本节书摘来自异步社区《计算机视觉度量深入解析》一书中的第1章1.3节三维深度处理,作者【美】Scott Krig(斯科特·克里格),更多章节内容可以访问云栖社区“异步社区”公众号查看。
1.3 三维深度处理
由于历史原因,在深入讨论深度感知和相关方法时,会同时涉及到一些专用词汇和它们的缩写词,所以本节会提到一些相互重叠的主题。前面的表1-1从上物理方法对深度感知进行了简要介绍。不管是哪种深度感知方法,它们之间有许多相似之处。考虑到摄像机系统的校准精度、景深的几何模型、深度数据的测量精度、深度数据中存在的任何噪声以及预期应用,深度信息的后处理是至关重要的。
本节会介绍几个深度感知的主题,这些主题之间相互关联,包括几种主题。
稀疏深度感知方法
稠密深度感知方法
光流
同步定位和映射(SLAM)
运动中恢复结构(SFM)
三维表面重建,三维表面融合
单目深度感知
立体和多视点立体(MVS)
深度感知中的共性问题
人类的深度感知依赖于一组先天和后天学习到的视觉信号,这已经超出了这项工作的范围,并且与其他几个领域(包括光学、眼科学和心理学[464])发生交叉。然而,这里会在深度感知的背景下给出上述主题的简要介绍。
1.3.1 方法概述
为了便于讨论深度处理方法,可将表1-1中的深度感知方法分为两大类。
稀疏深度感知方法。利用计算机视觉方法提取局部兴趣点和特征。仅用所选的点组合成一个稀疏的深度图或点云。当摄像机或场景移动时,一帧帧地跟踪这些特征,并不断更新稀疏点云。这种方法通常仅需要单个摄像机。
稠密深度感知方法。对每个像素计算深度。该方法使用立体视觉、TOF或MVS创建一个稠密的深度图,它可能涉及一个或多个摄像机。
许多稀疏深度感知方法使用标准的单目摄像机和计算机视觉特征跟踪方法,如光流和SLAM(在本节的后面会介绍),并通过逐帧跟踪特征描述子来计算差异性和稀疏深度。稠密深度感知方法通常是基于一个特定的深度摄像机技术,诸如立体视觉或结构化光线。当然也有例外,在后面还会提到它。
1.3.2 深度感知和处理中存在的问题
每种深度感知方法都有各自特定的问题,但它们之间也存在一些共性问题,在这里需要讨论一下。首先,一个共同的问题是景深的几何建模,该问题比较复杂,它包括透视和投影。大部分深度感知方法将整个场(field)当做一个笛卡尔坐标系,这将会带来一些小问题。摄像机传感器是一个二维欧氏模型,并且离散的体元(voxel)将在三维欧几里得空间中成像。然而,在摄像机和现实世界之间使用简单的直角坐标系来建立映射会引起几何失真。其他的问题还包括这些点之间的对应性,以及在各个帧之间的匹配失败、噪声和遮挡问题。下一节我们将会看到这些问题。
1.3.2.1 几何场和失真
几何场是一个复杂的研究领域,它会同时影响到深度感知和二维成像。对于商业应用而言,在三维精度不高的脸部定位、简单对象跟踪和增强现实等应用中并不需要,因此几何场问题并不是特别重要。然而,对于常常需要高精确度和高准确度的军事和工业应用而言,几何场就特别重要,所以需要仔细进行几何处理。为了更好地理解深度感知方法中常见的几何场问题,这里给出几个主要的领域。
射影几何的问题,用于处理透视
极坐标和球面坐标的几何问题,当视锥离观察者距离不断扩大时,便于处理透视方面的问题
由于镜头像差导致的径向畸变
坐标空间问题,它由下列原因导致:传感器与体元的直角坐标,从场景到传感器转换的光线的极坐标性质
本次讨论的目标是列举深度感知中存在的问题,并提供一些可行方法作为参考,而不是解决这些问题。由于几何方面的内容很多,这里仅仅提供一些用于深度场建模的比较好的方法。本书希望通过确认深度感知中所存在的几何问题,以便将更多的注意力放在重要的主题上。对任何深度系统而言,完整的几何模型(包括校正)都是非常复杂的。通常,在一些流行的商业应用中,高级几何的一些主题往往被忽略,但在一些高级的军事应用(如离子束武器和导弹系统)中,若给定了精度,就不会忽略这些复杂性。
一些研究人员会使用一些鲁棒性更好的非线性方法来解决射影几何问题[465,466],特别是将极坐标中几何相关的失真问题建模为三维圆柱形失真,而不是平面失真,并为校正提供合理的计算方法。此外,Lovegrove和Davison[484]的相关研究使用球形拼接的方法来处理几何场问题,以便能为深度融合对齐整幅图像,由于使用了球形建模,其精度得到提高。
1.双眼单视界区域、Panum面积和深度融合
图1-18为双眼单视区域(Horopter Region),托勒密等人在天文学的背景下首先对其进行了研究,它有一个包含三维点的弯曲表面,这些点从观察者的角度来看具有同等的距离并在同一焦平面上。Panum区域是双眼单视周围的区域,其中人的视觉系统将视网膜上的点融合成具有相同距离和焦平面的单个对象。人的视觉系统能够使得三维点之间的距离保持一致,并能合成一个共同的景深,这真是一个小小的奇迹!双眼单视区域和Panum区域所面临的挑战为,任何深度算法的后处理步骤必须恰当,以便能正确地以人的视角系统融合的方式来融合那些点。误差幅度取决于一些常用变量,其中包括基线和像素分辨率,并且误差在靠近景深的边缘处最明显,而靠近中心处却不太明显。有些球形畸变是由于透镜在靠近边缘的地方会产生像差,与前面章节中讨论的早期传感器处理中的几何校正问题类似,透镜像差问题可以部分得到校正。
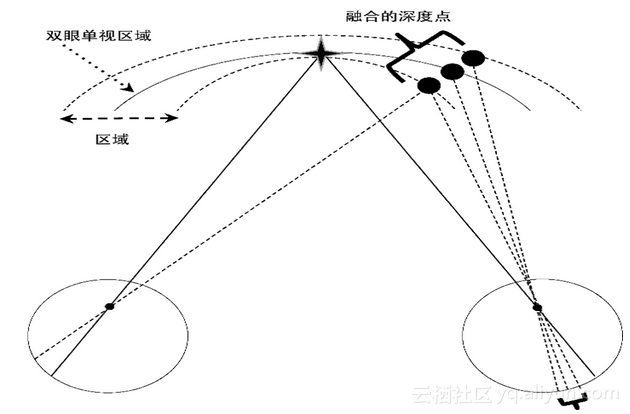
图1-18 与立体视觉和多视点立体视觉方法有关的问题,图中展示了双眼单视界区域和Panum区域,空间中的三个点从左眼的角度来看似乎是同一点,但是从右眼的角度来看却是不同的点。这三个点环绕在Panum区域中的双眼单视区域周围,人的视觉系将它融合成表面深度
2.笛卡儿坐标系和极坐标系:球形射影几何
如图1-19所示,在一个TOF或单目深度感知方法中使用的二维传感器也存在特定的几何问题,该问题在靠近视觉场的边缘显得更为突出。值得注意的是,对于传感器而言,在使用极坐标的球形坐标系统中,可度量空间中的点到像素的深度,但传感器所涉及的几何纯粹是笛卡儿几何,这必然会导致几何误差。
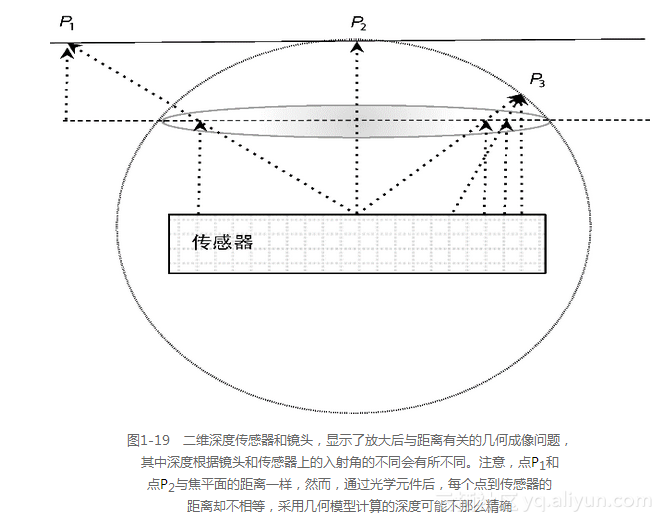
因为立体视觉和多视角立体视觉方法也使用单个的二维传感器,同样的问题不仅会影响单传感器的深度感知方法,也会影响多摄像机方法,在发展更为精确且计算上可行的几何模型时,这些困难会使问题变得更加棘手。
3.深度粒度
如图1-20所示,简单的笛卡儿深度计算方法并不能将景深分解成线性均匀的粒度大小。实际上,景深粒度会随着离传感器的距离呈指数增长,但是在更大范围内解决景深的能力却越来越不精确。
例如,假定一个具有70毫米基线的立体视觉系统使用480p的视频分辨率,如图1-20所示,深度分辨率在10米处降低大约1/2米。换句话说,从10米的位置看,对象在Z轴上看起来并没有移动,除非它们在Z轴上移动了至少1/2米。为了加倍深度分辨率,可简单地通过加倍传感器分辨率来实现。当距离增加时,人们倾向于使用单目深度线索来确定深度,比如物体的大小、物体运动速度、色彩强度和表面纹理细节等。
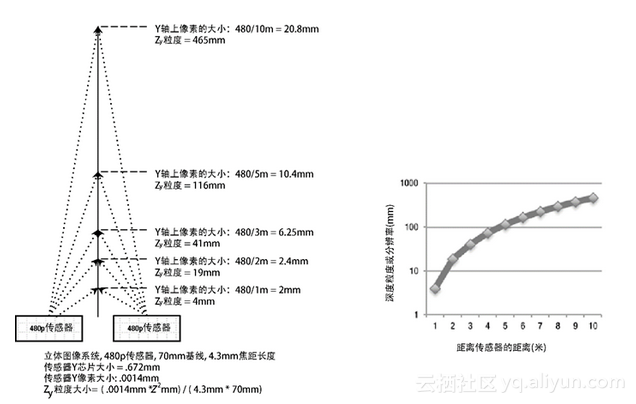
图1-20 一个典型的立体视觉摄像机系统中的Z深度粒度的非线性问题。注意,利用立体视觉和多视角立体视觉方法来执行实际的深度感知在景深上会有些限制,主要是受像素分辨率、 基线和焦距的影响。在 10米的位置上,深度粒度大概是1/2米,因此,为计算测量到的 立体视觉深度变化量,被测对象必须至少移动1/2米
1.3.2.2 一致性
一致性或特征匹配对大多数深度感知方法而言是一种常见的步骤。关于立体视觉特征匹配算法的分类,请参考Scharstein和Szeliski [440]。这里将沿着特征描述子方法、三角化并将其应用于立体视觉、多视角立体视觉和结构化光线来讨论一致性。
亚像素精度是大部分深度感应方法的一个目标,文献[468]提到了与之有关的几个算法。关联两个图像块或灰度模板的常见方式是通过拟合曲面来发现分值最高的匹配。然而,Fourier方法也可以用于关联相位[467,469],类似于灰度关联方法。
对于立体视觉系统而言,在特征匹配之前应该对图像对进行校正,以便在大致相同的尺度位置上能沿相同的直线找到这些特征,如图1-11所示,具有少许或甚至没有旋转不变性的描述子就很合适[215,120]。像相关模板这样的特征描述子已足够使用,而SIFT特征描述方法[161]就显得有点大材小用。特征描述子区域可是一个长方形,它倾向于在x轴上具有较大的差别,而在y轴上具有较小的方差,比如3×9的长方形描述子。我们希望在x轴上有差别,而不是y轴上。有几个窗口尺寸方法可用作确定描述子形状,其中包括固定尺寸方法和自适应尺寸方法[440]。
多视角立体视觉系统与立体视觉类似。然而,校正阶段不必那么精确,因为帧之间的运动包含放缩、平移和旋转。由于缩放和旋转在帧之间可能有重要的一致性问题,因而将其他特征描述方法应用到多视角立体视觉会有更好的结果。少数几个应用到多视角和宽基线立体视觉领域的著名特征描述子包括MSER [194]的方法(将在第6章中讨论),它使用了一个团状的片,还有SUSAN[164,165]方法(在第6章也会讨论),该方法基于一个对象区域或在特征周围具有一个已知中心(质心)的分割来定义特征。
对结构化光线系统而言,光模式的类型将决定特征,并且相位相关是一个常用的方法[469]。例如,基于移相模式的结构化光线方法使用相位相关[467]的模板匹配方法,该算法声称其精度能达到1/100个像素。也有将其他方法用于结构化光线的一致性,从而实现亚像素精度[467]。
1.空洞和遮挡
当模式在帧之间不匹配时,就会在深度图上留下一个空洞。遮挡也会引起空洞。无论是哪种情况,都必须修补深度图,有几种方法可以达到这样的目的。首先应该提供空洞图,以显示问题出在什么地方。一个简单的方法是在局部深度图的分块上使用双线性插值来填充这些空洞。另一种简单的方法是在深度图上使用当前扫描线上最后一个比较好的深度值来进行填充。
文献[472,471]中提出了一些更具有鲁棒性的方法来处理遮挡,它们的计算代价更大,但是精度只有少许的提高,比如使用自适应局部窗口优化插值区域。还有另一个用于处理空洞的方法,将曲面融合成一个深度体[473](下文中就要谈到),通过将多个连续的深度图集成到一个深度体上作为累积表面,然后从深度体中提取深度图。
2.曲面重构与融合
从深度图信息创建表面的一般方法称为表面重建。计算机图形学方法可用于渲染和显示表面。基本的想法是把几个深度图组合起来构造一个更好的表面模型,包括表面(呈现为一个纹理图)的RGB二维图像。通过创建三维表面(该表面集成了来自不同视角的多个深度图)的迭代模型,深度精度会有所提高,还能有效地减少或消除遮挡,并创建一个更宽的三维场景视角。
Curless和Levoy在文献[473]中提出了一种方法,能将多个范围图像或深度图融入到三维体的结构中。该算法通过整合多个范围图像,并将所有的范围图像当作异面(iso-surface)渲染成三维体。算法使用存储在三维体数据结构中,且与现有表面相关的有符号距离函数和加权因子来不断猜测实际表面最可能的位置,从而将新的表面整合到三维体中。当然,所得到的表面具有几个理想特性,包括降低噪声、减少孔大小、减小遮挡部分、多重视点以及更高的精度(如图1-21所示)。
将Curless和Levoy的方法进行延伸并应用到SLAM中,这便是Kinect Fusion方法[474],如图1-22所示,它使用计算密集型SIMD并行实时方法,这不仅提供表面重建,而且还可进行摄像头跟踪和六个自由度(6-degrees-of-freedom,6DOF)的摄像机位姿。光线跟踪和纹理映射可用于表面渲染。当然还可用其他方法从多幅图像中重建表面[480,551]。
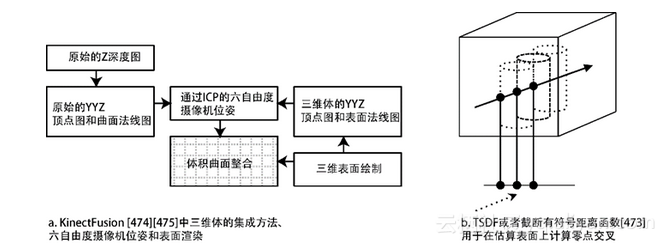
图1-21 (右图) Curless和Levoy [473]用于范围图像或深度图重建表面的方法。这里显示的是使用光线投射将三种不同的加权表面测量值投射到三维体上。
(左图)Kinect融合方法的处理流程
1.3.2.3 噪声
在深度传感器中[409],噪声也是一个问题,原因有多方面,包括光照暗、在某些情况下的运动噪声,以及低劣的深度感知算法或系统。此外,深度图通常非常模糊,所以就像在第2章讨论的那样,为了减少非常明显的噪声,图像预处理是必须的。许多人在深度图的处理的过程中喜欢使用双边滤波器[302],因为它牵涉到局部结构并保留边缘转换。此外,也有其他的噪声滤波器可用于修补双边滤波器的缺点,这非常适合于去除深度噪声,其中包括引导滤波器[486],它可保留边缘并过滤噪声(类似于双边滤波器),避免边缘的小波方法[488]以及域变换滤波器[489]。
1.3.3 单目深度处理
单目或单传感器的深度感知利用图形帧对来创建深度图,并根据帧与帧之间的运动创建立体视差。立体视觉处理假设立体对之间存在一个校准过的固定几何,但该假设对单目方法并不成立,因为每次摄像机移动,必须重新计算摄像机的位姿。摄像机的位姿是一个六自由度(6DOF)的方程,包括沿x、y和z轴的线性运动以及侧倾、俯仰和绕每个轴的旋转运动。在单目深度感应方法中,针对每一帧都要计算摄像机位姿,这是比较的前后两帧和计算其视差的基础。
注意6DOF矩阵的计算可以使用惯性传感器(如加速度计和MEMS陀螺仪[483])进行改进,以此作为粗略的对准步骤,接着是关于光流的视觉特征表面对准方法,这会在稍后讨论。在手机和平板电脑上,惯性传感器都是标准配置,当传感器技术成熟时,惯性姿态可能会变得更加实际和普遍。尽管商业使用的加速度计的精度不是很好,但单目深度感应系统可以通过惯性传感器的位姿估计节省计算时间。
1.3.3.1 多视点立体
大多数单目多视点立体(MVS)深度算法的几何模型是基于射影几何和极几何,关于两者的介绍可在Hartley和Zisserman[437]的经典文献中找到。六个MVS算法的分类和精度比较可参见Seitz等人[478]的文章。这一节将介绍几个有代表性的方法。
1.3.3.2 稀疏方法:PTAM
稀疏MVS方法会创建一个稀疏的三维点云,而不是一个完整的深度图。稀疏深度的基本目标非常简单,即逐帧地跟踪特征,通过计算特征视差来创建深度,并执行6DOF对准以定位新帧并获取摄像机位姿。根据不同的应用,稀疏深度作为特征描述子的一部分将不变性加入到透视视角中,或者基于场景中的几个关键点(landmark)为导航提供足够的信息,它们使用起来都比较理想。机器人社区已经开发了几款稀疏的深度感应方法——SLAM、SFM和光流。
然而,我们首先通过讨论一种特殊的方法,即并行跟踪和绘图(Parallel Tracking and Mapping, PTAM)[456,457]方法来详细介绍稀疏深度感知方法。PTAM既可跟踪六自由度的摄像机位姿,又可以产生一个稀疏深度图,在场景中允许它的副本被逐帧地放置到已知位置和方位上,因此非常适合小规模的增强现实应用。基本算法包含两个部分,这两部分会在并行线程中同时运行。一个是跟踪线程,用于更新位姿;另一个是映射线程,以便能更新稀疏三维点云。下面将对它们进行简单介绍。
映射线程处理最后N个关键帧的一个历史缓存区,并在历史缓冲区中为每个帧构建一个N层的图像金字塔,紧接着一系列的调整过程(这意味着通过选择一个求最小值的方法(如:Levenberg-Marquardt [437])来将现有的3D坐标拟合成新的三维坐标)会使用最新传入的深度特征不断完善稀疏三维点云。这些调整过程可以在最近的几个帧上进行局部调整,如果时间允许,还可在低速场景运动的整个时间段内执行全局调整。
跟踪线程扫描输入的图像帧以获取预期的特征,它在良好特征最后出现的地方进行投影以指导特征搜索,其中投影以六自由度摄像机的位姿作为基础。FAST9 [138]角点检测器用于定位角点,随后使用Shi-Tomasi的[157]非最大抑制步骤来消除较弱的角点候选点(在第6章中将更详细地讨论它)。特征匹配阶段之后是一个由粗到细的连续金字塔,它将用于计算六自由度位姿。
在新帧上使用每个角点周围8×8大小的图像块来计算目标特征。从最先发现的图像中选取最初的8×8大小的图像块,然后在上面计算参考特征。为了在特征匹配之前对齐参考特征块和目标特征块,每个参考特征块的表面法线将用于在最后已有的六自由度摄像机位姿上进行预变形(pre-warping),并采用零均值SSD距离匹配对齐的特征。
当定位失败时,单目深度感知的缺点就显现出来了。如果运动太快或光照的亮度变化太大,系统将无法定位,因而跟踪过程会终止。另一个弱点是,该算法必须完全初始化为特定的局部场景或工作区(比如桌面)。在初始化的过程中,PTAM会用五点立体视觉标定方法,它有几秒需要用户的配合才能执行。还有一个弱点是,包含点云的三维体大小适用于一个小的局部场景或工作区。不过,从积极的方面来看,三维点云的精度非常高,接近像素大小;位姿对增强现实或游戏应用等已经足够精确了;绕场景转一圈还能创建一个360度的视角点云。PTAM已经在手机[456]上实现了,它通过使用中等规模的计算存储资源,就能获取相当不错的精度和帧速率。
1.3.3.3 稠密方法:DTAM
与稀疏方法相比,稠密的单目深度感知方法属于计算密集型,因而其研究和开发非常有限。它的目标与稀疏的单目深度方法大致一样,即为图像对齐计算六自由度的摄像机位姿,但它为每个像素创建一个稠密的深度图,而不是稀疏点云。为了便于说明,我们通过Newcombe、Lovegrove和Davison[482]提出的方法DTAM(Dense Tracking and Mapping,稠密跟踪和映射)来重点介绍一些关键概念。
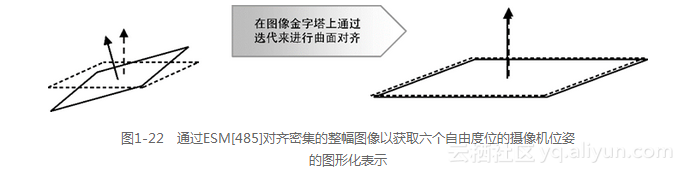
DTAM的目标是在每个像素点处计算稠密深度而不是稀疏深度,DTAM与PTAM [457]提出了同样的要求,因为两者都是单目方法。为了计算视差,需要对齐新帧,DTAM和PTAM都需要为每一个新帧计算六自由度位姿。DTAM也是需要用户干预的单目校准方法,它使用了PTAM的校准方法。DTAM也适用于小规模的局部场景或工作区。DTAM同样采用了几个概念,包括整体图像对齐,它基于有效的二阶最小化方法(Efficient Second Order Minimization,ESM),这些概念在Lovegrove 和 Davison [484]所提出的球形镶嵌方法中被用到。据文献报道,当求解六自由度的位姿时,该方法与LK(lucas kanade)方法相比,会用更少的迭代次数就可找到一个稳定的表面对齐。
显然,无论是DTAM还是球面镶嵌方法都会使用球面坐标的几何模型来将新帧镶嵌到稠密的三维表面,在图像金字塔上会采用由粗到细的对齐方式,以便通过迭代来最终解出六自由度的摄像机位姿。整幅图像实现表面对齐的基本思想如图1-22所示。局部导向滤波方法[486]会将新的和现有的深度表面整合到代价体(cost volume)。即导向滤波使用一个导向图像将要到来的深度信息并入到代价体中。
DTAM还充分利用SIMD指令和线程高度并行化的SIMT GPGPU编程,以此从商业GPU硬件上获得实时操作所需的性能。
1.3.3.4 光流、SLAM和SFM
光流会以位移向量的形式来测量帧之间的模式和特征的运动。光流类似于稀疏的单目深度感知方法,它可应用到宽基线的立体匹配的问题上[463]。因为光流的研究领域和应用非常广泛[459,460,461],这里仅提供一个简介,重点介绍所用方法以及所获得的特性。
光流被认为是稀疏特征跟踪问题,特征可当成一个粒子[462],所以光流类似于粒子流分析类。粒子流分析应用于多种粒子场的流分析问题中,包括天气预测、模拟燃烧和爆炸、水流量动态和机器人导航。二维和三维光流的方法在文献中都有涉及。各种光流算法都会重点关注特征跟踪描述子或矩阵,而不是基于离散标量值的连续场中的个别标量或像素。对计算机视觉而言,光流算法的输入是一组连续的二维图像和像素或三维体和体元,而输出是一组向量,用于表示跟踪特征的移动方向。
在光流方法中会用到早期LK方法[458,459,460,461]的许多变种和替代方法。大部分主流算法都是这样做的,它在相关模板中使用局部特征(该方法的讨论见第6章)。最早完整描述基于LK方法的最前沿的方法可参考Baker和Matthews [480],它比Lucas Kanade还要早20年。高效的二阶最小化(ESM)方法[485]与LK方法有一定关联。据文献所述,ESM方法比LK方法使用更少的迭代次数,该方法能可靠地解决问题。LK方法并不是跟踪单个像素,而是依赖于像素的邻域(比如3×3的矩阵或模板区域),并且试图猜测特征移动的方向,使用最小二乘法来迭代搜索局部区域并对搜索结果进行平均,最终得到最好的解。
尽管文献[459,460,461]描述了LK方法的各种不同的变种,但是大部分基于LK的光流方法都做了一些关键假设,包括帧与帧之间特征的较小偏移量、刚性特征以及为识别特征中的局部梯度必须包含足够多的纹理信息。有多种方法可以用于计算局部梯度,如Sobel和Laplacian(详见第2章)。如果场中从一帧到下一帧的特征偏移量较大或包含的纹理信息很少,那么LK方法就不再适用。这是因为LK算法主要通过考察每个局部矩阵的特征值来迭代得到优化解,所以会忽略那些梯度幅度小的区域。然而,最新的一些鲁棒性更好的研究方法正在超越LK方法[459,460]的限制,比如Deepflow [344],它可用于可形变特征和大偏移量光流的情形[394],它采用了类似于卷积神经网络[339]的多层特征的尺度层次结构。
同时定位与映射(Simultaneous Localization and Mappling,SLAM)和运动中恢复(Instructure From Motion,SFM)就是将表面重建应用到定位与映射(比如机器人导航)。SLAM的目标之一是局部化,或者找到当前位置和六自由度摄像机位姿。另一个目标是创建一个局部的区域地图(包括深度)。如果想深入了解SLAM和 SFM方法,可以参考Bailey和Hugh Durrant-Whyte对它们发展历史的介绍[476,477]。

![深度学习应用篇-计算机视觉-语义分割综述[5]:FCN、SegNet、Deeplab等分割算法、常用二维三维半立体数据集汇总、前景展望等](https://ucc.alicdn.com/fnj5anauszhew_20230609_9fa2ee47d1ba4c12bbc21fe1438dfd90.png?x-oss-process=image/resize,h_160,m_lfit)