本节书摘来自异步社区出版社《七周七数据库》一书中的第2章,第2.3节,作者: 【美】Eric Redmond,更多章节内容可以访问云栖社区“异步社区”公众号查看。
2.3 第2天:高级查询、代码和规则
七周七数据库
昨天,我们看到了如何定义数据库表,然后插入数据,更新和删除行,以及读数据。今天我们将更深入探讨PostgreSQL查询数据的各种方法。
我们将看到如何对相似的值归类,在服务器端执行代码,并使用视图(view)和规则(rule)创建自定义接口。在这一天的最后,我们将利用PostgreSQL的一个扩展包翻转表头。
2.3.1 聚合函数
聚合查询按照一些共同的标准将多行的结果分组。它可以简单到统计一张表的行数,或计算某些数值列的平均值。它们是强大的SQL工具,也很有趣。
我们来尝试一些聚合函数,但在此之前我们需要在数据库中有更多的数据。在countries表中加入你自己的国家,在cities表中加入你自己的城市,并以自己的地址作为场地(这里称为My Place),然后添加一些记录到events表中。
下面是一个简单的SQL技巧:在子查询里通过更加可读的title来获得venue_id,而不用直接给出venue_id。如果Moby(白鲸)正在Crystal Ballroom上演,可以这样设置venue_id:
INSERT INTO events (title, starts, ends, venue_id)
VALUES ('Moby', '2012-02-06 21:00', '2012-02-06 23:00', (
SELECT venue_id
FROM venues
WHERE name = 'Crystal Ballroom'
)
);
用以下数据填入events表(要在PostgreSQL里输入Valentine's Day,可以用双撇号转义,如Heaven"s Gate)。
title | starts | ends | venue
---------------------+---------------------+---------------------+-----------------
Wedding | 2012-02-26 21:00:00 | 2012-02-26 23:00:00 | Voodoo Donuts
Dinner with Mom | 2012-02-26 18:00:00 | 2012-02-26 20:30:00 | My Place
Valentine’s Day | 2012-02-14 00:00:00 | 2012-02-14 23:59:00 |
设置好数据后,我们尝试一些聚合查询。最简单的聚合函数是count(),它的意思不言自明。下面统计所有包含Day关键字的标题(注:%是LIKE搜索中的通配符),可以得到结果为3。
SELECT count(title)
FROM events
WHERE title LIKE '%Day%';
要在Crystal Ballroom发生的所有事件中,获得最早的开始时间和最晚的结束时间,就要使用min()(返回最小值)和max()(返回最大值)。
SELECT min(starts), max(ends)
FROM events INNER JOIN venues
ON events.venue_id = venues.venue_id
WHERE venues.name = 'Crystal Ballroom';
min | max
------------------------+-------------------
2012-02-06 21:00:00 | 2012-02-06 23:00:00
虽然聚合函数很有用,但只用它们是不够的。如果我们想统计每个场地的所有事件,就可以为每个场地ID写出如下语句:
SELECT count(*)FROM events WHERE venue_id = 1;
SELECT count(*)FROM events WHERE venue_id = 2;
SELECT count(*)FROM events WHERE venue_id = 3;
SELECT count(*)FROM events WHERE venue_id = IS NULL;
随着场地的数量增长,这种写法是很让人生厌的(甚至行不通)。因此需要用到GROUP BY命令。
2.3.2 分组
通过GROUP BY可以简单地完成前面查询。使用GROUP BY的时候,你告诉Postgres对行进行归类,然后对这些组执行一些聚合函数(如count())。
C`
结果看起来不错,但是能否用count()函数作为结果的过滤条件?当然可以。GROUP BY项有其自己的过滤关键字:HAVING。HAVING和WHERE子句类似,只不过它可以用聚合函数作为过滤条件(而WHERE不能)。下面的查询找出最热门的场地,它们有两个或更多事件:
C
也可以不带任何聚合函数使用GROUP BY。如果在一列上用SELECT...FROM... GROUP BY查询,就会得到所有不重复的值。SELECT venue_id FROM events GROUP BY venue_id;
这种分组归类非常常见,所以SQL有一个更为简单的命令,即DISTINCT关键词。
SELECT DISTINCT venue_id FROM events;
这两个查询的结果是相同的。
###2.3.3 窗口函数
如果你曾经在生产系统中使用过关系数据库,你应该会熟悉聚合查询。聚合查询是一种常见的SQL元素,但窗口函数却不那么常见(PostgreSQL是少数几个实现了窗口函数的开源数据库之一。)
窗口函数与GROUP BY查询是类似的,它们允许你对多行执行聚合函数。所不同的是,窗口函数允许使用内置的聚合函数,而不要求将每个字段分组成单行。
如果试图不对title列分组,却要在结果显示这个字段,将会报错。
SELECT title, venue_id, count(*)
FROM events
GROUP BY venue_id;
ERROR: column "events.title" must appear in the GROUP BY clause or \
be used in an aggregate function
要按venue_id对行计数,但是对于一个venue_id可能有两个不同的活动LARP Club和Wedding Postgres不知道要显示哪个活动名。
虽然GROUP BY子句为每个匹配的组返回一个记录,而窗口函数却可以为每行返回一个不同的记录,图2-8描述了这种关系。让我们来看一个例子,这正是窗口函数所能有效解决的场景。
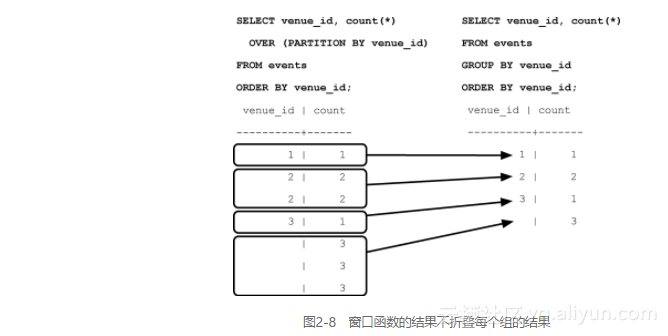
窗口函数返回所有匹配的记录,并复制所有聚合函数的结果:
SELECT title, count(*) OVER (PARTITION BY venue_id) FROM events;
我们倾向于认为PARTITION BY和GROUP BY类似,但它不会在SELECT属性列表之后,再对结果分组(从而将结果合并成较少的行),而是像其他所有字段一样返回分组的值(根据分组变量进行计算,但其他方面就是另一个属性)。或者按SQL的表达方式,它超越(OVER)结果集的分区(PARTITION),返回聚合函数的结果。
###2.3.4 事务
事务保障了关系数据库的一致性。事务的准则是,要么全部成功,要么全部失败。事务确保一组命令中的每一条命令都执行。如果过程中间发生了任何失败,所有的命令将回滚,就像它们从未发生过一样。
PostgreSQL的事务遵循ACID,它代表原子性(Atomic,所有的操作都成功或都没有做),一致性(Consistent,数据将始终处于完整的状态,没有不一致的状态),隔离性(Isolated,事务互相之间不干扰),以及持久性(Durable,即使在服务器崩溃以后,提交的事务都是安全的)。我们应该注意,ACID中的一致性不同于CAP中的一致性(附录B介绍了CAP理论)。
可以将任何事务的命令置于BEGIN TRANSACTION块内。为了验证原子性,将使用ROLLBACK命令终止事务。
BEGIN TRANSACTION;
DELETE FROM events;
ROLLBACK;
SELECT * FROM events;
event表里的所有的活动依然存在。如果要修改两个表,并希望它们保持同步,事务就很有用。最典型的例子是一个银行借记/贷记系统,其中钱从一个账户转移到另一个账户:
BEGIN TRANSACTION;
UPDATE account SET total=total+5000.0 WHERE account_id=1337;
UPDATE account SET total=total-5000.0 WHERE account_id=45887;
END;
在MySQL中的GROUP BY
在MySQL中,如果你试图SELECT一些没有在GROUP BY中限定的列,你可能会吃惊地看到,它有结果。这让我们开始怀疑窗口函数的必要性。但更细致地检查MySQL返回的数据之后,我们发现它返回的只是一些随机的数据行和计数,并非所有相关的结果。一般来说,这是没有用的(并且可能相当危险)。
不可避免的事务
到现在为止,在psql中执行的每条命令都隐式地包裹在事务中。如果你执行一条命令,如DELETE FROM account WHERE total < 20;,并且数据库在删除的中途崩溃,你不会被迫接受半张表。当你重新启动数据库服务器时,该命令将回滚。
如果在两次更新之间发生意外,这家银行就会损失5000美元。但是,如果操作放在一个事务块中,即使服务器爆炸了,最初的更新也会被回滚。
厂商锁定是什么
在关系数据库的全盛时期,厂商锁定是技术方面的瑞士军刀。可以在数据库中存储几乎任何内容,甚至用它们对整个项目编程(例如,Microsoft Access)。少数提供这个软件的公司鼓励用户使用它们专有的差异,然后利用这种公司依赖性,收取巨额的许可证和咨询费。这就是可怕的厂商锁定,在20世纪90年代和21世纪初,新的编程方法试图缓解这种情况。
然而,在他们热衷于保持厂商中立时,产生了一些准则,如“数据库中不含逻辑”。这是一种耻辱,因为关系数据库能够胜任多种不同的数据管理方式。厂商锁定并没有消失。本书探讨的许多动作与具体实现高度相关。但是,先要知道如何充分使用数据库,然后再决定是否跳过存储过程这样的工具。
###2.3.5 存储过程
到现在为止,我们看到的每条命令都是声明性的,但有时我们需要运行一些代码。这时你必须做出决定:在客户端执行代码,还是在数据库端执行代码。
存储过程可以通过巨大的架构代价来取得巨大的性能优势。使用存储过程可以避免将数千行数据发送到客户端应用程序,但也让应用程序代码与该数据库绑定,因此,不应该轻易决定使用存储过程。
先把上面的警告放在一边,来创建一个过程(或FUNCTION),它简化了向event表插入记录的工作,无需venue_id,就可以插入在某个场地举行的活动。如果场地不存在,会先创建它,并在新的事件中引用它。此外,为了用户友好,函数会返回一个布尔值,表明添加新场地是否成功。
postgres/add_event.sql
CREATE OR REPLACE FUNCTION add_event(i_title text, i_starts timestamp,
i_ends timestamp, venue text, postal varchar(9), country char(2) )
RETURNS boolean AS
$$ DECLARE did_insert boolean := false; found_count integer; the_venue_id integer; BEGIN SELECT venue_id INTO the_venue_id FROM venues v WHERE v.postal_code=postal AND v.country_code=country AND v.name ILIKE venue LIMIT 1; IF the_venue_id IS NULL THEN
选择执行数据库代码
本书将多次探讨这个主题,这是第一次:代码属于应用程序还是属于数据库?这是一个困难的决定,对每个应用程序,你都会有不同的答案。
好处是性能常常会提高一个数量级。例如,你可能有一个复杂的、应用程序相关的计算,要求自定义代码。如果计算涉及许多行数据,存储过程让你不必传输数千行数据,只要传一个结果。这样做的代价是割裂应用程序,你的代码和测试将跨越两种不同的编程范式(客户端和服务器)。INSERT INTO venues (name, postal_code, country_code)
VALUES (venue, postal, country)
RETURNING venue_id INTO the_venue_id;
did_insert := true;
END IF;
-- Note: not an"error",as in some programming languages
RAISE NOTICE 'Venue found %', the_venue_id;
INSERT INTO events (i_title, i_starts, i_ends, i_venue_id)
VALUES (title, starts, ends, the_venue_id);
RETURN did_insert;
END;
$$ LANGUAGE plpgsql;
如果你不喜欢用键盘输入所有的代码,通过以下命令行参数,可以将这个外部文件导入当前数据库。
book=# i add_event.sql
因为这是第一次使用场地Run’s House,下面的操作应该返回t(成功)。它只有一次往返,这避免了客户端SQL命令到数据库的两次往返(一次查询,然后是一次插入)。
SELECT add_event('House Party', '2012-05-03 23:00',
'2012-05-04 02:00', 'Run''s House', '97205', 'us');
在我们所写的存储过程中使用的语言是PL/pgSQL(即Procedural Language/ PostgreSQL)。全面介绍其细节超出了本书的范围,但是你可以在PostgreSQL的官方在线文档1中看到更多有关内容。
除了PL/pgSQL,PostgreSQL还支持三种更核心的语言编写程序:Tcl、Perl和Python。社区还开发了Ruby、Java、PHP、Scheme,以及官方文档列出的十多种语言的扩展模块。试试这个shell命令:
$ createlang book –-list
它会列出在你的数据库中安装的语言,createlang命令也可以用来添加新的语言。可以在线找到该命令。2
###2.3.6 触发器
当插入或更新这样的事件发生时,触发器会自动调用存储过程。它们允许数据库在数据变化的时候,强制执行一些必要的操作。
下面创建一个新的PL/pgSQL函数,当活动信息event更新的时候,都会记录相应的日志(我们想要确保没有人改变事件之后又不承认)。首先,创建一个logs表以记录活动信息的变化,这里没有必要使用主键,因为这只是日志。
CREATE TABLE logs (
event_id integer,
old_title varchar(255),
old_starts timestamp,
old_ends timestamp,
logged_at timestamp DEFAULT current_timestamp
);
接下来,创建一个函数,将更新前的数据写入日志。OLD变量代表更新前的行(我们将很快就会看到NEW代表新输入的行的值)。在返回之前,在屏幕上输出一条带event_id的信息。
postgres/log_event.sql
CREATE OR REPLACE FUNCTION log_event() RETURNS trigger AS
$$ DECLARE BEGIN INSERT INTO logs (event_id, old_title, old_starts, old_ends) VALUES (OLD.event_id, OLD.title, OLD.starts, OLD.ends); RAISE NOTICE 'Someone just changed event #%', OLD.event_id; RETURN NEW; END; $$
LANGUAGE plpgsql;
最后,创建触发器,可以在任意行更新后记录相应变更。CREATE TRIGGER log_events
AFTER UPDATE ON events
FOR EACH ROW EXECUTE PROCEDURE log_event();
现在,我们在Run’s House的聚会将比计划的提前结束。下面更新这个事件。
UPDATE events
SET ends='2012-05-04 01:00:00'
WHERE title='House Party';
NOTICE: Someone just changed event #9
而且原来的结束时间记入了日志。
SELECT event_id, old_title, old_ends, logged_at
FROM logs;
| event_id | old_title | old_ends | logged_at |
|---|---|---|---|
| 9 | House Party | 2012-05-04 02:00:00 | 2011-02-26 15:50:31.939 |
触发器还可以在更新之前以及插入之前或之后创建。3
###2.3.7 视图
如果复杂查询的结果用起来就像其他任何表一样,那岂不是太棒了?这就是VIEW的用途。与存储过程不同,它们不是执行的函数,而是查询的别名。
在我们的数据库中,所有节日都包含单词Day,并且没有场地信息。postgres/holiday_view_1.sql
CREATE VIEW holidays AS
SELECT event_id AS holiday_id, title AS name, starts AS date
FROM events
WHERE title LIKE '%Day%' AND venue_id IS NULL;
可以看到,创建视图很简单,只要在查询前面加上“CREATE VIEW some_view_name AS”。
现在,可以像查询任何其他表一样查询holidays,其后面是普通不过的events表。作为证明,向events添加2012-02-14的情人节(Valentine’s Day),并查询节日视图holidays。
SELECT name, to_char(date, 'Month DD, YYYY') AS date
FROM holidays
WHERE date <= '2012-04-01';
| name | date |
|---|---|
| April Fools Day | April 01, 2012 |
| Valentine’s Day | February 14,2012 |
视图是强大的工具,它可以以一种简单的方式访问复杂查询的数据。下面的查询可能非常复杂,但是你看到的全部只是一张表。
如果你想在视图中添加一个新列,那么,你只能修改底层的表。修改events表,使它有一组相关的颜色。
ALTER TABLE events
ADD colors text ARRAY;
因为holidays有与它们相关联的颜色组,那我们就修改视图的查询,以包含colors数组。
CREATE OR REPLACE VIEW holidays AS
SELECT event_id AS holiday_id, title AS name, starts AS date, colors
FROM events
WHERE title LIKE '%Day%' AND venue_id IS NULL;
现在要为选定的节日设置一个颜色字符串数组,但遗憾的是,我们不能直接更新视图。
UPDATE holidays SET colors = '{"red", "green"}' where name = 'Christmas Day';
ERROR: cannot update a view
HINT: You need an unconditional ON UPDATE DO INSTEAD rule.
看起来需要一条规则。
###2.3.8 规则是什么
规则是对如何修改解析过的查询树的描述。Postgres每次运行一条SQL语句,它将语句解析成查询树(一般称为抽象语法树)。
树的枝和叶是运算符和值,在执行前,树会被遍历、删减,并以其他方式修改。这棵树可以被Postgres规则重写,然后发送到查询规划器(它也以某种方式重写这棵树,以达到优化性能运行效果),最后会把最终的命令发送到执行器。参见图2-9。
需要找出的是,诸如holidays这样的视图其实就是一条规则。
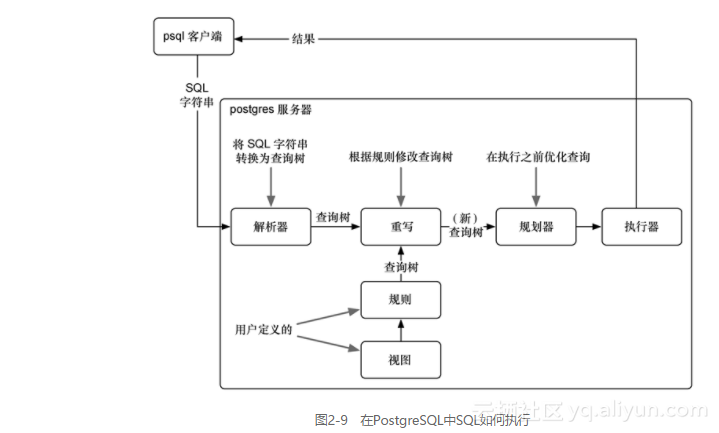
用EXPLAIN命令看一看holidays视图的执行计划,我们可以证明这一点(注意,Filter是WHERE子句,Output为列的列表)。
EXPLAIN VERBOSE
SELECT *
FROM holidays;
QUERY PLAN
Seq Scan on public.events (cost=0.00..1.04 rows=1 width=57)
Output: events.event_id, events.title, events.starts, events.colors
Filter: ((events.venue_id IS NULL)AND ((events.title)::text~~ '%Day%'::text))
如果对定义holidays视图的查询语句执行EXPLAIN VERBOSE,并和上述结果比较,我们会发现它们在功能上是等价的。
EXPLAIN VERBOSE
SELECT event_id AS holiday_id,
title AS name, starts AS date, colors
FROM events
WHERE title LIKE '%Day%' AND venue_id IS NULL;
QUERY PLAN
Seq Scan on public.events (cost=0.00..1.04 rows=1 width=57)
Output: event_id, title, starts, colors
Filter: ((events.venue_id IS NULL)AND ((events.title)::text~~ '%Day%'::text))
所以,为了允许更新holidays视图,需要定义一条规则,告诉PostgreSQL在UPDATE的时候做什么操作。规则将捕捉对holidays视图的更新,从NEW与OLD的伪关系取值,并在events上执行更新。NEW看作是包含即将更新的值的表,而OLD则是包含查询的值。
postgres/create_rule.sql
CREATE RULE update_holidays AS ON UPDATE TO holidays DO INSTEAD
UPDATE events
SET title = NEW.name,
starts = NEW.date,
colors = NEW.colors
WHERE title = OLD.name;
有了这条规则,现在可以直接更新holidays。
UPDATE holidays SET colors = '{"red","green"}' where name = 'Christmas Day';
接下来将2013-01-01的New Years Day插入holidays中。正如我们所料,这也需要一条规则。没有问题。
CREATE RULE insert_holidays AS ON INSERT TO holidays DO INSTEAD
INSERT INTO ...
我们即将讨论其他内容,但是如果你想多练习RULE的用法,可以尝试添加DELETE RULE。
###2.3.9 联表分析
作为今天最后的练习,下面将要建立一个事件月历,对一年中各月发生的事件计数。这种操作通常由一个数据透视表(pivot table)完成。这些构造以另外某种输出为“中心”,对数据分组。在例子中,中心是月份列表。我们将使用crosstab()函数创建数据透视表。
首先设计一个查询,来统计每年中每月里的事件数量。PostgreSQL提供了extract()函数,它返回日期或时间戳的某些部分,我们利用它来对事件进行归类。
SELECT extract(year from starts) as year,
extract(month from starts) as month, count(*)
FROM events
GROUP BY year, month;
为了使用crosstab(),查询必须返回三列:rowid、category和value。我们将把year作为一个ID,这意味着其他域是类别(月)和值(计数)。
crosstab()函数需要另一组值代表月。根据这组值,该函数知道需要多少列。这组值将成为列(透视所依据的表)。现在,我们创建一张表,存储临时的数字列表。CREATE TEMPORARY TABLE month_count(month INT);
INSERT INTO month_count VALUES (1),(2),(3),(4),(5),(6),(7),(8),(9),(10),(11),(12);
现在,我们准备好以两个查询来调用crosstab()。
SELECT * FROM crosstab(
'SELECT extract(year from starts) as year,
extract(month from starts) as month, count(*)
FROM events
GROUP BY year, month',
'SELECT * FROM month_count'
);
ERROR: a column definition list is required for functions returning "record"
糟糕,发生错误了。
它可能看起来神秘,其实它是在说,该函数返回一组记录(行),但不知道如何标记它们。事实上,它甚至不知道它们是什么样的数据类型。
请记住,数据透视表使用月份作为类别,但这些月份只是整数。所以,这样定义它们:
SELECT * FROM crosstab(
'SELECT extract(year from starts) as year,
extract(month from starts) as month, count(*)
FROM events
GROUP BY year, month',
'SELECT * FROM month_count'
) AS (
year int,
jan int, feb int, mar int, apr int, may int, jun int,
jul int, aug int, sep int, oct int, nov int, dec int
) ORDER BY YEAR;
有一个year列(这是行ID)和12个代表月份的列。
| year | jan | feb | mar | apr | may | jun | jul | aug | sep | oct | nov | dec | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2012 | 5 | 1 | 1 | 1 | |||||||||
| 2013 | 1 | ||||||||||||
为了要看到下一年的事件计数,在另一年里增加更多的事件。再次运行crosstab()函数,再看看你的大作。
###2.3.10 第2天总结
今天完成了PostgreSQL的基础内容。我们开始看到,PostgreSQL不仅仅是一个存储和查询简单数据类型的服务器;它还是一个数据管理引擎,可以重新格式化输出数据、存储各种数据类型(如数组)、执行逻辑,并提供足够的能力来重写传入的查询。
第2天作业
求索
1.在PostgreSQL文档中找到聚合函数列表。
2.找到一个与PostgreSQL进行交互的GUI程序,例如Navicat。
实践
1.创建一条规则,把对场地的删除,改为将active标志(在第1天作业中创建的)设置为FALSE。
2.临时表不是实现事件月历数据透视表的最好方式。`generate_series(a,b`)函数返回一组,从a到b的记录。用它来替换`month_count`表的`SELECT`。