

阿里云开发者社区






大家在互动










综合
最新
有奖励
免费用
从零开始开发 MCP Server
本文介绍如何使用Serverless Devs CLI工具从零开发并一键部署MCP Server到阿里云函数计算(FC)。首先通过初始化MCP Server项目,完成本地代码编写,利用Node.js实
MCP 正当时:FunctionAI MCP 开发平台来了!
MCP 的价值是统一了 Agent 和 LLM 之间的标准化接口,有了 MCP Server 的托管以及开发态能力只是第一步,接下来重要的是做好 MCP 和 Agent 的集成,FunctionAI
阿里云 MCP Server 开箱即用!
本文介绍了如何通过alibaba-cloud-ops-mcp-server和MCP(Model Context Protocol)实现AI助手对阿里云资源的复杂任务操作。内容涵盖背景、准备步骤(如使用
AI 时代,为什么编程能力≠ 开发门槛
在 2.0 阶段,我们目标是实现面向任务的协同编码模式,人的主要职责转变为任务的下发、干预以及最后结果的审查。在这个过程中,人的实际工作量开始减轻,AI 工作的占比显著提升。目前的 2.0 版本是我们
智能体Agent:用自然语言重构数据开发
本文分享如何基于利用MCP协议,配置MCP Server,以调用大数据开发与治理平台DataWorks Open API搭建智能体Agent,实现通过自然语言完成数据集成与数据开发等任务。文章还介绍了

从理论到落地:MCP 实战解锁 AI 应用架构新范式
本文旨在从 MCP 的技术原理、降低 MCP Server 构建复杂度、提升 Server 运行稳定性等方面出发,分享我们的一些实践心得。
MCP 的 AI 好搭档
本文介绍了MCP(模型上下文协议)及其在AI领域的应用前景。MCP由Anthropic公司推出,通过标准化通信协议实现AI与数据源间的安全隔离,解决了传统AI应用中的数据隐私和安全问题。文章探讨了从L

领导给我3天时间汇总所有AI模块词条,结合DeepSeek,20分钟就搞定了。
本文分享了一次利用AI工具提升工作效率的实际案例。作者接到任务,需在3天内梳理公司AI模块的所有词条并以增量形式提供给项目组。为高效完成任务,作者借助DeepSeek编写了三个Node.js脚本:第一
通义灵码 Rules 库合集来了,覆盖Java、TypeScript、Python、Go、JavaScript 等
通义灵码新上的外挂 Project Rules 获得了开发者的一致好评:最小成本适配我的开发风格、相当把团队经验沉淀下来,是个很好功能……
解决方案评测|告别复杂配置!基于阿里云云原生应用开发平台CAP快速部署Bolt.diy
本文介绍了基于阿里云CAP平台快速部署Bolt.diy的全流程。Bolt.new是一款强大的无代码对话网站构建工具,其开源版本Bolt.diy虽功能强大但部署复杂。阿里云的新解决方案简化了这一过程,通
Dataphin测评:企业级数据中台的「智能中枢」与「治理引擎」
Dataphin是一款智能数据建设与治理平台,基于阿里巴巴OneData方法论,提供从数据采集、建模研发到资产治理、数据服务的全链路智能化能力。它帮助企业解决数据口径混乱、质量参差等问题,构建标准化、

首个云超算国标正式发布!
近日,我国首个云超算国家标准GB/T 45400-2025正式发布,将于今年10月实施。该标准由阿里云联合多家机构起草,为云超算在高性能计算领域的应用提供规范。云超算结合传统HPC与云计算优势,解决传
阿里云MongoDB 8.0最新发布
阿里云 MongoDB 8.0 带来了全方位的性能提升和功能优化,助力您的业务更高效、更稳定地运行! ●读写性能全面提升:读操作性能较 7.0 提升 20%-36%,写操作性能提升 35%-58%,让

阿里云短信服务使用过程中,电信和联通都能正常接收到验证码,移动却接收不到,已经一个多月了
失败原因显示为签名实名制报备问题。应运营商要求各短信发送通道需完成对应签名的实名制报备。(IB:0310)给出的建议是请检查您使用的签名是否关联真实企业实名制资质信息若未关联请尽快提交资质审核并关联
AI 应用 & AI Agent 开发新范式
应用越智能,背后的设计会越复杂。软件的本质是解决复杂性问题,MCP 虽打开了智能的创意上限,但也给后端的设计带来了无限的复杂度。本书旨在从 MCP 的技术原理、降低 MCP Server 构建复杂度、

MCP、MaxFrame与大数据技术全景解析
围绕云计算行业趋势及阿里云技术解决方案进行直播分享,动手体验云计算行业典型场景,直观感受解决方案给业务带来的变化 讲师/嘉宾简介 徐志远(远长)、刘洋(曦翎)、卢帅(卢纶)

虚拟号码关停问题
尊敬的用户, 您好由于运营商策略管控您使用的归属号段如162、165167170171开头的虚商码号将于2025-04-27 10:00:00开始关停关停后号码自动释放不可用为了避免影响您的正常使用
一键部署 Dify + MCP Server,高效开发 AI 智能体应用
本文将着重介绍如何通过 SAE 快速搭建 Dify AI 研发平台,依托 Serverless 架构提供全托管、免运维的解决方案,高效开发 AI 智能体应用。

吐血整理Bolt.diy 部署与应用攻略
Bolt.diy 是一款无需代码基础即可创建个性化网站的工具,基于阿里云函数计算 FC 和百炼大模型服务,通过自然语言交互实现全栈开发。用户只需描述需求,Bolt.diy 即可快速生成网站,支持灵活定
国内最大的MCP中文社区来了,4000多个服务等你体验
国内最大的MCP中文社区MCPServers来了!平台汇聚4000多个服务资源,涵盖娱乐、监控、云平台等多个领域,为开发者提供一站式技术支持。不仅有丰富的中文学习资料,还有详细的实战教程,如一键接入M
从零开始教你打造一个MCP客户端
Anthropic开源了一套MCP协议,它为连接AI系统与数据源提供了一个通用的、开放的标准,用单一协议取代了碎片化的集成方式。本文教你从零打造一个MCP客户端。
对话即服务:Spring Boot整合MCP让你的CRUD系统秒变AI助手
本文介绍了如何通过Model Context Protocol (MCP) 协议将传统Spring Boot服务改造为支持AI交互的智能系统。MCP作为“万能适配器”,让AI以统一方式与多种服务和数据
开源 Remote MCP Server 一站式托管来啦!
MCP Server 的实施存在着诸多挑战,特别是在认证授权、服务可靠性和可观测性方面,Higress 作为 AI 原生的 API 网关,提供了完整的开源 MCP Server 托管解决方案,实现存量
AIGC技术发展与应用实践(一文读懂AIGC)
AIGC(人工智能生成内容)是利用AI技术生成文本、图像、音频、视频等内容的重要领域。其发展历程包括初期探索、应用拓展和深度融合三大阶段,核心技术涵盖数据收集、模型训练、内容生成、质量评估及应用部署。
MCP Server 开发实战 | 大模型无缝对接 Grafana
以 AI 世界的“USB-C”标准接口——MCP(Model Context Protocol)为例,演示如何通过 MCP Server 实现大模型与阿里云 Grafana 服务的无缝对接,让智能交互
函数计算支持热门 MCP Server 一键部署
MCP(Model Context Protocol)自2024年发布以来,逐渐成为AI开发领域的实施标准。OpenAI宣布其Agent SDK支持MCP协议,进一步推动了其普及。然而,本地部署的MC
重定义数字人交互!OmniTalker:阿里推出实时多模态说话头像生成框架,音视频实现唇语级同步
阿里巴巴推出的OmniTalker框架通过Thinker-Talker架构实现文本驱动的实时说话头像生成,创新性采用TMRoPE技术确保音视频同步,支持流式多模态输入处理。


2025年阿里云域名备案流程(图文详细教程)
本文详细介绍了2025年阿里云域名备案的全流程,包括注册阿里云账号、企业实名认证、购买服务器、创建域名信息模板、购买域名、域名备案及查询备案号等步骤。通过图文结合的方式,清晰展示了每个环节的操作方法和
FastAPI开发者福音!FastAPI-MCP:将FastAPI秒变MCP服务器的开源神器,无需配置自动转换!
FastAPI-MCP是一款能将FastAPI应用端点自动转换为符合模型上下文协议(MCP)的开源工具,支持零配置自动发现接口并保留完整文档和模式定义。

C盘清理终极指南:释放宝贵空间的有效技巧
C盘空间不足?别担心!本文《C盘清理终极指南》为你提供从基础到深度的全方位清理技巧。通过系统自带工具、手动删除无用文件、专业软件分析,再到系统设置优化与应用程序管理,助你高效释放磁盘空间,提升电脑性能
MCP 正当时:FunctionAI MCP 开发平台来了!
Function AI 是基于函数计算构建的 Serverless AI 应用开发平台,基于函数计算的运行时能力上线了完整的 MCP 开发能力,您可以进入 FunctionAI 控制台,快速体验 MC
【MCP教程系列】上阿里云百炼,5分钟轻松搭建会分析,能推理,还会自动写文档的Agent
本教程介绍如何在阿里云百炼平台上,用5分钟快速搭建一个能分析、推理并自动写文档的智能体(Agent)。通过零代码方式,结合Flomo MCP应用实现AI分析与自动归档功能。主要步骤包括:开通Flomo


斯坦福黑科技让笔记本GPU也能玩转AI视频生成!FramePack:压缩输入帧上下文长度!仅需6GB显存即可生成高清动画
斯坦福大学推出的FramePack技术通过压缩输入帧上下文长度,解决视频生成中的"遗忘"和"漂移"问题,仅需6GB显存即可在普通笔记本上实时生成高清视频。

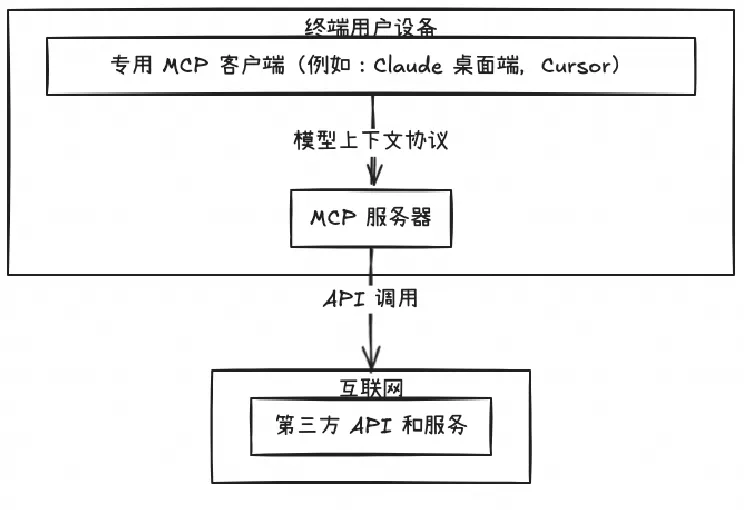
MCP详解:背景、架构与应用
模型上下文协议(MCP)是由Anthropic提出的开源标准,旨在解决大语言模型与外部数据源和工具集成的难题。作为AI领域的“USB-C接口”,MCP通过标准化、双向通信通道连接模型与外部服务,支持资

Java版Manus实现来了,Spring AI Alibaba发布开源OpenManus实现
此次官方发布的 Spring AI Alibaba OpenManus 实现,包含完整的多智能体任务规划、思考与执行流程,可以让开发者体验 Java 版本的多智能体效果。它能够根据用户的问题进行分析,

【MCP教程系列】上阿里云百炼,5分钟轻松实现查询、分析与可视化一站式解决方案
本文介绍如何在阿里云百炼平台上,通过4个简单步骤实现数据查询、分析与可视化的全流程解决方案。结合博查MCP服务和QuickChart功能,用户无需编程基础,仅需5分钟即可完成配置。

当 MCP 遇上 Serverless,AI 时代的最佳搭档
随着 AI 技术的飞速发展,MCP(模型上下文协议) 逐渐崭露头角。这项由 Anthropic 公司(Claude 的创造者)于 2024 年 11 月推出的开放协议,正在重新定义 AI 与数字世界的
这个AI能拍无限长电影!SkyReels-V2:昆仑万维开源无限时长电影生成模型!
SkyReels-V2是昆仑万维推出的突破性视频生成模型,基于扩散强迫框架和多模态大语言模型技术,支持生成理论上无限时长的连贯视频内容,在影视制作、广告创意等领域展现强大潜力。

从零开始开发 MCP Server
文章介绍了如何利用Serverless Devs CLI工具从零开发并一键部署MCP Server至阿里云函数计算(FC)。涵盖MCP协议背景、Serverless Devs工具简介、本地初始化与开发

阿里云申请SSL证书价格多少钱一年?2025免费版和付费版收费标准
阿里云SSL证书提供免费和付费版本,适合不同需求。付费证书品牌涵盖WoSign、DigiCert、GlobalSign等,类型包括DV(域名验证)、OV(企业验证)和EV(扩展验证),价格从238元/
基于 Flink 的中国电信星海时空数据多引擎实时改造
本文整理自中国电信集团大数据架构师李新虎老师在Flink Forward Asia 2024的分享,围绕星海时空智能系统展开,涵盖四个核心部分:时空数据现状、实时场景多引擎化、典型应用及未来展望。系统

PyTabKit:比sklearn更强大的表格数据机器学习框架
PyTabKit是一个专为表格数据设计的新兴机器学习框架,集成了RealMLP等先进深度学习技术与优化的GBDT超参数配置。相比传统Scikit-Learn,PyTabKit通过元级调优的默认参数设置

0 代码焦虑!阿里云 Bolt.diy 一键解锁你的专属网站,30 分钟惊艳上线
Bolt.diy 是阿里云推出的智能化建站工具,基于函数计算 FC 和百炼模型服务,通过自然语言描述即可快速生成网站。无需本地配置环境,3分钟完成部署,适合各水平用户。支持个性化定制、域名绑定及数据备

企业内训|模拟AI场景课程——某汽车厂商
4月18日和19日,东北某市,TsingtaoAI团队为某汽车厂商的智能驾驶业务和研发团队交付“模拟AI场景课程”。本课程基于该厂商在AI领域的战略布局,结合汽车行业智能化转型趋势,以“场景化、实战化
Open Avatar Chat:阿里开源实时数字人对话系统,让AI对话实现2.2秒低延迟交互
Open Avatar Chat是阿里开源的模块化数字人对话系统,支持文本/音频/视频多模态交互,采用可替换组件设计,平均响应延迟仅2.2秒,为开发者提供灵活高效的解决方案。

Cooragent:清华 LeapLab 开源 AI Agent 协作框架,一句话召唤AI军团!
Cooragent 是清华大学 LeapLab 团队推出的开源 AI Agent 协作框架,支持基于简单描述快速创建 Agent 并实现多 Agent 协作,具备 Prompt-Free 设计和本地部

LongPort MCP:证券业首个券商MCP,AI赋能智能投资新时代,散户也能玩转机构级交易
LongPort MCP是长桥集团推出的证券行业首个券商模型上下文协议,通过标准化接口实现AI与金融服务的无缝对接,支持自然语言交互的智能投资服务。

RAGEN:RL训练LLM推理新范式!开源强化学习框架让Agent学会多轮决策
RAGEN是一个基于StarPO框架的开源强化学习系统,通过马尔可夫决策过程形式化Agent与环境的交互,支持PPO、GRPO等多种优化算法,显著提升多轮推理训练的稳定性。

Apipost免费版、企业版和私有化部署详解
Apipost 是企业级 API 研发协作一体化平台,提供 API 研发、测试、管理全链路解决方案。支持多种协议(HTTP(s)、WebSocket、gRPC 等),助力团队实时协作、降本增效。免费版
告别重复繁琐!Apipost参数描述库让API开发效率飙升!
在API开发中,重复录入参数占用了42%的时间,不仅效率低下还易出错。Apipost推出的参数描述库解决了这一痛点,通过智能记忆功能实现参数自动填充,如版本号、分页控制、用户信息等常用字段,大幅减少手
告别手动填参数!Apipost黑科技让接口调试效率翻倍
参数处理是接口调试中的痛点,传统开发流程中占用了开发者大量时间。文章通过程序员小王的故事引出问题,详细介绍Apipost在动态构造接口签名、中文转义参数自动化、金融级数据安全测试和电商库存测试四个场景
12种API认证全场景解析:从Basic到OAuth2.0,哪个认证最适合你的业务?
在API认证领域,从简单的Key-Value到高级的OAuth2.0和JWT,共有12种主流认证方式。本文详解了每种方式的意义、适用场景及优劣,并通过认证方式矩阵对比常见工具(如Postman、Api
Arthas classloader (查看 classloader 的继承树,urls,类加载信息)
Arthas classloader (查看 classloader 的继承树,urls,类加载信息)
告别传统Log追踪!GOAT如何用HTTP接口重塑代码监控
本文介绍了GOAT(Golang Application Tracing)工具的使用方法,通过一个Echo问答服务实例,详细展示了代码埋点与追踪技术的应用。内容涵盖初始化配置、自动埋点、手动调整埋点、
利用 RunnerGo 深度探索 API 性能测试:从理论到实践
API性能测试是保障应用稳定性和用户体验的关键环节。本文详细探讨了如何使用RunnerGo全栈测试平台进行高效API性能测试,涵盖测试计划创建、场景设计、参数配置到执行与分析全过程。通过电商平台促销活
分享一个非常实用的在线AI工具网站
在线工具网是一个包含AI工具、站长工具、开发人员工具、实用工具、AI助手,能够提供最新AI知识库、在线编码、正则表达式、加密解密、二维码生成、在线进制转换、JSON解析格式化、JavaScript、c
OSFP MSA发布液冷标准Cage
2025年4月,阿里云基础设施网络团队提案的分离式OSFP cage,获得OSFP MSA委员会全票通过,合入OSFP MSA Rev 5.2 发布,成为行业首个支持OSFP冷板液冷的cage标准。分
RFID航空领域应用
RFID(射频识别)技术在航空领域应用广泛,涵盖行李处理、资产管理、飞机维护及航班运营等环节。通过非接触式识别和数据存储特性,RFID优化了行李托运分拣、设备监控、零部件管理及维护记录跟踪等流程,显著
抖音集团电商流量实时数仓建设实践
本文基于抖音集团电商数据工程师姚遥在Flink Forward Asia 2024的分享,围绕电商流量数据处理展开。内容涵盖业务挑战、电商流量建模架构、流批一体实践、大流量任务调优及总结展望五个部分。

无需云服务器、无需公网IP,轻松实现门禁系统远程接入与数据同步
智慧园区门禁管理中,贝锐花生壳提供高效解决方案。通过内网穿透技术,无需公网IP即可集中管理多区域门禁系统,保障数据安全传输。采用RSA与AES混合加密,支持权限精细化控制及多维度监控,简单三步实现远程
SecMulti-RAG:兼顾数据安全与智能检索的多源RAG框架,为企业构建不泄密的智能搜索引擎
本文深入解析SecMulti-RAG框架,该框架通过整合企业内部知识库、预构建专家知识及受控外部大语言模型,结合保密性过滤机制,解决企业在部署AI助手时面临的信息准确性、数据安全性和成本控制问题。它采

关于dashscope-sdk-java启动时找不到类
引入版本为2.19.2在启动时找不到Caused by: java.lang.NoClassDefFoundError: com/alibaba/dashscope/base/HalfDuplexS
宜搭表单中如何引用“数据准备”或“数据服务”中的数据?
宜搭自建应用我有一个普通表单需要从数据准备中取数据如下图所示。但是普通表单的组件没有直接关联到“数据准备”的能力。要从“数据准备”中取的数据是通过多张表单聚合得来的不能像常规用空间换时间每触发一次逻
HTTP 与 HTTPS 协议及 SSL 证书解析-http和https到底有什么区别?-优雅草卓伊凡
HTTP 与 HTTPS 协议及 SSL 证书解析-http和https到底有什么区别?-优雅草卓伊凡
40.8K star!让AI帮你读懂整个互联网:Crawl4AI开源爬虫工具深度解析
Crawl4AI 是2025年GitHub上备受瞩目的开源网络爬虫工具,专为AI时代设计。它不仅能抓取网页内容,还能理解页面语义结构,生成适配大语言模型的训练数据格式。上线半年获4万+星标,应用于12

理工科 MCP Server 神器,补足人工智能幻觉短板
本文介绍了为何需要WolframAlpha及其在解决大语言模型“幻觉”问题上的优势。大型语言模型如GPT-4虽在自然语言处理方面表现出色,但在科学与数学问题上常出错。WolframAlpha凭借其强大
《揭秘性能测试:找准系统瓶颈的实用指南》
在软件开发中,性能测试与瓶颈分析是确保系统高效稳定运行的核心手段。性能测试通过模拟真实场景评估系统在不同负载下的表现,涵盖负载、压力、并发及耐久性测试等多个方面。这些测试帮助发现系统的性能极限与潜在问
《Redis缓存:高性能数据存储的奥秘与多元应用》
Redis是一款基于内存的高性能键值对存储系统,凭借极快的读写速度成为提升应用性能的关键技术。它通过缓存热点数据减少数据库压力,结合LRU/LFU等淘汰策略优化内存使用。在电商领域,Redis加速商品
《深入理解数据库事务:掌握ACID特性的奥秘》
事务是数据库操作中确保数据一致性和完整性的核心机制,其ACID特性(原子性、一致性、隔离性、持久性)是关键保障。原子性确保操作“全有或全无”,避免部分执行导致的数据不一致;一致性维护业务逻辑和约束规则
《微服务必解之惑:分布式事务方案大揭秘》
微服务架构因灵活性与可扩展性成为企业首选,但分布式事务问题随之凸显。本文探讨了多种解决方案:两阶段提交(2PC)和三阶段提交(3PC)保证强一致性,但存在性能瓶颈;基于消息队列的最终一致性方案通过异步

