

阿里云开发者社区


































综合
最新
有奖励
免费用
1分钟集成DeepSeek满血版!搭建智能运维助手
阿里云 AI 搜索开放平台面向企业及开发者提供丰富的组件化AI搜索服务,本文将重点介绍基于AI搜索开放平台内置的 DeepSeek-R1 系列大模型,如何搭建 Elasticsearch AI Ass
OpenAI故障复盘 - 阿里云容器服务与可观测产品如何保障大规模K8s集群稳定性
聚焦近日OpenAI的大规模K8s集群故障,介绍阿里云容器服务与可观测团队在大规模K8s场景下我们的建设与沉淀。以及分享对类似故障问题的应对方案:包括在K8s和Prometheus的高可用架构设计方面
详解MySQL字符集和Collation
MySQL支持了很多Charset与Collation,并且允许用户在连接、Server、库、表、列、字面量多个层次上进行精细化配置,这有时会让用户眼花缭乱。本文对相关概念、语法、系统变量、影响范围都
大模型推理主战场:通信协议的标配
DeepSeek加速了模型平权,大模型推理需求激增,性能提升主战场从训练转向推理。SSE(Server-Sent Events)和WebSocket成为大模型应用的标配网络通信协议。SSE适合服务器单
链路诊断最佳实践:1 分钟定位错慢根因
本文聚焦于线上应用的风险管理,特别是针对“错”(程序运行不符合预期)和“慢”(性能低下或响应迟缓)两大类问题,提出了一个系统化的根因诊断方案。
产品测评 | AI编程界的集大成者——通义灵码AI程序员
通义灵码AI程序员是阿里云推出的一款基于先进自然语言处理和深度学习技术的编程助手,集成于VS Code和JetBrains IDEs中。它覆盖从前端到后端的开发流程,支持多文件级别的代码修改、单元测试
通义灵码2.0·AI程序员加持下的智能编码实践与测评
通义灵码2.0是阿里云推出的新一代智能编程助手,集成DeepSeek模型并新增多项功能,显著提升开发效率。本文通过实际项目体验新功能开发、跨语言编程、单元测试自动生成和图生代码等功能,展示其在代码生成
云产品评测|云安全这道坎,企业该怎么迈?阿里云「安全体检」实测报告
随着云计算的普及,云安全问题日益突出。阿里云提供的免费“安全体检”工具,能够自动化检测系统漏洞、风险配置和病毒攻击,帮助用户及时发现并修复潜在的安全隐患。通过实际测试,该工具在基础漏洞检测方面表现出色
VMware Workstation 17.6.3 发布下载,现在完全免费无论个人还是商业用途
VMware Workstation 17.6.3 发布下载,现在完全免费无论个人还是商业用途
阿里云短信服务使用过程中,电信和联通都能正常接收到验证码,移动却接收不到,已经一个多月了
失败原因显示为签名实名制报备问题。应运营商要求各短信发送通道需完成对应签名的实名制报备。(IB:0310)给出的建议是请检查您使用的签名是否关联真实企业实名制资质信息若未关联请尽快提交资质审核并关联
DeepSeek个人站点一键部署流程演示

阿里云产品手册2025版
阿里云作为数字经济的重要建设者,不断加深硬核科技实力,通过自身能力助力客户实现高质量发展,共创数字新世界。阿里云产品手册 2025 版含产品大图、关于阿里云、引言、AI 产品体系、安全合规等内容,覆盖

基于 DIFY 的自动化数据分析实战
本文介绍如何使用DIFY搭建数据分析自动化流程,实现从输入需求到查询数据库、LLM分析再到可视化输出的全流程。基于经典的employees数据集和DIFY云端环境,通过LLM-SQL解析、SQL执行、
人人懂AI之从机器学习到大模型
本书面向广大IT从业者,作者将尽可能通俗易懂的把机器学习、深度学习、神经网络等基本原理讲解清楚,并分享大语言模型、知识库等当下很火爆的AIGC应用,探讨大语言模型“知识茧房”问题及解法。期望本书能成为

一键部署Dify+DeepSeek On DMS,实现【联网搜索满血版】DeepSeek
一键部署 Dify + DeepSeek On DMS,开箱即用,VPC 部署,数据不出域更安全,结合夸克搜索,实现【联网搜索满血版】 DeepSeek,全方位融合阿里生态,一键开启企业 GenAI


什么是Token
Token是一种用于身份验证和授权的凭证,广泛应用于云计算、API调用、实时音视频通信等场景。它通过加密算法生成,确保请求合法性与服务安全性。Token的核心作用包括身份验证、权限控制、安全保障和无状
【自定义插件系列】0基础在阿里云百炼上玩转大模型自定义插件
本文介绍了如何在阿里云百炼平台上创建大模型自定义插件,以增强AI模型功能或适配特定需求。通过编程接口(API)或框架设计外部扩展模块,开发者可在不修改底层参数的情况下扩展模型能力。文章以万相文生图V2
大模型无缝切换,QwQ-32B和DeepSeek-R1 全都要
通义千问最新推出的QwQ-32B推理模型,拥有320亿参数,性能媲美DeepSeek-R1(6710亿参数)。QwQ-32B支持在小型移动设备上本地运行,并可将企业大模型API调用成本降低90%以上。

对话即服务:Spring Boot整合MCP让你的CRUD系统秒变AI助手
本文介绍了如何通过Model Context Protocol (MCP) 协议将传统Spring Boot服务改造为支持AI交互的智能系统。MCP作为“万能适配器”,让AI以统一方式与多种服务和数据
高效部署通义万相Wan2.1:ComfyUI文生/图生视频实战,工作流直取!
通义万相Wan2.1开源不到一周,已登顶HuggingFace Model 和 Space 榜双榜首,在HuggingFace和ModelScope平台的累计下载量突破100万次,社区热度持续攀升!为
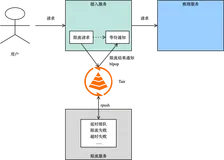
AI 推理场景的痛点和解决方案
一个典型的推理场景面临的问题可以概括为限流、负载均衡、异步化、数据管理、索引增强 5 个场景。通过云数据库 Tair 丰富的数据结构可以支撑这些场景,解决相关问题,本文我们会针对每个场景逐一说明。

让RAG更聪明,ViDoRAG开启视觉文档检索增强生成新范式,上阿里云百炼可直接体验
视觉丰富文档的高效检索与生成是自然语言处理领域的重大挑战。ViDoRAG(Visual Document Retrieval-Augmented Generation via Dynamic Iter
Docker Desktop 4.38 安装与配置全流程指南(Windows平台)
Docker Desktop 是容器化应用开发与部署的一体化工具,支持本地创建、管理和运行 Docker 容器。4.38 版本新增 GPU 加速、WSL 2 性能优化和 Kubernetes 1.28
从零开始教你打造一个MCP客户端
Anthropic开源了一套MCP协议,它为连接AI系统与数据源提供了一个通用的、开放的标准,用单一协议取代了碎片化的集成方式。本文教你从零打造一个MCP客户端。

函数计算支持热门 MCP Server 一键部署
MCP(Model Context Protocol)自2024年发布以来,逐渐成为AI开发领域的实施标准。OpenAI宣布其Agent SDK支持MCP协议,进一步推动了其普及。然而,本地部署的MC
什么是AGI
通用人工智能(AGI)指具备或超越人类智能的机器系统,能跨领域学习、推理和解决问题。其核心特点包括跨领域能力、自主学习与推理、类人思维模式及自适应性。目前AGI仍处早期阶段,但大模型和多模态技术正推动
阿里云资深架构师经验分享——DevSecOps最佳实践
本文将分享阿里云在DevSecOps中设计环节的实践经验,希望能够让大家理解阿里云是如何保障产品安全水位,并希望这些经验能够帮助到正在尝试落地DevSecOps解决方案的企业。
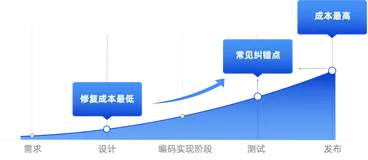
指南:Claude 3.7 怎么样?国内如何使用Claude 3.7 Sonnet?
本文主要介绍了Claude 3.7 Sonnet模型的发布教你如何订阅使用Claude 3.7 Sonnect及其新功能,特别是Claude Code工具的推出。
Agent TARS:一键让AI托管电脑!字节开源PC端多模态AI助手,无缝集成浏览器与系统操作
Agent TARS 是一款开源的多模态AI助手,能够通过视觉解析网页并无缝集成命令行和文件系统,帮助用户高效完成复杂任务。

阿里云百炼已上线超强推理开源模型QwQ-32B,尺寸更小,性能比肩DeepSeek满血版
通义千问团队推出了320亿参数的QwQ-32B模型,通过大规模强化学习和多阶段训练,在数学、编程及通用能力上达到或超越了DeepSeek-R1等先进模型。QwQ-32B模型已在阿里云百炼上线,支持AP
Heygem:开源数字人克隆神器!1秒视频生成4K超高清AI形象,1080Ti显卡也能轻松跑
Heygem 是硅基智能推出的开源数字人模型,支持快速克隆形象和声音,30秒内完成克隆,60秒内生成4K超高清视频,适用于内容创作、直播、教育等场景。
RuoYi AI:1人搞定AI中台!开源全栈式AI开发平台,快速集成大模型+RAG+支付等模块
RuoYi AI 是一个全栈式 AI 开发平台,支持本地 RAG 方案,集成多种大语言模型和多媒体功能,适合企业和个人开发者快速搭建个性化 AI 应用。

macOS Sequoia 15.4 (24E248) Boot ISO 原版可引导镜像下载
macOS Sequoia 15.4 (24E248) Boot ISO 原版可引导镜像下载

网页显示HTTP错误503怎么办?HTTP错误503解决方法
HTTP 503错误表示服务器暂时无法处理请求,通常是由于服务器过载或维护导致。常见解决方法包括:1. 等待一段时间再刷新页面;2. 检查服务器负载;3. 确认服务器是否在维护;4. 检查配置错误;5
OpenCore Legacy Patcher 2.3.0 发布,重点优化对 macOS Sequoia 15.4 的支持
OpenCore Legacy Patcher 2.3.0 发布,重点优化对 macOS Sequoia 15.4 的支持

DeepSeek一体机!飞天企业版上新“AI Stack”,支持DeepSeek满血版和Qwen单机部署!
飞天企业版上新“AI Stack”,支持DeepSeek满血版和Qwen单机部署!
阿里云百炼产品月刊【2025年3月】
2025年3月的阿⾥云百炼平台月刊突出展示了其在AI模型和服务上的显著进展。本期亮点包括推出了多个先进的多模态模型,如qwen2.5-omni-7b和视觉推理模型qvq-max系列,大幅提升了文本、图


【源码】【Java并发】【AQS】从ReentrantLock、Semaphore、CutDownLunch、CyclicBarrier看AQS源码
前言 主播觉得,AQS的原理,就是通过这2个队列的协助,实现核心功能,同步队列(CLH队列)和条件队列(Condition队列)。 同步队列(CLH队列) 作用:管理需要获...
【负荷预测】基于变分模态分解(VMD-CNN-LSTM)的短期电力负荷预测【Python】
本项目实现了一种基于变分模态分解(VMD)的短期电力负荷预测模型——VMD-CNN-LSTM。通过VMD技术将原始电力负荷数据分解为多个平稳子序列,结合温度和时间等特征构建矩阵,输入CNN-LSTM模
掌握 JSON 到表格转换:全面指南
本文探讨了将JSON转换为表格格式(如CSV、Excel)的方法,助力高效数据处理与可视化。内容涵盖Python(Pandas库)、在线工具、Excel/Google Sheets、命令行工具(jq/
Apipost vs Apifox:高效API协作的差异化功能解析
作为企业级API架构师,深度体验APIPost与Apifox后发现几大亮点功能。目录级参数配置避免全局污染;WebSocket消息分组提升长连接管理效率;Socket.IO支持解决特定协议需求;接口锁
API调用类型全面指南:理解基础知识
在数字化时代,API(应用程序编程接口)是连接不同软件应用的核心技术。掌握API调用类型对于开发高效、可扩展的系统至关重要。本文详细解析了GET、POST、PUT、DELETE等常见API请求方法,以
开发效率翻倍!Apipost这些协议调试秘籍,从HTTP到金融报文全搞定
Apipost是一款强大的API研发管理工具,支持多种协议与数据格式,包括HTTP(s)、WebSocket、SSE、gRPC、TCP及金融协议(如ISO 8583、FIX)。它内置国密算法库,提供H
AI部署架构:A100、H100、A800、H800、H20的差异以及如何选型?开发、测试、生产环境如何进行AI大模型部署架构?
AI部署架构:A100、H100、A800、H800、H20的差异以及如何选型?开发、测试、生产环境如何进行AI大模型部署架构?

基于Transformer架构的时间序列数据去噪技术研究
本文介绍了一种基于Transformer架构的时间序列去噪模型。通过生成合成数据训练,模型在不同噪声条件下展现出强去噪能力。文章详细解析了Transformer的输入嵌入、位置编码、自注意力机制及前馈

警惕勒索病毒的最新变种.weax,您需要知道的预防和恢复方法。
在数字化时代,数据安全至关重要。.weax勒索病毒以其强大的加密能力和传播手段,使用户面临严重数据损失。感染后,文件被加密、扩展名更改,导致无法访问。普通恢复工具对此无能为力。若不幸中招,建议检查备份

【LeetCode 热题100】45:跳跃游戏 II(详细解析)(Go语言版)
本文详细解析了力扣第45题“跳跃游戏II”的三种解法:贪心算法、动态规划和反向贪心。贪心算法通过选择每一步能跳到的最远位置,实现O(n)时间复杂度与O(1)空间复杂度,是面试首选;动态规划以自底向上的
Shotcut 25.03 (Linux, macOS, Windows) - 免费开源视频编辑器
Shotcut 25.03 (Linux, macOS, Windows) - 免费开源视频编辑器
LIDC-IDRI肺结节数据集分割策略
本文介绍了使用LIDC-IDRI开源数据集进行肺癌检测项目的完整流程,包括数据预处理、训练分割模型和分类模型三个主要步骤。首先,下载包含患者DICOM文件的数据集;其次,克隆预处理代码并配置Pylid

计算机视觉五大技术——深度学习在图像处理中的应用
深度学习利用多层神经网络实现人工智能,计算机视觉是其重要应用之一。图像分类通过卷积神经网络(CNN)判断图片类别,如“猫”或“狗”。目标检测不仅识别物体,还确定其位置,R-CNN系列模型逐步优化检测速

借助 serverless 将 MCP 服务部署到云端
本文介绍了如何将 MCP 服务通过 SSE 协议部署到云端,避免本地下载和启动的麻烦。首先,使用 Python 实现了一个基于 FastMCP 的网络搜索工具,并通过设置 `transport='ss

Codes 告诉你2025不可不知道的极简项目任务管理流程及实践
所谓的极简,说白了就是管理好工作事项,让人和事清晰明了,事项进度一目了然,人员的工作动态尽在掌握即可,不需要复杂的流程,事项记录清楚且方便协同就行。这种模式适合什么项目呢?适合运行期项目,运维类项目,
VM虚拟机全版本网盘+免费本地网络穿透端口映射实时同步动态家庭IP教程
本文介绍了如何通过网络穿透技术让公网直接访问家庭电脑,充分发挥本地硬件性能。相比第三方服务受限于转发带宽,此方法利用自家宽带实现更高效率。文章详细讲解了端口映射教程,包括不同网络环境(仅光猫、光猫+路
生成式人工智能认证(GAI认证)如何推动就业市场的创新?
生成式人工智能(Generative AI)认证是由全球终身学习公司Pearson推出,旨在为职场人士和学生提供全面的Gen AI技能培训。该认证涵盖方法论、提示优化、基础提示工程及伦理法律等内容,推
JeecgBoot 低代码平台 v3.7.4 发布,后台架构大升级
JeecgBoot 是一款基于 SpringBoot2.x/3.x 和 SpringCloud Alibaba 的企业级 AI 低代码平台,采用前后端分离架构(Ant Design & Vue3),支
阿里云账号注册流程,企业和个人跟着教程注册就懂了
阿里云账号注册流程企业和个人跟着教程注册就懂了阿里云账号注册流程https://help.aliyun.com/zh/account/user-guide/ali-cloud-account-reg
阿里云账号怎么注册?麻烦吗?
阿里云账号怎么注册麻烦吗注册流程https://help.aliyun.com/zh/account/user-guide/ali-cloud-account-registration-proces
阿里云服务器镜像SUSE Linux Enterprise Server是什么?
阿里云服务器镜像SUSE Linux Enterprise Server是什么为啥收费 SUSE Linux Enterprise Serverhttps://help.aliyun.com/zh
qwen-omni系列模型在设置modalities为含有语音回复时,将不再识别tools调用。
满心期待的全模态大模型qwen-omni系列(qwen-omni-7b或者qwen-omni-turbo)实际使用测试发现当设置回复类型为modalities: [text, audio]时将不会触
89.4K star!这个开源LLM应用开发平台,让你轻松构建AI工作流!
Dify 是一款开源的 LLM 应用开发平台,通过直观的可视化界面整合 AI 工作流、RAG 管道、智能代理等功能,助你快速实现从原型到生产的跨越。支持本地部署和云端服务,提供企业级功能与完整 API
this.dataSourceMap.processStart.load报错
各位老师好新手接触js在创建好远程api后使用各位老师好新接触宜搭JSthis.dataSourceMap.processStart.load出现报错Uncaught TypeError: Cann
基于Python+Vue开发的美容预约管理系统源码+运行
基于Python+Vue开发的美容预约管理系统(前后端分离),这是一项为大学生课程设计作业而开发的项目。该系统旨在帮助大学生学习并掌握Python编程技能,同时锻炼他们的项目设计与开发能力。通过学习基
【赵渝强老师】TiDB的功能特性
TiDB是由PingCAP公司自主研发的开源分布式关系型数据库,支持HTAP(混合事务与分析处理),具备一键水平扩缩容、金融级高可用、实时HTAP、云原生架构及兼容MySQL协议等核心功能。其分布式设
【工具教程】批量PDF和图片OCR识别指定区域文字自动改图片名字,多个区域一次性批量识别改名批量重命名
本内容介绍了一款用于企业档案、医院病历及办公文件管理的图片和PDF文字识别工具。通过框选识别区域,软件可批量提取关键信息,实现文件重命名或导出为表格,极大提升管理效率。支持图片与PDF两种模式,操作简
301重定向的定义与核心价值:构建数字生态的隐形桥梁
301重定向是HTTP协议中的永久性重定向状态码,当资源永久迁移时,服务器通过此技术将用户和搜索引擎引导至新地址。它不仅是技术解决方案,更是数字资产管理的核心策略。其核心价值体现在SEO权重传递、用户
阿里云服务器ECS详细购买流程【新手购买手册】
本文详细介绍了阿里云服务器ECS的购买全流程,包括付费类型、地域选择、网络及可用区配置、实例规格、镜像系统、存储设置(系统盘与数据盘)、快照服务、公网IP与带宽配置、安全组规则设定以及登录凭据设置等关
阿里云服务器配置怎么选择?
阿里云服务器配置怎么选择CPU内存、带宽和系统盘如何选择比较好 云服务器ECShttps://www.aliyun.com/product/ecs轻量应用服务器https://www.aliyun.
科研论文翻译神器!BabelDOC:开源AI工具让PDF论文秒变双语对照,公式图表全保留
BabelDOC 是一款专为科学论文设计的开源AI翻译工具,采用先进的无损解析技术和智能布局识别算法,能完美保留原文格式并生成双语对照翻译。

清华联合DeepSeek推出奖励模型新标杆!DeepSeek-GRM:让AI学会自我批评,推理性能越跑越强
DeepSeek-GRM是由DeepSeek与清华大学联合研发的通用奖励模型,采用点式生成式奖励建模和自我原则点评调优技术,显著提升了模型质量和推理扩展性。

音乐人狂喜!AbletonMCP:让AI帮你写歌,一句话生成专业编曲,Demo级作品秒出
AbletonMCP 是一个开源项目,通过模型上下文协议(MCP)将 Ableton Live 与 Claude AI 连接,实现 AI 辅助音乐制作,支持创建、修改 MIDI 和音频轨道等操作。

AI做奥赛题能及格吗?OlympicArena:上海交大推出多学科认知推理基准测试框架,挑战AI极限
OlympicArena是由上海交大等机构联合推出的多学科认知推理基准测试框架,包含7大学科11,163道奥林匹克竞赛级题目,通过细粒度评估推动AI向超级智能发展。

这个模型让AI角色会说话还会演!MoCha:Meta联手滑铁卢大学打造对话角色视频生成黑科技
MoCha是由Meta与滑铁卢大学联合开发的端到端对话角色视频生成模型,通过创新的语音-视频窗口注意力机制实现精准的唇语同步和全身动作生成。

【LeetCode 热题100】55:跳跃游戏(详细解析)(Go语言版)
本篇解析详细讲解了 LeetCode 热题 55——跳跃游戏(Jump Game)。通过判断是否能从数组起点跳至终点,介绍了两种高效解法:贪心算法和反向思维。贪心法通过维护最远可达位置 `maxRea
【LeetCode 热题100】23:合并 K 个升序链表(详细解析)(Go语言版)
本文详细解析了 LeetCode 热题 23——合并 K 个升序链表的两种解法:优先队列(最小堆)和分治合并。题目要求将多个已排序链表合并为一个升序链表。最小堆方法通过维护节点优先级快速选择最小值,;
WordPress网站服务器性能优化方法,站长必备。
最后,当你将这些方法组合起来并实施时,您将发现你的WordPress网站性能有了显著的提高。别忘了,这不是一次性的任务,要定期执行,保持你的车(网站)始终在轨道上飞驰。
XMLHttpRequest对象的GET和POST请求使用方法
这两种方式已经足够让你操控数据交流的大厨房,像一个大厨一样熟练跃动。但记住一点,每一位大厨都会依据菜品属性和食客需求选择适合的烹饪方法,GET还是POST,就看您的选择了。





