索引维护是数据库日常维护中一项重要的任务,SQL Server的索引维护其实主要围绕下面三个问题进行展开。
本文同样从这3个角度出发,介绍一些实用的日常维护方法和工具。
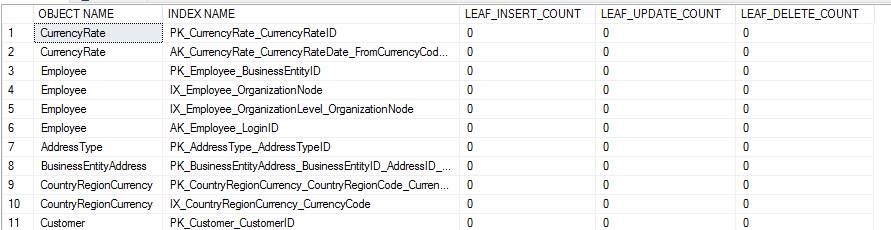
通过下面两个DMV,定期检查索引使用率,通过使用率决定是否需要该索引。sys.dm_db_index_operational_stats这个函数可以给出某个索引上面的insert,update和delete的操作情况。sys.dm_db_index_usage_stats这个视图可以给出访问索引的所有方法的操作概览。
SQL Server提供下面4个DMV以供查询missing index的情况。SQL Server重启后,系统视图中的内容就会更新,需要定期的将该信息保存下来。
下面语句,在每个库上面执行下面的查询,查看推荐建立的索引,包括创建语句。不过在创建索引前,需要综合考量表中已有的索引,是否有可以合并的情况。
当索引碎片大于5%,小于等于30%时,建议reorganize该索引;当索引碎片率大于30%时,建议rebuild该索引。Rebuild Index比较耗性能,建议在非工作时间进行,同时,建议使用online 的方式来rebuild index,以减少锁的申请量。
- 索引过多
- 索引不足
- 索引碎片率
本文同样从这3个角度出发,介绍一些实用的日常维护方法和工具。
索引过多
索引过多是指每个表上面的非聚集索引很多,并且有些非聚集索引很少用到。 过多的索引,会导致增删数据的效率降低,数据库体积变大,索引以及统计信息的维护成本增加等负面影响,建议定期检查类似的索引,每个表上面的索引最好不要超过10个。通过下面两个DMV,定期检查索引使用率,通过使用率决定是否需要该索引。sys.dm_db_index_operational_stats这个函数可以给出某个索引上面的insert,update和delete的操作情况。sys.dm_db_index_usage_stats这个视图可以给出访问索引的所有方法的操作概览。
--sys.dm_db_index_operational_stats
SELECT OBJECT_NAME(A.[OBJECT_ID]) AS [OBJECT NAME],
I.[NAME] AS [INDEX NAME],
A.LEAF_INSERT_COUNT,
A.LEAF_UPDATE_COUNT,
A.LEAF_DELETE_COUNT
FROM SYS.DM_DB_INDEX_OPERATIONAL_STATS (NULL,NULL,NULL,NULL ) A
INNER JOIN SYS.INDEXES AS I
ON I.[OBJECT_ID] = A.[OBJECT_ID]
AND I.INDEX_ID = A.INDEX_ID
WHERE OBJECTPROPERTY(A.[OBJECT_ID],'IsUserTable') = 1--sys.dm_db_index_usage_stats
SELECT OBJECT_NAME(S.[OBJECT_ID]) AS [OBJECT NAME],
I.[NAME] AS [INDEX NAME],
USER_SEEKS,
USER_SCANS,
USER_LOOKUPS,
USER_UPDATES
FROM SYS.DM_DB_INDEX_USAGE_STATS AS S
INNER JOIN SYS.INDEXES AS I
ON I.[OBJECT_ID] = S.[OBJECT_ID]
AND I.INDEX_ID = S.INDEX_ID
WHERE OBJECTPROPERTY(S.[OBJECT_ID],'IsUserTable') = 1 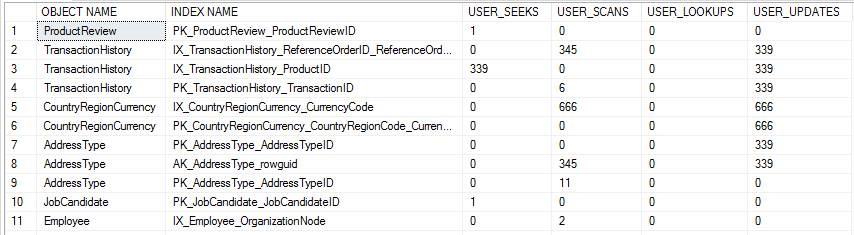
索引不足
索引不足是指,要么缺少索引,要么有索引,但是没有覆盖所需的列,查询效果不好。 后者其实也可以归纳到索引不合适中。那么我们来看下,如何才能找到缺失的索引。SQL Server提供下面4个DMV以供查询missing index的情况。SQL Server重启后,系统视图中的内容就会更新,需要定期的将该信息保存下来。
- sys.dm_db_missing_index_details 返回缺失的索引的详细信息。
- sys.dm_db_missing_index_group_stats 返回缺失索引组的概要信息。
- sys.dm_db_missing_index_groups 返回缺失索引组中有哪些缺失的索引。
- sys.dm_db_missing_index_columns 返回表中缺失索引的列。
下面语句,在每个库上面执行下面的查询,查看推荐建立的索引,包括创建语句。不过在创建索引前,需要综合考量表中已有的索引,是否有可以合并的情况。
Use DB
SELECT
dm_mid.database_id AS DatabaseID,
dm_migs.avg_user_impact*(dm_migs.user_seeks+dm_migs.user_scans) Avg_Estimated_Impact,
dm_migs.last_user_seek AS Last_User_Seek,
OBJECT_NAME(dm_mid.OBJECT_ID,dm_mid.database_id) AS [TableName],
'CREATE INDEX [IX_' + OBJECT_NAME(dm_mid.OBJECT_ID,dm_mid.database_id) + '_'
+ REPLACE(REPLACE(REPLACE(ISNULL(dm_mid.equality_columns,''),', ','_'),'[',''),']','') +
CASE
WHEN dm_mid.equality_columns IS NOT NULL AND dm_mid.inequality_columns IS NOT NULL THEN '_'
ELSE ''
END
+ REPLACE(REPLACE(REPLACE(ISNULL(dm_mid.inequality_columns,''),', ','_'),'[',''),']','')
+ ']'
+ ' ON ' + dm_mid.statement
+ ' (' + ISNULL (dm_mid.equality_columns,'')
+ CASE WHEN dm_mid.equality_columns IS NOT NULL AND dm_mid.inequality_columns IS NOT NULL THEN ',' ELSE
'' END
+ ISNULL (dm_mid.inequality_columns, '')
+ ')'
+ ISNULL (' INCLUDE (' + dm_mid.included_columns + ')', '') AS Create_Statement
FROM sys.dm_db_missing_index_groups dm_mig
INNER JOIN sys.dm_db_missing_index_group_stats dm_migs
ON dm_migs.group_handle = dm_mig.index_group_handle
INNER JOIN sys.dm_db_missing_index_details dm_mid
ON dm_mig.index_handle = dm_mid.index_handle
WHERE dm_mid.database_ID = DB_ID()
ORDER BY Avg_Estimated_Impact DESC
GO 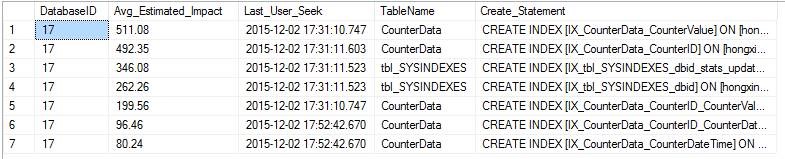
创建index时,推荐按照下述顺序进行。
- 将相等数据行列在最前
- 将不相等的数据行列在相等的数据行后
- 将include数据行列在create index语句的include子句中
- 若要决定相等数据行的顺序,依据选择性排列这些数据行,将选择性最高的数据行排在最前
索引碎片率
新增、删除和修改数据时,数据库会自动维护索引。但时间长了之后,这些操作会造成数据不连续。这会对查找性能产生影响。
首先,观察索引碎片的严重程度。
内部不连续(Internal Fragmentation):数据页中有很多空闲空间;
外部不连续(External Fragmentation):
- 硬盘中摆放的分页或区不连续,也就是数据表或索引散落在多个范围中,以及存放数据表或者索引的页不是按照实例连续存放的。
- 逻辑数据顺序和实例在硬盘中的顺序不同。
create index idCreditCard on CreditCard(CreditCardID) with drop_existing
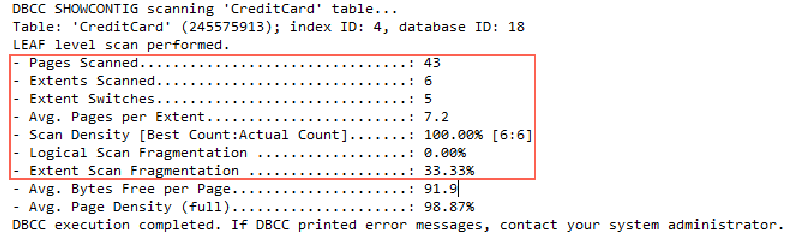
DBCC showcontig(CreditCard,idCreditCard)红框中的参数反应外部不连续状况。索引idCreditCard总共用了43页,6个区,光标扫描区时转换了5次,每个区平均7.2页,扫描密度100%,逻辑扫描片段为0,区扫描碎片率33.33% (=读取时跳过的区数/总共使用的区数)。
最后两个参数Avg. Bytes Free per Page和Avg. Page Density (full)则反应的是内部不连续的情况,平均每页空闲字节数越大,说明内部不连续越严重。
可以通过定义一个临时表来观察数据不连续情况。
--BDCC Showcontig to show the fragmentation of table or index
create table #fraglist
(
objectName char (255),
objectID int,
IndexName char(255),
IndexID int,
Lvl int,
countPages int,
countRows int,
MinRecSize int,
MaxRecSize int,
AvgRecSize int,
ForRecSize int,
Extents int,
ExtentSwitches int,
AvgFreeBytes int,
AvgPageDensity int,
ScanDensity decimal,
BestCount int,
ActualCount int,
LogicalFrag decimal,
ExtentFrag decimal
)
insert #fraglist exec('DBCC showcontig(CreditCard,idCreditCard) with tableresults')
select * from #fraglist2. 通过sys.dm_db_index_physical_stats 观察数据不连续情况
查看Department表的索引不连续情况:
select a.index_id,name,avg_fragmentation_in_percent from sys.dm_db_index_physical_stats
(DB_ID(),object_id(N'HumanResources.Department'),null,null,null)
as a join sys.indexes as b on a.object_id=b.object_id
and a.index_id=b.index_id;
查看数据库中所有索引的碎片情况
use DB;
SELECT OBJECT_NAME(ind.OBJECT_ID) AS TableName,
ind.name AS IndexName, indexstats.index_type_desc AS IndexType,
indexstats.avg_fragmentation_in_percent
FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, NULL) indexstats
INNER JOIN sys.indexes ind
ON ind.object_id = indexstats.object_id
AND ind.index_id = indexstats.index_id
WHERE indexstats.avg_fragmentation_in_percent > 5
ORDER BY indexstats.avg_fragmentation_in_percent DESC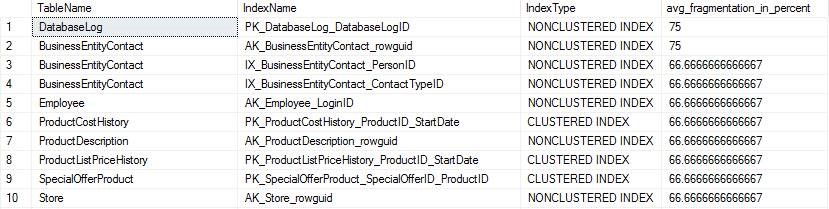
3. 根据数据片段状况来判断是否要重组或者重建索引。
当索引碎片大于5%,小于等于30%时,建议reorganize该索引;当索引碎片率大于30%时,建议rebuild该索引。Rebuild Index比较耗性能,建议在非工作时间进行,同时,建议使用online 的方式来rebuild index,以减少锁的申请量。
- 重组索引:
ALTER INDEX IX_Employee_OrganizationalLevel_OrganizationalNode ON HumanResources.Employee
REORGANIZE ;- 重建索引:
ALTER INDEX IX_TransactionHistory_TransactionDate
ON Production.TransactionHistory
REBUILD Partition = 5
WITH ( ONLINE = ON ( WAIT_AT_LOW_PRIORITY (MAX_DURATION = 10 minutes, ABORT_AFTER_WAIT = SELF )));- 维护计划重建索引

