本节书摘来自异步社区《统计会犯错——如何避免数据分析中的统计陷阱》一书中的第1章功效曲线,作者【美】Alex Reinhart(亚历克斯·莱因哈特),更多章节内容可以访问云栖社区“异步社区”公众号查看。
第2章 统计功效与低功效统计
统计会犯错——如何避免数据分析中的统计陷阱
在第1章中,你已经注意到由于没有收集足够的数据,可能会忽略那些真实的效应。例如,你拒绝了具有疗效的新药,或者忽视了重要的副作用。因此,应该收集多少数据才比较合适呢?
统计功效可以回答以上问题。一项研究的功效指的是,它能将某种强度的效应从纯粹的运气因素里区分并识别出来的概率。如果一种药物治疗作用特别明显,那么它的识别就比较容易,而如果疗效轻微,其识别往往比较困难。
功效曲线
设想我的对手有一枚不均匀的硬币。掷出这枚硬币,正面向上或反面向上的概率并不是1/2,相反,其中有一面向上的概率为60%。我和我的对手用这枚硬币赌博,他宣称这枚硬币是公平的,但是我对此强烈怀疑,我应该用什么方法来证明他在欺骗我呢?
我不能简单地连续投掷这枚硬币100次,然后以正面向上次数是否为50次来判断硬币是不是均匀的。事实上,即使是一枚均匀的硬币,也不可能恰恰是50次正面向上。正面向上次数的概率分布如图2-1所示。
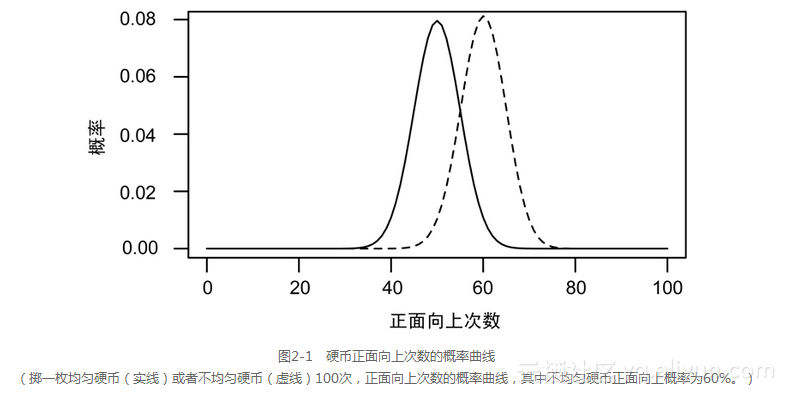
(掷一枚均匀硬币(实线)或者不均匀硬币(虚线)100次,正面向上次数的概率曲线,其中不均匀硬币正面向上概率为60%。)
对于一枚均匀硬币,正面向上50次是最可能的结果,但其发生的概率也小于10%,另外有略小的概率得到51次或52次正面向上的结果。事实上,当连续掷一枚硬币100次,正面向上次数落在[40,60]区间内的概率为95%。换句话说,在这个区间之外的可能性较低:只有1%的概率得到正面向上多于63次或少于37次的结果。正面向上90次或100次几乎是不可能的。
一枚不均匀的硬币,其正面向上的概率为60%。连续掷这枚硬币100次,所得正面向上次数的概率分布如图2-1中的虚线所示。均匀硬币的概率分布曲线和不均匀硬币的概率分布的曲线有重合的部分,但是不均匀硬币与均匀硬币相比,更有可能得到正面向上70次的结果。
我们做一点数学计算。连续投掷一枚硬币100次,然后数出正面向上的次数。如果这个次数不是50次,那么在这枚硬币是均匀硬币的假设下,计算产生该结果或者更为极端结果的概率,这个概率就是p值。如果这个p值等于或小于0.05,我们就在统计上显著地认为这枚硬币是不均匀的。
利用p值的方法,我们有多大的可能性发现一枚硬币是不均匀的?图2-2所示的功效曲线回答了这个问题。在图2-2中,横轴表示硬币正面向上的概率,表示硬币不均匀的程度,而纵轴是利用计算p值的方法,得到这枚硬币不均匀结论的概率。
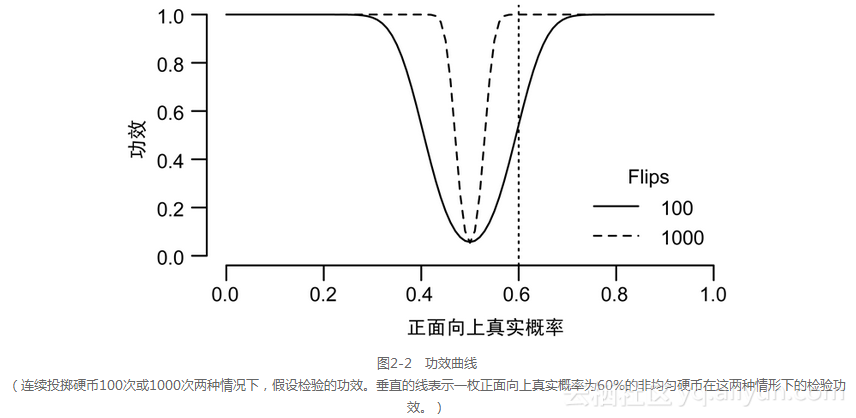
(连续投掷硬币100次或1000次两种情况下,假设检验的功效。垂直的线表示一枚正面向上真实概率为60%的非均匀硬币在这两种情形下的检验功效。)
假设检验的功效是指产生统计显著性结果(p <0.05)的概率。对于一枚均匀的硬币,40~60次正面向上的概率为95%,因此对一枚不均匀的硬币而言,检验功效就是指这枚硬币正面向上的次数落在区间(40,60)以外的概率。有3种因素可以影响检验的功效。
偏差大小。一枚硬币越不均匀,越容易被检测出来。
样本容量。如果收集足够多的样本,那么即使是细微的偏差也可以检测出来。
测量误差。在上面的例子中,你能非常容易地数出正面向上的次数,但有一些试验的指标测量非常困难,如医学研究中的疲劳感和沮丧感。
我们首先讨论偏差大小对检验功效的影响。如图2-2所示,如果一枚硬币轻微有偏,其正面向上的概率不是1/2而是60%,那么在连续投掷100次后,通过假设检验的方法得到这枚硬币是非均匀硬币结论的概率为50%,也即是说,检验功效为50%。我们有一半的机会,得到正面向上次数少于60次的结果,从而不能判断这枚硬币是非均匀硬币。这表明,仅仅依靠100次投掷数据,并不能把硬币的轻微偏倚与随机误差分割开来。只有当这枚硬币严重有偏,比如正面向上的概率为80%时,我们才能得到其为非均匀硬币的结论,此时检验功效为100%。
这里就有一个问题,即使一枚硬币是均匀的,我们仍有5%的概率得到该枚硬币不均匀的结论。我们的检验把p <0.05作为硬币不均匀的证据,但一枚均匀的硬币也可能得到p <0.05的结果。
幸运的是,增加样本容量可以提高检验功效。图2-2中的虚线说明,如果连续投掷硬币1000次,那么利用假设检验方法很容易识别出硬币是否均匀,此时检验功效明显高于投掷硬币100次时的情形。这是因为,如果连续投掷一枚均匀硬币1000次,正面向上次数位于(469,531)区间内的概率为95%,而正面向上超过600次可能性很低,一旦出现该结果就认为这枚硬币是非均匀的,一枚正面向上概率为60%的非均匀硬币却很可能得到超过600次的结果,所以也就比较容易检测出来。但不幸的是,我们没有时间连续投掷一枚硬币1000次。因此,出于实际考虑,单纯靠增加样本容量来提高检验功效是不现实的。
数出正面向上或者反面向上的次数比较容易,但对其他指标测量就没那么简单了,比如智商。由于问题不同或被测人的心情波动,每次测试的分数会发生变化,从而为智商测量添加了随机噪声因素,使测试分数不能真实反映真正的智商。如果你比较两组受试人员的智商分数,你会发现不仅不同受试者的分数具有正态变异,即使对同一名测试者,测试分数也会随机波动。如果一个测试带有较大的误差,那么统计检验的功效也会降低。
数据越多,我们越容易从噪声中区分出信号。但说起来容易做起来难,科学家没有足够的资源开展具有高功效的科学研究,来检测他们要找的信号,因此在开展研究之前他们就注定会失败。