本节书摘来异步社区《Python机器学习——预测分析核心算法》一书中的第2章,第2.1节,作者:【美】Michael Bowles(鲍尔斯),更多章节内容可以访问云栖社区“异步社区”公众号查看。
2.1 “解剖”一个新问题
本书介绍的算法通常是从一个充满了数字,可能是特征(变量)的矩阵(或表格)开始的。表2-1展示了一些术语,代表了一个小规模的二维机器学习数据集。此表提供了一个数据集的基本印象,这样对“列代表属性特征,行代表实例”等约定就比较熟悉。这个例子中的问题是预测下一年在线购买书籍所需花费的金额。
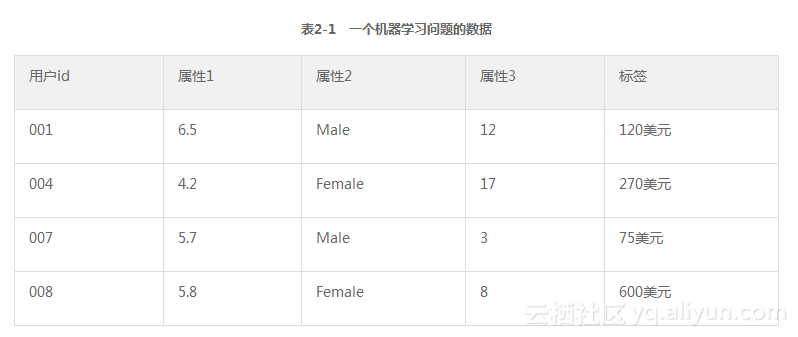
数据是按照行和列组织的。每行代表一个实例(或者叫一个例子、观察)。在表2-1中每列指定相应的列名,用来指明在一个机器学习问题中所起的作用。标明为“属性”的列用来预测在买书上所花的费用。在标明为“标签”的列,可以看到去年每个顾客在购书上的花费。
注意
机器学习数据集通常列对应一个属性,行对应一个观察,但也有例外。例如,有些文本挖掘问题的数据矩阵就是另外的形式:列对应一个观察,行对应一个属性。
在表2-1中,一行代表一个顾客,此行的数据都与此顾客相关。第一列叫作UserID(用户ID),是每行惟一的识别符。实际问题中可能有惟一识别符也可能没有。例如,网站通常为网站的访客建立一个相应的用户ID,并且在此用户访问网站期间,用户的所有行为都与此用户ID绑定。如果用户在此网站上没有注册,则用户的每次访问都将获得一个不同的用户ID。通常每个观察会被分配一个ID,这个就是预测的目标对象。第2~第4列称为属性,以代替更具体的名字,如身高、性别等。这主要是为了突出他们在预测过程中起到的作用。属性就是在具体实例中用来预测的数据。
标签就是需要预测的数据。在这个例子中,用户ID就是一个简单的数字,属性1是身高,属性2是性别,属性3是此人去年阅读的书籍的数量。标签列上的数字代表每人去年在线购书的花费。那么不同类型的数据分别代表什么样的角色呢?一个机器学习算法是如何利用用户ID、属性和标签列的呢?最简短的回答就是:忽略用户ID。使用属性来预测标签。
惟一的用户ID只是起到记账的目的,在某些情况下可以根据用户ID检索到用户的其他数据。通常机器学习算法并不直接使用用户ID。属性是挑选出来用于预测的。标签是观察得到的结果,机器学习基于此来构建预测模型。
预测通常不用用户ID信息,因为它太特殊了。它一般只属于一个实例。一个机器学习的技巧就是构建的模型要有泛化能力(即可以解决新的实例,而不仅仅是把过去的例子都记下来)。为了达到这个目的,算法必须能够关注到不止一行的数据。一个可能的例外是,如果用户ID是数字的,并且是按照用户登录的时间依次进行分配的。这样就指示了用户的登录日期,那么如果用户ID比较接近,就证明了用户是在比较接近的时间上登录的,依此为条件可以把用户划分为不同的组。
构建预测模型的过程叫作训练。具体的方法依赖于算法,后续章节会详述,但基本上采用迭代的方式。算法假定属性和标签之间存在可预测的关系,观察出错的情况,做出修正,然后重复此过程直到获得一个相对满意的模型。技术细节后续会介绍,这里只是介绍基本思想。
名字的含义:
属性和标签有不同的名字。机器学习的初学者往往被这些名词迷惑,不同的作者可能会采用不同的名字,甚至一篇文章的段落与段落之间都会采用不同的名字。
属性(用来进行预测的变量)也被称为:
预测因子
特征
独立变量
输入
标签通常也被称为:
结果
目标
依赖变量
响应
2.1.1 属性和标签的不同类型决定模型的选择
表2-1中的属性可以分成2类:数值变量、类别(或因素、因子)变量。属性1(身高)是一个数值变量,也是最常见的属性类型。属性2是性别,可以是男性或女性。这种类型的属性叫作类别变量或因素变量。类别变量的一个特点就是不同值之间没有顺序关系。男性<女性是没有意义的(噢,忘掉几个世纪的争吵吧)。类别变量可以是2值的,如男性和女性,也可以是多值的,如美国的州(AL,AK,AR,…WY)。关于属性还有其他差别(如整数与浮点数),但这些差别对机器学习算法的影响并不像数值变量和类别变量那么大。主要原因是很多机器学习算法只能处理数值变量,不能处理类别变量或因素变量(factor variable)。例如,惩罚回归算法只能处理数值变量,SVM、核方法、K最近邻也是同样。第4章将介绍将类别变量转换为数值变量的方法。这些变量的特性将会影响算法的选择以及开发一个预测模型的努力的方向,因此这也是当面临一个新问题时,需要考虑的因素之一。
这种二分法同样适用于标签。表2-1所示的标签是数值的:去年在线购书所花费的金额。然而在其他问题中,标签就可能是类别的。例如,如果表2-1的任务是预测哪些人下一年的花费超过200美元,那么问题就变了,解决问题的方法也随之变了。预测哪些顾客的花费会超过200美元的新问题会产生新的标签。这些标签会在两个值中选一个。表2-1中的标签与新的逻辑命题“花费>200美元”下的新标签之间的关系如表2-2所示。表2-2所示的新标签取值为:真或假。
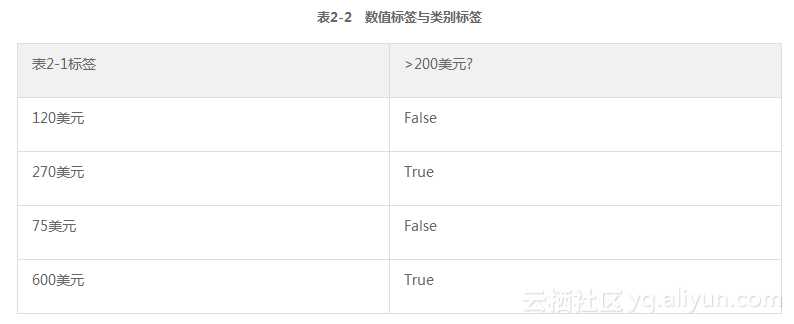
当标签是数值的,就叫作回归问题。当标签是类别的,就叫作分类问题。如果分类结果只取2个值,就叫作二元分类问题。如果取多个值,就是多类别分类问题。
在很多情况下,问题的类型是由设计者选择的。刚刚的例子就是如何把一个回归问题转换为二元分类问题,只需要对标签做简单的变换。这实际上是面临一个问题时所做的一种权衡。例如,分类目标可以更好地支持2种行为选择的决策问题。
分类问题也可能比回归问题简单。例如考虑2个地形图的复杂度差异,一个地形图只有一个等高线(如30.5米的等高线),而另一个地形图每隔3.05米就有一个等高线。只有一个等高线的地形图将地图分成高于30.5米的区域和低于30.5米的区域,因此相比另一个地形图含有更少的信息。一个分类器就相当于只算出一个等高线,而不再考虑与这条分界线的远近距离之类的问题,而回归的方法就相当于要绘制一个完整的地形图。
2.1.2 新数据集的注意事项
初始审视数据集时,还需要考查数据集的其他特性。下面是一个检查清单,是为了熟悉数据集需要考察的一系列事情,这也有利于明确后续预测模型的开发流程。这些都是很简单的事情,但是直接影响后续步骤,通过这个过程可以了解此数据集的特性。
需要检查的事项:
行数、列数
类别变量的数目、类别的取值范围
缺失的值
属性和标签的统计特性
第一个要确认的就是数据的规模。将数据读入二维数组,则外围数组的维度就是行数,内部数组的维度就是列数。下节将会展示针对某一数据集应用此方法获取数据的规模。
下一步就要确定每行有多少缺失的值。这么一行行处理数据的原因是处理缺失数据最简单的方法就是直接抛弃有缺失数据的行(如至少少了一个值的行)。在很多情况下,这样做会导致结果偏差,但在抛弃的行不多的情况下,并不会产生实质性的差异。通过计算具有缺失数据的行数(加上具体缺失的项数),就可以知道如果采用最简单的方法,则实际上抛弃了多少数据。
如果你有大量的数据,例如正在收集互联网上的数据,那么丢失的数据相对于你获得的数据总量应该是微不足道的。但如果处理的是生物数据,这些数据都比较昂贵,而且有多种属性,这时抛弃这些数据的代价就太大了。在这种情况下,需要找到方法把丢失的值填上,或者使用能够处理丢失数据的算法。把丢失的数据填上的方法一般叫作遗失值插补(imputation)。遗失值插补的最简单方法就是用每行所有此项的值的平均值来代替遗失的值。更复杂的方法要用到第4章和第6章介绍的预测模型。用预测模型时,将含有遗失值的那列属性当作标签,当然在进行这步之前要确保将初始问题的标签移除。
接下来的小节将从头到尾介绍分析数据集的完整过程,并引入刻画数据集的一些方法,这些都将帮助你确定如何解决建模的问题。
