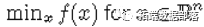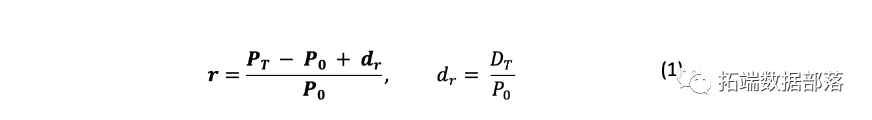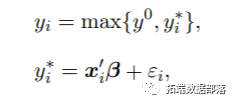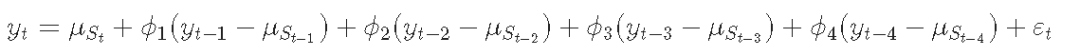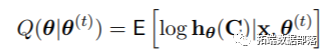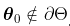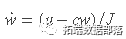热门
让你的文档从静态展示到一键部署可操作验证
一键生成视频!用 PAI-EAS 部署 AI 视频生成模型 SVD 工作流
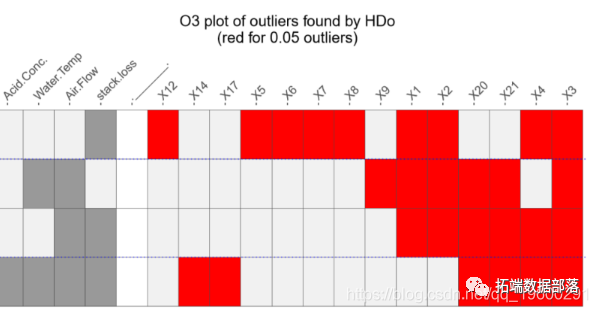
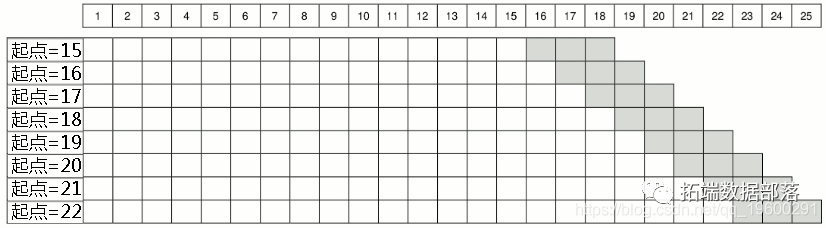
R语言Outliers异常值检测方法比较
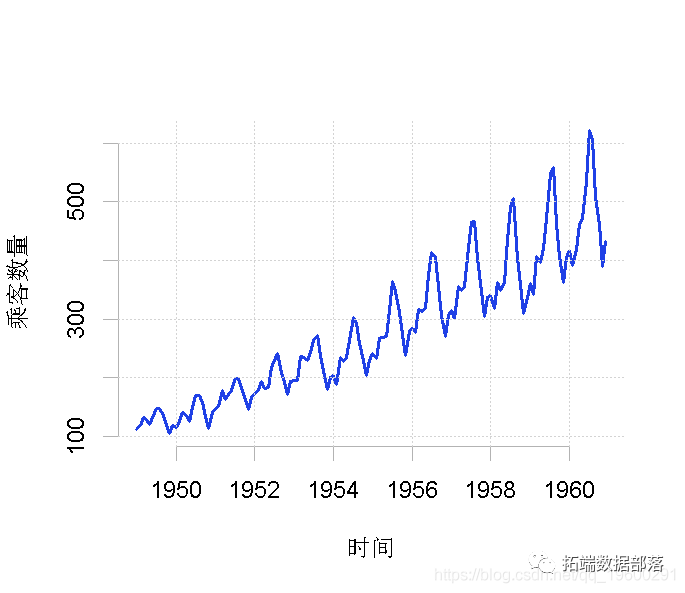
R语言多元时间序列滚动预测:ARIMA、回归、ARIMAX模型分析
从技术开始-技术路线选择
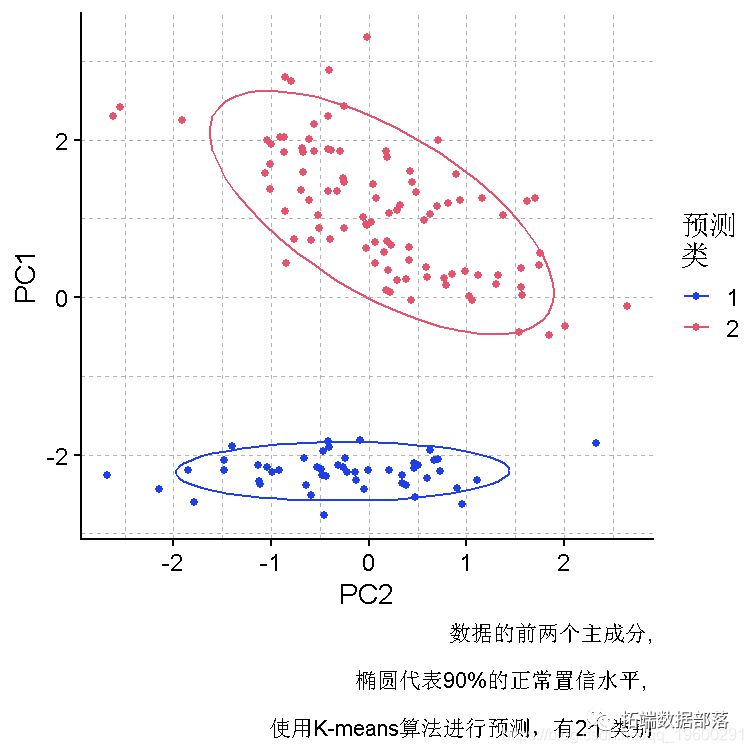
R语言k-means聚类、层次聚类、主成分(PCA)降维及可视化分析鸢尾花iris数据集
R语言用HESSIAN-FREE 、NELDER-MEAD优化方法对数据进行参数估计
用于NLP的Python:使用Keras进行深度学习文本生成
R语言计量经济学:虚拟变量(哑变量)在线性回归模型中的应用
【SpringBoot系列】第一课:构建一个简单的SpringBoot应用程序
Python风险价值计算投资组合VaR(Value at Risk )、期望损失ES(Expected Shortfall)
MATLAB中用BP神经网络预测人体脂肪百分比数据
R语言 PCA(主成分分析),CA(对应分析)夫妻职业差异和马赛克图可视化
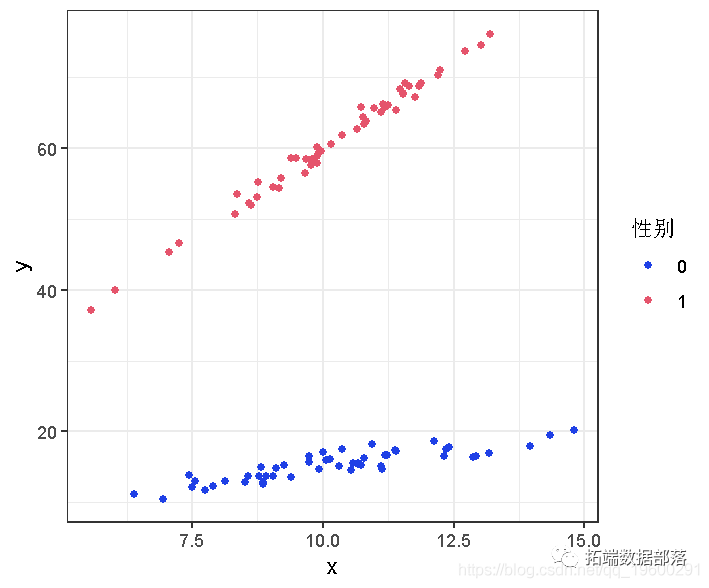
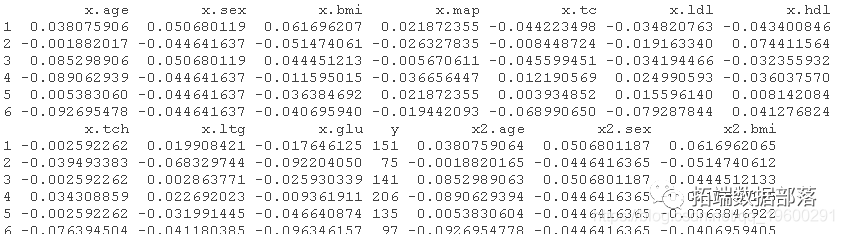
R语言Lasso回归模型变量选择和糖尿病发展预测模型
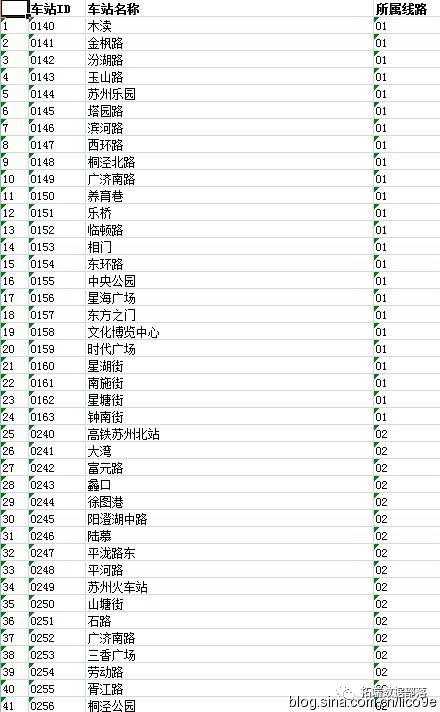
R语言公交地铁路线进出站数据挖掘网络图可视化
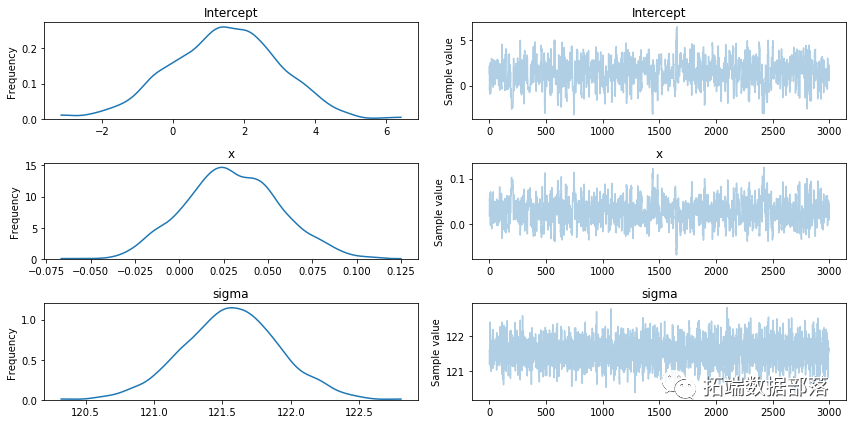
R语言实现贝叶斯分位数回归、lasso和自适应lasso贝叶斯分位数回归分析
Python贝叶斯回归分析住房负担能力数据集
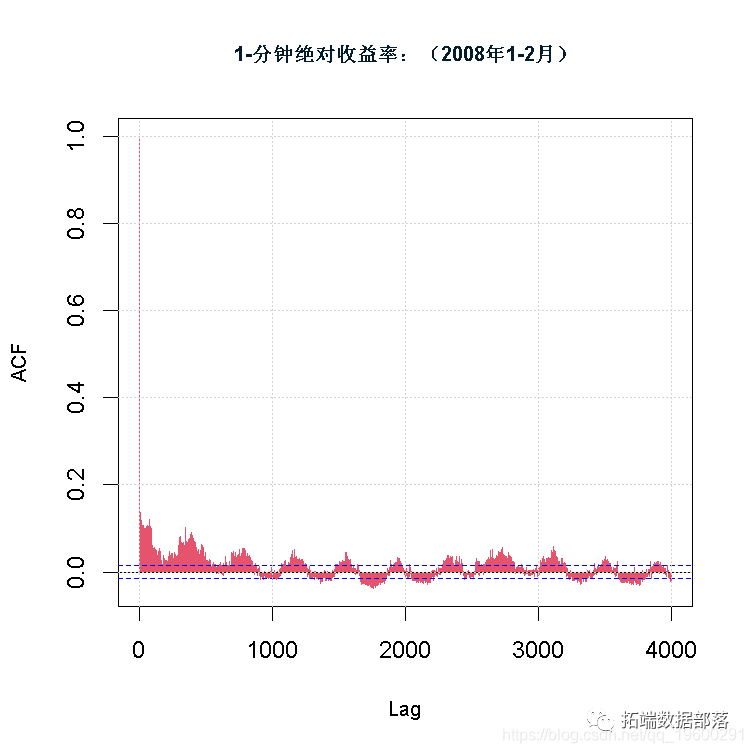
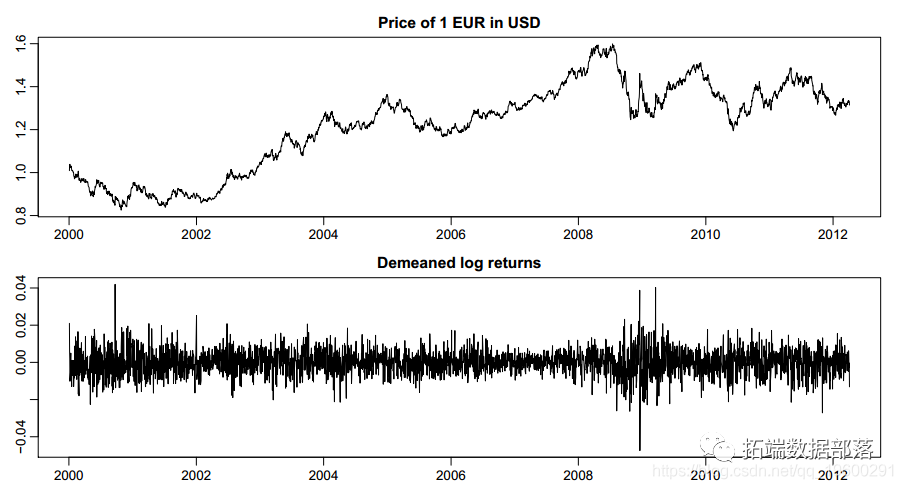
R语言乘法GARCH模型对高频交易数据进行波动性预测
PYTHON中用PROPHET模型对天气时间序列进行预测与异常检测
R语言状态空间模型和卡尔曼滤波预测酒精死亡人数时间序列
R语言用LOESS(局部加权回归)季节趋势分解(STL)进行时间序列异常检测
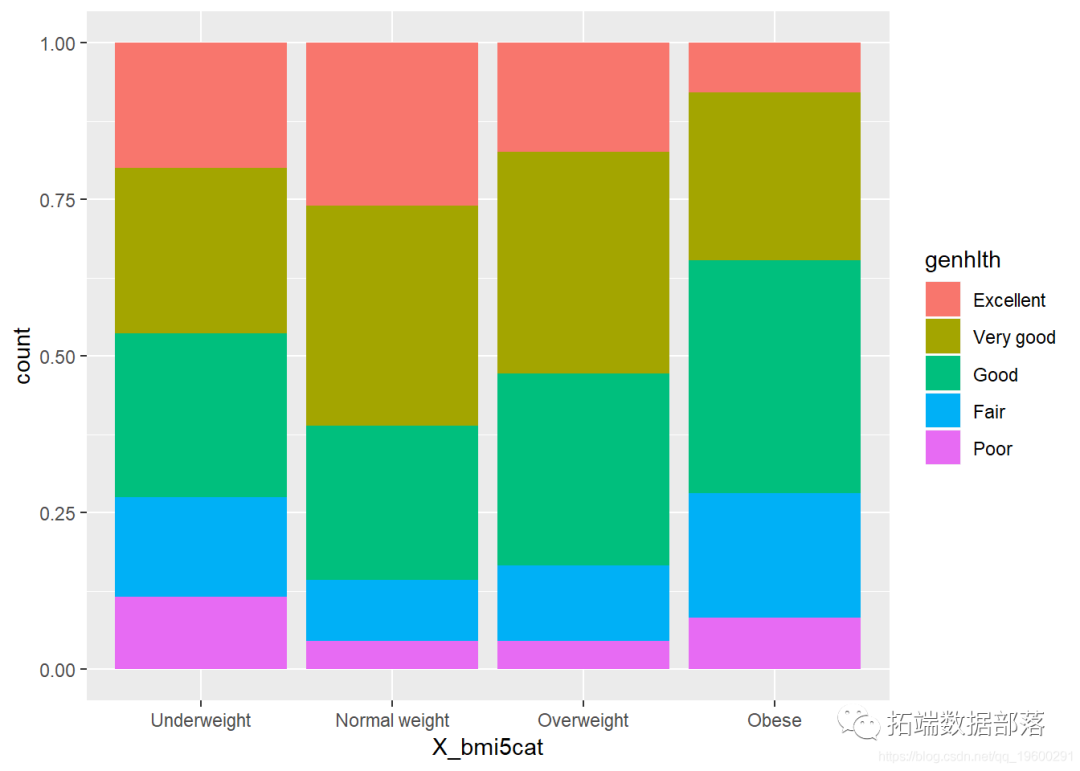
R语言数据可视化分析案例:探索BRFSS数据
淘宝API接口系列:数据分析丨Erp上货丨维权控价丨商品搬家丨店铺订单管理
PYTHON用时变马尔可夫区制转换(MRS)自回归模型分析经济时间序列
使用R语言随机波动模型SV处理时间序列中的随机波动率
流畅的 Python 第二版(GPT 重译)(七)(4)
流畅的 Python 第二版(GPT 重译)(七)(3)
流畅的 Python 第二版(GPT 重译)(七)(2)
流畅的 Python 第二版(GPT 重译)(七)(1)
R语言有限混合模型(FMM,finite mixture model)EM算法聚类分析间歇泉喷发时间
R语言中的Wilcoxon符号秩检验与配对学生t检验
Seaborn中的分类图:直观展示分类数据的差异
R语言计算资本资产定价模型(CAPM)中的Beta值和可视化
R语言配对检验分析案例
R语言极值推断:广义帕累托分布GPD使用极大似然估计、轮廓似然估计、Delta法
基于R语言实现LASSO回归分析
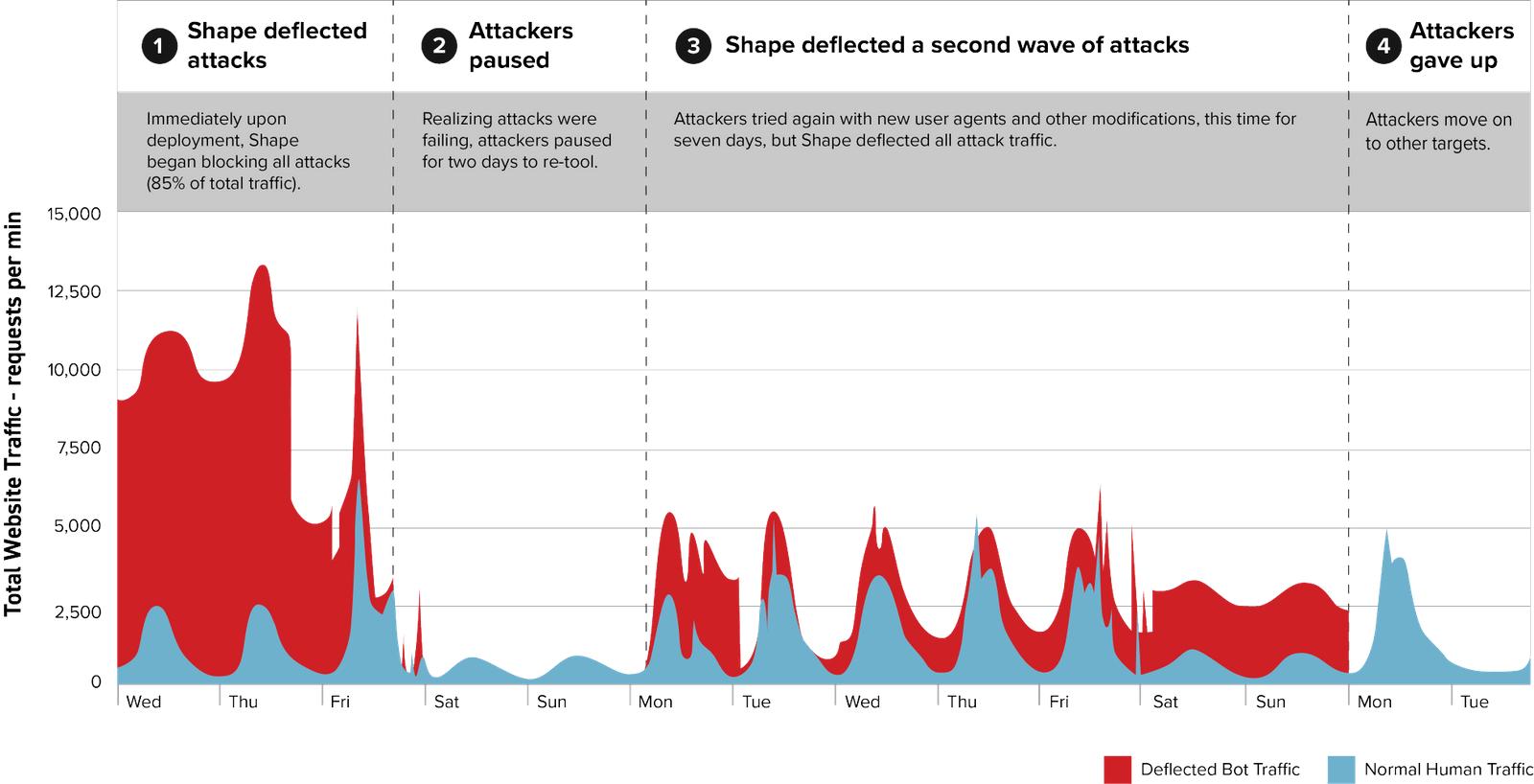
DDoS攻击愈演愈烈,谈如何做好DDoS防御
Seaborn中的时间序列图:展示数据随时间的变化趋势
Python随机波动率(SV)模型对标普500指数时间序列波动性预测
使用R语言进行多项式回归、非线性回归模型曲线拟合
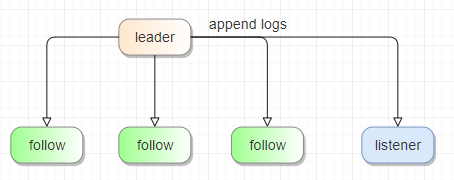
架构设计|基于 raft-listener 实现实时同步的主备集群
R语言使用ARIMAX预测失业率经济时间序列数据
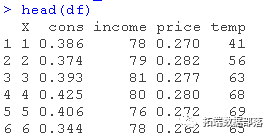
R语言用ARIMA模型,ARIMAX模型预测冰淇淋消费时间序列数据
Seaborn中的分布图:轻松展示数据分布情况
外键删除操作
R语言主成分分析(PCA)葡萄酒可视化:主成分得分散点图和载荷图
Seaborn中的关系图:探索变量之间的关联
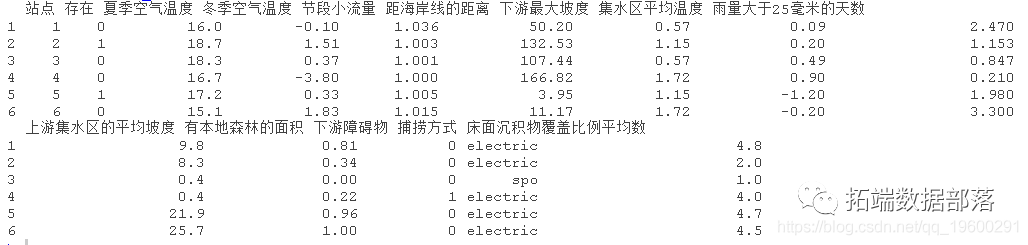
R语言生态学建模:增强回归树(BRT)预测短鳍鳗生存分布和影响因素
matlab实现扩展卡尔曼滤波(EKF)进行故障检测