

阿里云开发者社区




























综合
最新
有奖励
免费用
一招教你轻松调用大模型来处理海量数据
本文介绍了基于MaxCompute面向Data+AI领域的产品MaxFrame。其最新发布的AI Function功能,能够实现利用大模型处理和分析海量数据。AI Function内置Qwen 2.5

DeepSeek 给 API 网关上了一波热度
API 网关并不是一个新的概念,但 DeepSeek 的全民化趋势给 API 网关上了一波热度。本文将围绕 API 网关的上下游概念、演进历程和分类、核心能力、DeepSeek 如何接入 API 网关
极速启动,SAE 弹性加速全面解读
本文将深入探讨 SAE 如何通过镜像加速、应用启动加速、CPU Burst 等核心技术手段,实现极速启动与高效运行,帮助用户构建更加稳定、高效的云端应用。
【源码】【Java并发】【ThreadLocal】适合中学者体质的ThreadLocal源码阅读
前言 下面,跟上主播的节奏,马上开始ThreadLocal源码的阅读( ̄▽ ̄)" 内部结构 如下图所示,我们可以知道,每个线程,都有自己的threadLocals字段,指向ThreadLocalMap

大模型上下文协议 MCP 带来了哪些货币化机会
本文探讨了MCP(Model-Calling Protocol)的兴起及其对AI生态的影响。自2月中旬起,MCP热度显著提升,GitHub Star和搜索指数均呈现加速增长趋势。MCP通过标准化协议连

智能运维,由你定义:SAE自定义日志与监控解决方案
通过引入 Sidecar 容器的技术,SAE 为用户提供了更强大的自定义日志与监控解决方案,帮助用户轻松实现日志采集、监控指标收集等功能。未来,SAE 将会支持 istio 多租场景,帮助用户更高效地
【自定义插件系列】用自定义插件在阿里云百炼上生成一篇图文并茂的文章
本文介绍了如何在阿里云百炼平台上利用自定义插件生成图文并茂的文章。通过大模型生成小红书风格的文章,提取关键元素生成图像提示词,结合文生图插件生成图片,并最终整合文本与图像输出给用户。整个流程包括多个步
大模型存储的 “最后一公里” :蚂蚁大模型存储加速系统 PCache 如何解决万亿参数训练难题?
本文尝试通过当前学术和工业界在大模型存储领域的关注点和相关工作,并结合蚂蚁大模型训练场景实际的需求和问题,来介绍蚂蚁是如何在多云环境里构建一套具备高可用性、高性能以及低成本的云原生 AI 存储加速系统
阿里云短信服务使用过程中,电信和联通都能正常接收到验证码,移动却接收不到,已经一个多月了
失败原因显示为签名实名制报备问题。应运营商要求各短信发送通道需完成对应签名的实名制报备。(IB:0310)给出的建议是请检查您使用的签名是否关联真实企业实名制资质信息若未关联请尽快提交资质审核并关联
人人懂AI之从机器学习到大模型
本书面向广大IT从业者,作者将尽可能通俗易懂的把机器学习、深度学习、神经网络等基本原理讲解清楚,并分享大语言模型、知识库等当下很火爆的AIGC应用,探讨大语言模型“知识茧房”问题及解法。期望本书能成为

一键部署Dify+DeepSeek On DMS,实现【联网搜索满血版】DeepSeek
一键部署 Dify + DeepSeek On DMS,开箱即用,VPC 部署,数据不出域更安全,结合夸克搜索,实现【联网搜索满血版】 DeepSeek,全方位融合阿里生态,一键开启企业 GenAI

VMware Workstation 17.6.3 发布下载,现在完全免费无论个人还是商业用途
VMware Workstation 17.6.3 发布下载,现在完全免费无论个人还是商业用途
已有云服务器Deepseek个人站点部署指导

操作系统停服应用指南
随着信息技术的快速发展,操作系统作为支撑应用程序和服务运行的基础层,承担着至关重要的角色。然而,操作系统和其他软件系统类似,都将经历生命周期的不同阶段,包括引入、增长、成熟和最终的停服。处于生命周期的

从零开始教你打造一个MCP客户端
Anthropic开源了一套MCP协议,它为连接AI系统与数据源提供了一个通用的、开放的标准,用单一协议取代了碎片化的集成方式。本文教你从零打造一个MCP客户端。
面试场景题:如何设计一个抢红包随机算法
本文详细解析了抢红包随机算法的设计与实现,涵盖三种解法:随机分配法、二倍均值法和线段切割法。随机分配法通过逐次随机分配金额确保总额不变,但易导致两极分化;二倍均值法优化了金额分布,使每次抢到的金额更均

重定义数字人交互!OmniTalker:阿里推出实时多模态说话头像生成框架,音视频实现唇语级同步
阿里巴巴推出的OmniTalker框架通过Thinker-Talker架构实现文本驱动的实时说话头像生成,创新性采用TMRoPE技术确保音视频同步,支持流式多模态输入处理。

一键部署 Dify + MCP Server,高效开发 AI 智能体应用
本文将着重介绍如何通过 SAE 快速搭建 Dify AI 研发平台,依托 Serverless 架构提供全托管、免运维的解决方案,高效开发 AI 智能体应用。
函数计算支持热门 MCP Server 一键部署
MCP(Model Context Protocol)自2024年发布以来,逐渐成为AI开发领域的实施标准。OpenAI宣布其Agent SDK支持MCP协议,进一步推动了其普及。然而,本地部署的MC
【自定义插件系列】0基础在阿里云百炼上玩转大模型自定义插件
本文介绍了如何在阿里云百炼平台上创建大模型自定义插件,以增强AI模型功能或适配特定需求。通过编程接口(API)或框架设计外部扩展模块,开发者可在不修改底层参数的情况下扩展模型能力。文章以万相文生图V2
一文掌握 MCP 上下文协议:从理论到实践
本文介绍了 模型上下文协议(Model Context Protocol,MCP),一种用于规范大型语言模型(LLM)与外部数据源及工具之间交互的开放标准。内容涵盖了 MCP 协议的整体架构(客户端与
在IDEA中借助满血版 DeepSeek 提高编码效率
通义灵码2.0引入了DeepSeek V3与R1模型,新增Qwen2.5-Max和QWQ模型,支持个性化服务切换。阿里云发布开源推理模型QwQ-32B,在数学、代码及通用能力上表现卓越,性能媲美Dee
让RAG更聪明,ViDoRAG开启视觉文档检索增强生成新范式,上阿里云百炼可直接体验
视觉丰富文档的高效检索与生成是自然语言处理领域的重大挑战。ViDoRAG(Visual Document Retrieval-Augmented Generation via Dynamic Iter
指南:Claude 3.7 怎么样?国内如何使用Claude 3.7 Sonnet?
本文主要介绍了Claude 3.7 Sonnet模型的发布教你如何订阅使用Claude 3.7 Sonnect及其新功能,特别是Claude Code工具的推出。

DreamActor-M1:字节跳动推出AI动画黑科技,静态照片秒变生动视频
DreamActor-M1是字节跳动研发的AI图像动画框架,通过混合引导机制实现高保真人物动画生成,支持多语言语音驱动和形状自适应功能。

大模型无缝切换,QwQ-32B和DeepSeek-R1 全都要
通义千问最新推出的QwQ-32B推理模型,拥有320亿参数,性能媲美DeepSeek-R1(6710亿参数)。QwQ-32B支持在小型移动设备上本地运行,并可将企业大模型API调用成本降低90%以上。

RuoYi AI:1人搞定AI中台!开源全栈式AI开发平台,快速集成大模型+RAG+支付等模块
RuoYi AI 是一个全栈式 AI 开发平台,支持本地 RAG 方案,集成多种大语言模型和多媒体功能,适合企业和个人开发者快速搭建个性化 AI 应用。

QwQ-32B一键部署,真正的0代码,0脚本,0门槛
阿里云发布的QwQ-32B模型通过强化学习显著提升了推理能力,核心指标达到DeepSeek-R1满血版水平。用户可通过阿里云系统运维管理(OOS)一键部署OpenWebUI+Ollama方案,轻松将Q
高效部署通义万相Wan2.1:ComfyUI文生/图生视频实战,工作流直取!
通义万相Wan2.1开源不到一周,已登顶HuggingFace Model 和 Space 榜双榜首,在HuggingFace和ModelScope平台的累计下载量突破100万次,社区热度持续攀升!为

DeepSeek一体机!飞天企业版上新“AI Stack”,支持DeepSeek满血版和Qwen单机部署!
飞天企业版上新“AI Stack”,支持DeepSeek满血版和Qwen单机部署!
Java版Manus实现来了,Spring AI Alibaba发布开源OpenManus实现
此次官方发布的 Spring AI Alibaba OpenManus 实现,包含完整的多智能体任务规划、思考与执行流程,可以让开发者体验 Java 版本的多智能体效果。它能够根据用户的问题进行分析,
网页显示HTTP错误503怎么办?HTTP错误503解决方法
HTTP 503错误表示服务器暂时无法处理请求,通常是由于服务器过载或维护导致。常见解决方法包括:1. 等待一段时间再刷新页面;2. 检查服务器负载;3. 确认服务器是否在维护;4. 检查配置错误;5
什么是AGI
通用人工智能(AGI)指具备或超越人类智能的机器系统,能跨领域学习、推理和解决问题。其核心特点包括跨领域能力、自主学习与推理、类人思维模式及自适应性。目前AGI仍处早期阶段,但大模型和多模态技术正推动
开源 Remote MCP Server 一站式托管来啦!
MCP Server 的实施存在着诸多挑战,特别是在认证授权、服务可靠性和可观测性方面,Higress 作为 AI 原生的 API 网关,提供了完整的开源 MCP Server 托管解决方案,实现存量
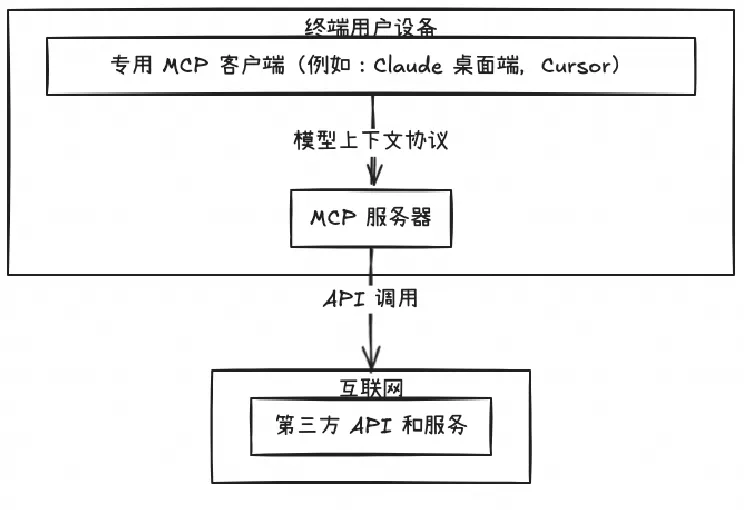
MCP 是什么?一文看懂模型上下文协议
MCP(模型上下文协议)由Anthropic于2024年推出,旨在解决AI大模型的数据滞后问题,通过连接第三方数据源提升回答的时效性和相关性。传统联网搜索依赖公开信息,难以满足行业内部或定制化需求。M
macOS Sequoia 15.4 (24E248) Boot ISO 原版可引导镜像下载
macOS Sequoia 15.4 (24E248) Boot ISO 原版可引导镜像下载

阿里云百炼产品月刊【2025年3月】
2025年3月的阿⾥云百炼平台月刊突出展示了其在AI模型和服务上的显著进展。本期亮点包括推出了多个先进的多模态模型,如qwen2.5-omni-7b和视觉推理模型qvq-max系列,大幅提升了文本、图
Dolphin:40语种+22方言!清华联合海天瑞声推出的语音识别大模型,识别精度超Whisper两代
Dolphin是清华大学与海天瑞声联合研发的语音识别大模型,支持40种东方语言和22种中文方言,采用CTC-Attention混合架构,词错率显著低于同类模型。

1分钟集成DeepSeek满血版!搭建智能运维助手
阿里云 AI 搜索开放平台面向企业及开发者提供丰富的组件化AI搜索服务,本文将重点介绍基于AI搜索开放平台内置的 DeepSeek-R1 系列大模型,如何搭建 Elasticsearch AI Ass
借助 serverless 将 MCP 服务部署到云端
本文介绍了如何将 MCP 服务通过 SSE 协议部署到云端,避免本地下载和启动的麻烦。首先,使用 Python 实现了一个基于 FastMCP 的网络搜索工具,并通过设置 `transport='ss

Heygem:开源数字人克隆神器!1秒视频生成4K超高清AI形象,1080Ti显卡也能轻松跑
Heygem 是硅基智能推出的开源数字人模型,支持快速克隆形象和声音,30秒内完成克隆,60秒内生成4K超高清视频,适用于内容创作、直播、教育等场景。
《分布式软总线:重塑应用开发工作量格局》
分布式软总线是一种颠覆性技术,显著简化了跨设备应用开发。它通过自发现、统一接口封装和连接资源管理,融合Wi-Fi、蓝牙等通信技术,让设备自动识别与连接,无需开发者深究底层细节。其异构组网能力支持多设备
《解锁分布式软总线:跨设备业务开发全攻略》
在数字化时代,分布式软总线技术作为实现设备间高效互联的核心,为跨设备业务开发提供了新可能。它通过发现、连接、组网和传输接口,打破设备通信壁垒,支持异构设备协同工作。开发者可利用这些接口设计智能应用,如
《分布式软总线:网络丢包下的数据吞吐奇迹》
网络丢包是数据传输中的常见问题,由网络拥堵、物理链路故障或设备缺陷引起,导致视频卡顿、游戏延迟等问题。分布式软总线技术通过极简协议提升传输效率,采用快速丢包恢复策略、智能感知网络变化、多通道并发传输及
《深度剖析分布式软总线:软时钟与时间同步机制探秘》
在分布式系统中,设备间的协同依赖精准的时间同步。软时钟与时间同步机制通过虚拟时钟和复杂算法,解决硬件时钟差异及网络延迟问题,确保多设备协调一致。其应用涵盖智能交通、工业自动化和金融交易等领域,为分布式
《穿透表象,洞察分布式软总线“无形”之奥秘》
分布式软总线是实现设备高效互联的核心技术,其“无形”特性区别于传统硬件总线。它通过软件定义和网络通信,实现设备自发现、自组网与跨协议融合,提供透明高效的传输体验。在智能家居和办公场景中,分布式软总线让

告别信息焦虑,用这个国产AI工具做知识管理,大脑终于解放了
文章介绍了纳米AI知识库作为“第二大脑”的强大功能。它能高效管理海量信息,支持54种文件格式上传,自动提取关键数据并打标签,轻松整合工作与生活中的碎片化信息。通过场景测试显示,在工作和生活中,纳米AI
一文拆解 YashanDB Cloud Manager,数据库运维原来还能这么“智能”!
传统数据库运维依赖人工,耗时耗力还易出错。YashanDB Cloud Manager(YCM)作为“智能运维管家”,实现主动、智能、可视化的运维体验。它提供实时资源监控、智能告警系统、自动巡检机制、
跨库迁移有多难?我们用 YashanDB YMP 做了个测试,效果惊艳了
异构数据库迁移常被视为企业数字化转型中的难题,涉及SQL兼容性、对象依赖顺序与数据一致性等关键环节。YashanDB Migration Platform(YMP)通过实际测试展示了卓越能力,从Ora

如何基于Dataphin智能研发开发“留存率”指标
用户留存率是指在互联网行业中,某段时间内新增用户中,在后续特定时间点或时间段内继续使用应用的用户比例。它是衡量应用质量和用户保留能力的重要指标。 本文为您介绍如何基于Dataphin规范建模结合SQL
数据库国产化选型?YashanDB 给中大型企业的五个答案
近两年,“国产数据库”成为企业数字化升级的重要议题。YashanDB作为新一代国产关系型数据库,以完整产品矩阵解决企业核心关切:通过图形化工具提升开发效率;提供自动化迁移平台简化数据库切换;云管理工具
一文看懂 YashanDB 四大产品,各司其职,组合更强
YashanDB包含四款核心产品,覆盖开发、迁移与运维管理全流程:DBeaver for YashanDB/YDC提供可视化开发界面,支持SQL编写与调试;YMP助力数据库迁移,涵盖评估到数据校验;Y
开发数据库不想写命令?YashanDB Developer Center 帮你轻松搞定
YashanDB Developer Center(YDC)是一款可视化的数据库开发工具,专为提升数据库开发效率而设计。它通过图形化对象管理让数据库对象清晰可见,提供智能SQL编辑器支持语法高亮与自动
开发YashanDB数据库?用 DBeaver for YashanDB 更顺手
数据库开发复杂易错,尤其在企业级场景中。为提升效率,YashanDB 团队基于 DBeaver 开源工具打造专属解决方案——DBeaver for YashanDB。它支持多类型数据库对象管理(表、视
【Function App】记录一次 "OSError: Could not find a suitable TLS CA certificate bundle" 错误
错误信息:We get an error in function app. Exception: OSError: Could not find a suitable TLS CA certifica
从告警到巡检,YashanDB Cloud Manager 帮我省下一半运维时间
数据库运维常依赖人工操作,易引发业务问题。YashanDB Cloud Manager(YCM)改变这一现状:可视化实例管理、全栈资源监控、智能巡检、灵活告警、高可用保障、权限审计体系,助企业降低故障
用 YashanDB Migration Platform,数据库迁移不再是“高风险动作”
数据库迁移一直是企业信息化中的难题,耗时长、风险高。YashanDB Migration Platform(YMP)提供一站式解决方案,涵盖评估、改写、迁移与校验全流程。其核心能力包括SQL自动适配、
aliyun-upload-sdk访问空值Bug
这段内容描述了一个代码问题:方法调用时未正确处理参数。第一个图显示方法需要传入参数,但未进行空值判断;第二个图显示调用时未传参,导致报错并使上传失败。这是典型的参数处理不当引发的运行时错误,需完善判空

Ventoy 是一款开源的多系统启动U盘工具
Ventoy是一款开源多系统启动U盘工具,支持Legacy BIOS和UEFI模式,可直接启动多个ISO文件(无需解压),兼容Windows、Linux等系统。只需下载安装Ventoy到U盘,拷贝IS
YashanDB SYSAUX表空间管理
YashanDB 的 SYSAUX 表空间是 SYSTEM 表空间的辅助表空间,作为许多特性(如快照信息)的默认存储区域。其大小由组件功能和数据库负载决定,可减少表空间数量与 SYSTEM 表空间的压
YashanDB SYSTEM表空间管理
YashanDB的SYSTEM表空间是数据库创建时生成的必需管理表空间,包含数据字典、管理信息的表和视图以及已编译存储对象(如触发器、过程和包)。它无法重命名或删除,且操作需高级权限。本文介绍了如何为

YashanDB归档日志文件管理
本文介绍了YashanDB中归档日志文件的管理,包括默认存储路径($YASDB_DATA/archive)和文件命名规则。单机部署格式为arch_{resetlogs_id}_{sequence}.A
YashanDB redo日志文件管理
YashanDB的redo日志文件用于记录数据库物理日志,支持宕机重演和主备复制。 redo日志有4种状态:NEW(新创建)、CURRENT(当前写入)、ACTIVE(未归档或未写盘)和INACTIV
热门 MCP Server一键部署
本文探讨了MCP(Model Context Protocol)的发展及其云上托管的趋势。尽管MCP协议在2024年发布时未引起广泛关注,但随着Cursor和Manus等平台的集成,以及OpenAI对


数字式相位测量仪、相位差测试仪、相位测试仪、低频相位计
用于测量电力系统中电压和电流的相位差,从而计算功率因数,监测电力系统的运行状态,判断是否存在相位不平衡等故障。 时间测量:相位计可以通过测量信号的相位变化来间接测量时间。由于相位与时间存在一定的关系,
YashanDB数据文件管理
YashanDB是一款高效数据库系统,其数据文件管理根据不同部署模式有所差异。默认数据文件存于`$YASDB_DATA/dbfiles`目录(共享集群为`+DG0/dbfiles`),包含redo日志


YashanDB控制文件管理
本指南介绍了YASHANDB控制文件的管理方法,包括查看和修改控制文件路径。默认情况下,控制文件有3份拷贝(最多8份),其路径可在配置参数文件中指定。通过SQL命令或动态视图可查看现有控制文件信息。修
YashanDB异构数据库链接配置
本指南介绍在YashanDB中配置异构数据库链接(DBLINK)的方法,特别是连接至Oracle数据库的前置要求与步骤。需确保YashanDB服务端安装plugin插件包、Oracle Instant
YashanDB数据库托管
YashanDB提供数据库托管功能,可将单节点或集群数据库迁移至指定集群内运行。操作需借助`yasboot`工具完成,包括生成配置文件、部署主库、初始化组件、修改托管配置及执行托管命令等步骤。适用于单
YashanDB数据库删除
本内容介绍了在YashanDB中删除数据库实例的操作方法。通过`DROP DATABASE`语句可删除数据库的所有数据文件,但该语句不适用于分布式部署。操作前需确保数据库处于NOMOUNT模式,且仅支
YashanDB配置参数文件与密码文件管理
YashanDB在安装时会生成两个关键文件:配置参数文件(yasdb.ini)和密码文件(yasdb.pwd)。前者存储数据库系统配置参数,位于$YASDB_DATA/config路径下,修改参数建议
YashanDB操作系统身份认证配置
本文来自YashanDB官网,主要介绍如何配置操作系统身份认证,帮助数据库管理员便捷登录。功能由`yasdb_net.ini`文件中的`ENABLE_LOCAL_OSAUTH`参数控制,默认值为`on
YashanDB TLCP连接配置
YashanDB的TLCP连接通过GmSSL工具生成的证书实现客户端与服务端的安全验证。服务器开启TLCP后,所有客户端需正确配置证书才能连接,且该功能与用户密码认证无关。文档详细说明了服务端和客户端
YashanDB分布式节点间SSL连接配置
本文介绍YashanDB分布式节点间SSL连接配置方法,确保通信安全。需统一为整个集群配置SSL,使用相同根证书签名的服务器证书,否则可能导致连接失败或数据库无法启动。文章详细说明了使用OpenSSL
YashanDB HA节点间SSL连接配置
本指南介绍HA内部节点链路的SSL连接配置,包括客户端监听与HA节点自身监听两种方式。需使用OpenSSL工具生成证书,具体步骤参考数据库服务端SSL连接配置文档。此外,还需在数据库中开启HA的SSL

YashanDB数据库服务端SSL连接配置
YashanDB支持通过SSL连接确保数据传输安全,需在服务端生成根证书、服务器证书及DH文件,并将根证书提供给客户端以完成身份验证。服务端配置包括使用OpenSSL工具生成证书、设置SSL参数并重启
YashanDB参数配置
YashanDB的系统参数默认值基于最小配置,可能不适合生产环境,建议安装时初始化配置。参数初始化需结合业务和资源环境设定。YashanDB提供参数自适应功能,根据环境信息推荐调参配置,减少运维难度。
YashanDB字符集配置
YashanDB支持多种字符集(GBK、UTF8、GB18030、ASCII、ISO88591),可根据需求配置数据库字符集。默认安装下,服务端和Linux/JDBC客户端为UTF8,Windows客
YashanDB归档管理
YashanDB通过归档模式实现redo日志自动归档,支持数据热备份与主备同步。其核心功能包括:配置归档路径(默认$YASDB_DATA/archive)、切换归档模式(ARCHIVELOG/NOAR
YashanDB实例启停
本文介绍了YashanDB单机及分布式部署的实例启停方法,包括SQL命令与yasboot工具两种方式。数据库启动分为NOMOUNT、MOUNT和OPEN三个阶段,分别对应实例启动、加载数据库但关闭状态

卸载YashanDB服务端
本文来自YashanDB官网,主要介绍通过`yasboot`命令卸载YashanDB服务端的详细步骤。操作需在服务器安装用户(yashan)的`install`目录下执行,包括:1) 检查并关闭仲裁模
PHP-Raylib 视 频 游 戏 编 程 库
php-raylib 是基于 PHP-FFI 绑定的 raylib-v5.5 游戏开发库,让 PHP 开发者轻松实现视频游戏编程。相比仅支持 4.+ 版本的原库,本项目适配最新 5.5 版本,并提供友






