从单卡算力管理、单机多卡算力管理、多机多卡算力管理等多个方面发展出来的
零门槛、百万token免费用,即刻拥有DeepSeek-R1满血版,还有实践落地调用场景等你来看
DeepSeek 是热门的推理模型,能在少量标注数据下显著提升推理能力,尤其擅长数学、代码和自然语言等复杂任务。本文涵盖四种部署方案,可以让你快速体验云上调用 DeepSeek-R1 满血版的 API
小鱼深度评测 | 通义灵码2.0,不仅可跨语言编码,自动生成单元测试,更炸裂的是集成DeepSeek模型且免费使用,太炸裂了。
小鱼深度评测 | 通义灵码2.0,不仅可跨语言编码,自动生成单元测试,更炸裂的是集成DeepSeek模型且免费使用,太炸裂了。

深度评测 | 仅用3分钟,百炼调用满血版 Deepseek-r1 API,百万Token免费用,简直不要太爽。
仅用3分钟,百炼调用满血版Deepseek-r1 API,享受百万免费Token。阿里云提供零门槛、快速部署的解决方案,支持云控制台和Cloud Shell两种方式,操作简便。Deepseek-r1满

解锁 DeepSeek 安全接入、稳定运行新路径
聚焦于企业部署 DeepSeek 的应用需求,本文介绍了模型权重下载及多种部署方案,还阐述了大模型应用落地的常见需求,帮助用户逐步提升模型应用效果。
PostgreSQL 入门指南:安装、配置与基本命令
本文从零开始,详细介绍如何在 Windows、Linux 和 macOS 上安装和配置 PostgreSQL,涵盖30+个实操代码示例。内容包括安装步骤、配置远程访问和用户权限、基础数据库操作命令(如
《深度揭秘:分布式技术如何赋能AI与鸿蒙系统集成的性能飞跃》
在数字化时代,人工智能(AI)与鸿蒙系统的集成正推动各领域创新发展。分布式技术作为二者融合的桥梁,通过多设备协同计算和数据分布式存储,显著提升应用性能,打破性能边界,实现智能应用的新篇章。它不仅优化了
《深度解析:人工智能与鸿蒙系统集成中的版本管理与迭代升级》
在人工智能与鸿蒙系统集成开发中,版本管理和迭代升级是保障系统稳定运行和持续创新的核心环节。通过清晰的版本规则和高效的版本控制系统,确保代码、模型参数及数据文件的有序管理,奠定系统稳定性基石。迭代升级以

《探索AI与鸿蒙融合的开源宝藏:这些框架你不能错过》
人工智能(AI)与鸿蒙系统的集成开发正引领技术创新潮流,为用户带来更智能、流畅的体验。华为HiAI作为鸿蒙AI生态的核心引擎,提供计算机视觉、语音识别等多领域支持,实现设备间协同共享;TensorFl
《鸿蒙系统下AI模型训练加速:时间成本的深度剖析与优化策略》
在数字化浪潮中,鸿蒙系统以其分布式架构和强大生态潜力,为AI发展注入新活力。面对模型训练时间成本高的挑战,鸿蒙通过高效利用硬件资源、优化算法、数据处理增强及模型轻量化等手段,大幅提升训练效率与用户体验
《深度剖析:鸿蒙系统下智能NPC与游戏剧情的深度融合》
鸿蒙系统为游戏开发带来新机遇,尤其在人工智能游戏中,实现智能NPC与剧情的深度融合成为关键。通过机器学习行为模型和感知决策系统,NPC能根据玩家操作做出合理反应;结合动态剧情生成和数据驱动融合方式,使
2025年国内工单系统推荐:技术架构、场景适配与行业实践
分析了智能化升级、大数据驱动、云原生架构及全渠道融合四大技术趋势,从功能适配性、易用性、集成能力、安全性和性价比五个维度指导企业选型,并推荐合力亿捷等三家系统的优劣对比,结合电商和制造行业的实际案例,


modelscope PAI-DSW环境notebook如何选择conda管理的python?
已经按照文档安装了conda, 但notebook的kernel选择里看不到conda环境的python只能选择默认的python。这样岂不是每次重新开机后都要重新安装python库依赖。
2025年AI客服机器人推荐:核心能力与实际场景应用分析
据《2024年全球客户服务机器人行业研究报告》预测,2025年全球AI客服机器人市场规模将超500亿美元,年复合增长率达25%以上。文章分析了主流AI客服机器人,如合力亿捷等服务商的核心功能、适用场景
从第十批算法备案通过名单中分析算法的属地占比、行业及应用情况
2025年3月12日,国家网信办公布第十批深度合成算法通过名单,共395款。主要分布在广东、北京、上海、浙江等地,占比超80%,涵盖智能对话、图像生成、文本生成等多行业。典型应用包括医疗、教育、金融等
国家互联网信息办公室关于发布第十批深度合成服务算法备案信息的公告
2025年3月12日,国家网信办公布第十批深度合成算法备案信息,共395款算法通过公示。根据《互联网信息服务深度合成管理规定》,境内深度合成服务提供者和技术支持者需履行备案手续。具体信息可在中国互联网
weixin025移动学习平台的设计与实现+ssm(文档+源码)_kaic
基于微信小程序的移动学习平台旨在解决传统APP占用过多手机存储空间的问题,提升用户体验。该平台使用微信开发者工具开发前端,SSM框架和Java语言开发后台,并采用MySQL数据库保存数据。系统支持管理
weixin027校园二手平台的设计与实现+ssm(文档+源码)_kaic
本项目基于微信小程序开发校园二手交易平台,旨在解决大学生闲置物品交易问题。系统采用Java语言和MySQL数据库设计,支持用户浏览、收藏、评价商品及发布闲置物品。管理员可审核商品和用户信息,确保交易安
weixin030英语学习交流平台小程序+ssm(文档+源码)_kaic
本文介绍了英语学习交流平台小程序的开发全过程,包括系统分析、设计与实现。该小程序基于Java的SSM框架进行后端管理开发,使用MySQL作为数据库,并借助微信开发者工具确保系统稳定性。小程序设有管理员
【2025.3.12】Linkreate wordpressAI智能插件-新增自动获取搜索引擎下拉关键词,网站SEO必备,自动生成文章、配图,24小时自动发布
Linkreate WordPressAI插件是一款强大的内容生成与优化工具,支持自动化文章生成、SEO优化、长尾关键词生成及管理。具备多语言支持、搜索引擎下拉关键词获取、内容采集、定时任务自动化等功
阿里云音盾起到什么样的作用?
为什么 HTTP GET 方法不使用请求体?
本指南深入探讨了为什么HTTP GET方法通常不使用请求体,解释了GET方法的主要用途及其设计原则。GET请求旨在通过URL安全、幂等地检索数据,避免因请求体带来的复杂性和潜在问题。尽管HTTP/1.
理解GET和POST区别的全面指南

利用云平台搭建个人博客
本实验旨在通过实践操作,掌握基于云计算环境的网站部署技能。 具体包括:构建环境并实现个人博客/网站的搭建,撰写实验报告,并将这份报告作为一篇博文发布在自己的博客 / 网站上。
零基础必看!Win10系统重装图文详解+安全下载链接,避坑神器
本教程详细介绍了重装Win10系统的完整流程,包括准备工作、制作启动盘、BIOS设置、系统安装、驱动安装与优化以及常见问题解决。准备工作中需确保U盘容量、下载官方镜像并备份重要数据;通过微PE工具箱制
大模型叙事下的百度智能云:比创新更重要的,是创新的扩散
DeepSeek点燃了大模型的“引线”,使其进入爆发期。短短一个多月,大模型能力不断刷新,产业上下游达成落地共识。当前大模型正从早期采用者向早期大众过渡,面临算力瓶颈这一关键挑战。百度智能云通过百舸4
SelectDB 实时分析性能突出,宝舵成本锐减与性能显著提升的双赢之旅
BOCDOP 宝舵早期基于 TiDB 构建实时数仓,随着数据量增长,在数据处理效率、OLAP 能力扩展、功能支持、成本与资源方面存在一定优化空间。**为提升数据分析能力并优化成本,宝舵引入 [Sele

宜搭实现自动计算页面所有单选组件用户所选值,并展示在页面文本组件中
背景一个用来收集评分的普通表单里面有二十个单选组件选项都是012345如何把这些单选组件的值自动加起来展示在页面的一个文本组件中。目前写了JS代码但是没有效果不知道是哪里出现问题了
[oeasy]python073_下划线在python里是什么含义_内部变量_私有变量_系统变量
本文回顾了Python中从模块导入变量和函数的方式,重点讨论了避免本地变量名冲突(local name clashes)的方法。通过`from module import variable as al
NineData社区版正式上线,支持一键本地化部署!
3月10日,玖章算术正式发布NineData社区版,这是一款免费、一键安装的数据管理解决方案,支持本地化部署,保障数据隐私与合规。它包含数据库DevOps、数据复制和数据库对比三大核心功能,适用于My


用Apifox测试Socket.IO,这也太强了
操作简单、功能完善,能高效监听事件、发送消息,还能各种配置满足不同需求。无论是个人开发还是团队协作,这都是你调试Socket.IO接口的得力助手!
CrossOver 25.0 for macOS & Linux - 领先的 Wine 解决方案
CrossOver 25.0 for macOS & Linux - 领先的 Wine 解决方案
Apifox工具让我的 Socket.IO 测试效率翻倍
用了 Apifox 测试 Socket.IO 后,我整个人都升级了!不仅操作简单到令人发指,功能还贼全面,真的是 提升开发效率的神器 !
销售易与腾讯合作,给纷享销客带来的挑战是什么?
销售易与腾讯的战略合作升级,整合了双方在CRM、社交网络、云计算和AI等领域的优势资源,形成强大协同效应。这一联盟不仅提升了销售易的产品技术和服务能力,还通过腾讯的生态体系扩大了市场覆盖和品牌影响力。
云原生成本精细化管理实践:企迈科技的成本中心建设之路
企迈实施成本中心建设的项目核心目标不仅是实现云资源的优化配置,还要为管理层提供清晰、实时的成本数据分析,帮助管理层做出更加精准的决策。通过精细化的云成本管控,逐步实现成本降低、资源合理分配和更加高效的

破局"私有化部署+项目制"困局:中国SaaS产业迎来云时代的春天
2025年全国两会的政策信号为中国的SaaS产业注入强大动力。政策强调“加快人工智能多场景应用”,警示“防止过度私有化部署+项目制”,推动SaaS模式成为企业数字化转型的核心引擎。SaaS凭借云端化、
DeepSeek 大模型在合力亿捷工单系统中的5大应用场景解析
工单系统是企业客户服务与内部运营的核心工具,传统系统在分类、派发和处理效率方面面临挑战。DeepSeek大模型通过自然语言处理和智能化算法,实现精准分类、智能分配、自动填充、优先级排序及流程优化,大幅
场景题:线上接口响应慢,应该如何排查问题?
面试中常见的接口响应慢排查题旨在考察研发人员的系统性解决问题的能力。回答时需结合业务场景(如大促、高峰期),并运用工具(Arthas、SkyWalking等)进行监控告警、链路追踪和日志分析,明确问题
CentOS U盘挂载指南
在 CentOS 中挂载 U 盘的步骤如下:1. 使用 `sudo fdisk -l` 或 `lsblk` 检测 U 盘设备(如 `/dev/sdb1`)。2. 创建挂载点 `sudo mkdir /
AI概率学预测足球大小球让球数据分析
在足球数据分析中,AI概率学预测主要用于大小球和让球盘口的分析。大小球预测通过历史数据、机器学习和实时数据动态调整进球数;让球分析则利用Elo评分等评估实力差距,结合盘口数据预测比赛结果。数据来源包括
AI直播销售奇迹:00后DeepSeek的3.3亿真相探究
近日,“00后主播借DeepSeek技术直播卖出3.3亿”的新闻引发关注。此次成功不仅得益于主播个人魅力,更离不开“交个朋友”直播间团队对AI技术的深度融合。通过DeepSeek大模型,AI在内容生成
AI双轨革命:DeepSeek与Manus
DeepSeek与Manus是当前人工智能领域的两款明星产品,技术定位和核心能力各有千秋。DeepSeek基于混合专家模型,参数达6710亿,擅长知识推理与文本生成,提供高性价比的企业级应用;Manu
Linux目录删除指南:彻底解决“Is a directory”错误
在 Linux 系统中遇到 `cannot remove 'xxx': Is a directory` 错误,是因为删除目录时未使用正确参数。解决方法包括:1) 使用 `rmdir`
阿里云个人博客外网访问中断应急指南:从安全组到日志的七步排查法
1. 检查安全组配置:确认阿里云安全组已开放HTTP/HTTPS端口,添加规则允许目标端口(如80/443),授权对象设为`0.0.0.0/0`。 2. 本地防火墙设置:确保服务器防火墙未阻止外部流量
如何使用Traceroute定位网络问题?
`Traceroute` 是网络诊断工具,用于追踪数据包从源主机到目标主机的路径,帮助定位网络延迟、路由故障或中间节点问题。常用参数包括禁用DNS解析(`-n`)、指定最大跳数(`-m`)、每跳探测包
弹性算力革命:企业级GPU云服务如何重构AI与图形处理的效能边界
企业级GPU云服务基于云计算技术,为企业提供强大的GPU资源,无需自购硬件。它广泛应用于人工智能、大数据、3D建模、动画制作、GIS及医疗影像等领域,加速深度学习训练、图形处理和科学计算,提升效率并降
网络安全防御矩阵:从云防火墙流量清洗到WAF语义分析的立体化防护
在数字化浪潮中,网络安全日益重要。云防火墙依托云计算技术,提供灵活高效的网络防护,适用于公有云和私有云环境;Web应用防火墙专注于HTTP/HTTPS流量,防范SQL注入、XSS等攻击,保护Web应用






