本节书摘来自异步社区《逆向工程权威指南》一书中的第3章3.4节ARM,作者【乌克兰】Dennis Yurichev(丹尼斯),更多章节内容可以访问云栖社区“异步社区”公众号查看。
3.4 ARM
根据我个人的经验,本书将通过以下几个主流的ARM编译器进行演示。
2013年6月版本的Keil编译器。
Apple Xcode 4.6.3 IDE (含LLVM-GCC 4.2编译器) 。[10]
面向 ARM64的GCC 4.9 (Linaro),其32位的Windows程序可由下述网址下载:http://www. linaro.org/ projects/armv8/。
除非特别标注,否则本书中的ARM程序都是32位ARM程序。在介绍64位的ARM程序时,本书会称其为ARM64程序。
3.4.1 Keil 6/2013——未启用优化功能的ARM模式
请使用下述指令,用Keil编译器把hello world程序编译为ARM指令集架构的汇编程序:
armcc.exe --arm --c90 -O0 1.c
虽然armcc编译器生成的汇编指令清单同样采用了Intel语体,但是程序所使用的宏却极具ARM处理器的特色[11]。眼见为实,我们一起用IDA来看看它们的本来面目吧。
指令清单3.11 使用IDA观察Non-optimizing Keil 6/2013 (ARM模式)
.text:00000000 main
.text:00000000 10 40 2D E9 STMFD SP!, {R4,LR}
.text:00000004 1E 0E 8F E2 ADR R0, aHelloWorld ; "hello, world"
.text:00000008 15 19 00 EB BL __2printf
.text:0000000C 00 00 A0 E3 MOV R0, #0
.text:00000010 10 80 BD E8 LDMFD SP!, {R4,PC}
.text:000001EC 68 65 6C 6C+aHelloWorld DCB "hello, world",0 ; DATA XREF: main+4
在本节的例子里,每条指令都占用4个字节。正如您所见到,我们确实要把源程序编译为ARM模式指令集的应用程序,而不是把它编译为以Thumb模式的应用程序。
现在回顾上面的代码,第一句“STMFD SP!, {R4,LR}”[12]相当于x86的PUSH指令。它把R4寄存器和LR(Link Register)寄存器的数值放到数据栈中。此处,本文的措辞是“相当于”,而非“完全是”。这是因为ARM模式的指令集里没有PUSH指令,只有Thumb模式里的指令集里才有“PUSH/POP”指令。在IDA中可以清除地看到这种差别,所以本书推荐使用IDA分析上述程序。
这条指令首先将SP[13]递减,在栈中分配一个新的空间以便存储R4和LR的值。
STMFD指令能够一次存储多个寄存器的值,Thumb模式的PUSH指令也可以这样使用。实际上x86指令集中并没有这样方便的指令。STMFD指令可看作是增强版本的PUSH指令,它不仅能够存储SP的值,也能够存储任何寄存器的值。换句话说,STMFD可用来在指定的内存空间存储多个寄存器的值。
接下来的指令是“ADR R0, aHelloWorld”。它首先对PC[14]进行取值操作,然后把“hello, world”字符串的偏移量(可能题值)与PC的值相加,将其结果存储到R0之中。有些读者可能不明白此处PC寄存器的作用。严谨地说,编译器通常帮助PC把某些指令强制变为“位置无关代码/position-independent code”。在(多数)操作系统把程序加载在内存里的时候,OS分配给程序代码的内存地址是不固定的;但是程序内部既定指令和数据常量之间的偏移量是固定的(由二进制程序文件决定)。这种情况下,要在程序内部进行指令寻址(例如跳转等情况),就需要借助PC指针[15]。ADR将当前指令的地址与字符串指针地址的差值(偏移量)传递给R0。程序借助PC指针可找到字符串指针的偏移地址,从而使操作系统确定字符串常量在内存里的绝对地址。
“BL __2printf”[16]调用printf()函数。BL实施的具体操作实际上是:
将下一条指令的地址,即地址0xC处“MOV R0, #0”的地址,写入LR寄存器。
然后将printf()函数的地址写入PC寄存器,以引导系统执行该函数。
当printf()完成工作之后,计算机必须知道返回地址,即它应当从哪里开始继续执行下一条指令。所以,每次使用BL指令调用其他函数之前,都要把BL指令的下一个指令的地址存储到LR寄存器。
这便是CISC(复杂指令集)处理器与RISC(精简指令集)处理器在工作模式上的区别。在拥有复杂指令集的x86体系里,操作系统可以利用栈存储返回地址。
顺便说一下,ARM模式跳转指令的寻址能力确实存在局限性。单条ARM模式的指令必须是32位/4字节,所以BL指令无法调用32位绝对地址或32位相对地址(容纳不下),它只能编入24位的偏移量。不过,既然每条指令的opcode必须是4字节,则指令地址必须在4n处,即偏移地址的最后两位必定为零,可在opcode里省略。在处理ARM模式的转移指令时,处理器将指令中的opcode的低24位左移2位,形成26位偏移量,再进行跳转。由此可知,转移指令B/BL的跳转指令的目标地址,大约在当前位置的±32MB区间之内[17]。
下一条指令“MOV R0,#0”将R0寄存器置零。Hello World的C代码中,主函数返回零。该指令把返回值写在R0寄存器中。
最后到了“LDMFD SP!, R4,PC”这一条指令[18]。它与STMFD成对出现,做的工作相反。它将栈中的数值取出,依次赋值给R4和PC,并且会调整栈指针SP。可以说这条指令与POP指令很相似。main()函数的第一条指令就是STMFD指令,它将R4寄存器和LR寄存器存储在栈中。main()函数在结尾处使用LDMFD指令,其作用是把栈里存储的PC的值和R4寄存器的值恢复回来。
前面提到过,程序在调用其他函数之前,必须把返回地址保存在LR寄存器里。因为在调用printf()函数之后LR寄存器的值会发生改变,所以主函数的第一条指令就要负责保存LR寄存器的值。在被调用的函数结束后,LR寄存器中存储的值会被赋值给PC,以便程序返回调用者函数继续运行。当C/C++的主函数main()结束之后,程序的控制权将返回给OS loader,或者CRT中的某个指针,或者作用相似的其他地址。
数据段中的DCB是汇编语言中定义ASCII字符数组/字节数组的指令,相当于x86汇编中的DB指令。
3.4.2 Thumb模式下、未开启优化选项的Keil
现在以Thumb模式编译前面的源代码:
armcc.exe --thumb --c90 -O0 1.c
我们会在IDA中看到如下指令。
指令清单3.12 使用IDA观察Non-optimizing Keil 6/2013 (Thumb模式)
.text:00000000 main
.text:00000000 10 B5 PUSH {R4,LR}
.text:00000002 C0 A0 ADR R0, aHelloWorld;"hello, world"
.text:00000004 06 F0 2E F9 BL _2printf
.text:00000008 00 20 MOVS R0, #0
.text:0000000A 10 BD POP {R4, PC}
.text:00000304 68 65 6C 6C +aHelloWorld DCB "hello, world",0 ; DATA XREF: main+2
Thumb 模式程序的每条指令,都对应着2个字节/16位的opcode,这是Thumb模式程序的特征。但是Thumb模式的跳转指令BL“看上去”占用了4个字节的 opcode,实际上它是由2条指令组成的。单条16位opcode传递的信息太有限,不足以向被调用函数传递PC和偏移量信息。所以,上面BL指令分为2条16位opcode。第一条16位指令可以传递偏移量的高10位,第二条指令可以传递偏移量的低11位。而Thumb模式的opcode都是固定的2 个字节长,目标地址位最后一个位必定是0(Thumb模式的opcode的启始地址位必须是2n),因而会被省略。在执行Thumb模式的转移指令时,处理器会将目标地址左移1位,形成22位的偏移量。即Thumb的BL跳转指令将无法跳到奇数地址,而且跳转指令仅仅能偏移到到当前地址 ±2MB(22位有符号整数的取值区间)附近的范围之内。
程序主函数的其他指令,PUSH和POP工作方式与STMFD/LDMFD相似。虽然表面上看不出来,但是实际上它们也会调整SP指针。ADR指令与前文的作用相同。而MOVS 指令负责把返回值(R0寄存器)置零。
3.4.3 ARM模式下、开启优化选项的Xcode
如果不启用优化选项,Xcode 4.6.3 将会产生大量的冗余代码,所以不妨开启优化选项,让其生成最优的代码。请指定编译选项-O3,使用Xcode(启用优化选项-O3)编译Hello world程序。这将会得到如下所示的汇编代码。
指令清单3.13 Optimizing Xcode 4.6.3 (LLVM) (ARM模式)
__text:000028C4 _helloworld
__text:000028C4 80 40 2D E9 STMFD SP!, {R7, LR}
__text:000028C8 86 06 01 E3 MOV R0, #0x1686
__text:000028CC 0D 70 A0 E1 MOV R7, SP
__text:000028D0 00 00 40 E3 MOVT R0, #0
__text:000028D4 00 00 8F E0 ADD R0, PC, R0
__text:000028D8 C3 05 00 EB BL _puts
__text:000028DC 00 00 A0 E3 MOV R0, #0
__text:000028E0 80 80 BD E8 LDMFD SP!, {R7, PC}
__cstring:00003F62 48 65 6C 6C+aHelloWorld_0 DCB "Hello World!", 0
我们就不再重复介绍STMFD/LDMFD指令了。
第一个MOV指令将字符串“Hello World!”的偏移量,0x1686 赋值到R0寄存器。
根据Apple ABI 函数接口规范[19],R7寄存器担当帧指针(frame pointer)寄存器。
“MOVT R0, #0”将0写到R0寄存器的高16位地址。在ARM模式里,常规的MOV指令只能操作寄存器的低16位地址,而单条ARM指令最多是32位/4字节。当然,寄存器之间传递数据没有这种限制。所以,对寄存器的高位(第16位到第31位)进行赋值操作的MOVT指令应运而生。然而此处的这条MOVT指令可有可无,因为在执行下一条指令“MOV R0, #0x1686”时,R0寄存器的高16位本来就会被清零。这或许就是编译器智能方面的缺陷吧。
“ADD R0,PC,R0”将PC和R0进行求和,计算得出字符串的绝对地址。前文介绍过了“位置无关代码”,我们知道程序运行之后的启始地址并不固定。此处,程序对这个地址进行了必要的修正。
然后,程序通过BL指令调用puts()函数,而没有像前文那样调用printf()函数。这种差异来自于GCC编译器[20],编译器将第一个printf()函数替换为puts()函数(这两个函数的作用几乎相同)。
所谓“几乎”就意味着它们还存在差别事实上,如printf()函数支持“%”开头的控制符,而puts()函数则不支持这类格式化字符串。如果参数里有这类控制符,那么这两个函数的输出结果还会不同。
为什么GCC编译器会做这种替换?大概是由于这种情况下puts()的效率更高吧。由于puts()函数不处理控制符(%)、只是把各个字符输出到stdout设备上,所以puts()函数的运行速度更快[21]。
后面的“MOV R0, #0”指令将R0寄存器置零。
3.4.4 Thumb-2模式下、开启优化选项的Xcode(LLVM)
默认情况下,Xcode 4.6.3 会启用优化模式,并以Thumb-2模式编译源程序。
指令清单3.14 Optimizing Xcode 4.6.3 (LLVM) (Thumb-2模式)
__text:00002B6C
_hello_world
__text:00002B6C 80 B5 PUSH {R7,LR}
__text:00002B6E 41 F2 D8 30 MOVW R0, #0x13D8
__text:00002B72 6F 46 MOV R7, SP
__text:00002B74 C0 F2 00 00 MOVT.W R0, #0
__text:00002B78 78 44 ADD R0, PC
__text:00002B7A 01 F0 38 EA BLX _puts
__text:00002B7E 00 20 MOVS R0, #0
__text:00002B80 80 BD POP {R7, PC}
__cstring:00003E70 48 65 6C 6F 20+aHelloWorld DCB "Hello word!",0xA,0
上文提到过,thumb模式的BLX和BL指令以2个16位指令的形式成对出现的。在Thumb-2模式下,BL和BLX指令对应的伪opcode有明显的32位指令特征,其对应的opcode都以0xFx或者0xEx开头。
在显示Thumb和Thumb-2模式程序的opcode时,IDA会以两个字节为单位对调。在显示ARM 模式的指令时,IDA以字节为单位、依次逆序显示其opcode。这是字节序的排版差异。
简要地说,在IDA显示ARM平台的指令时,其显示顺序为:
ARM及ARM64模式的指令,opcode以4-3-2-1的顺序显示。
Thumb模式的指令,opcode以2-1的顺序显示。
Thumb-2模式的16位指令对,其opocde以2-1-4-3的顺序显示。
在IDA中,我们可观察到上述MOVW 、MOVT.W、BLX指令都以0xFx开头。
之后的“MOVW R0,#0x13D8”将立即数写到R0寄存器的低16位地址,同时清除寄存器的高16位。
“MOVT.W R0, #0”的作用与前面一个例子中Thumb模式的MOVT的作用相同,只不过此处是Thumb-2的指令。
在这两个例子中,最显著的区别是Thumb-2模式“BLX”指令。此处的BLX与Thumb模式的BL指令有着根本的区别。它不仅将puts()函数的返回地址RA存入了LR寄存器,将控制权交给了puts()函数,而且还把处理器从Thumb/Thumb-2模式调整为ARM模式;它同时也负责在函数退出时把处理器的运行模式进行还原。总之,它同时实现了模式转换和控制权交接的功能,相当于执行了下面的ARM模式的指令:
__symbolstub1:00003FEC _puts ; CODE XREF: _hello_world+E
__symbolstub1:00003FEC 44 F0 9F E5 LDR PC, =__imp__puts
聪明的读者可能会问,此处为什么不直接调用puts()函数?
直接调用的空间开销更大。
几乎所有的程序都会用到动态链接库,详细说来Windows的程序基本上都会用到DLL文件、Linux程序差不多都会用到.SO文件、MacOSX系统的程序多数也会用到.dylib文件。常用的库函数通常都放在动态链接库里。本例用到的标准C函数——puts()函数也不例外。
可执行的二进制文件(Windows的PE可执行文件,ELF或Mach-O)都有一个输入表段(import section)。输入表段声明了该程序需要通过外部模块和加载的符号链接(函数名称和全局变量),并且含有外部模块的名称等信息。
在操作系统执行二进制文件的时候,它的加载程序(OS loader)会依据这个表段加载程序所需要的模块。在它加载该程序主模块的时候,对导入的符号链接进行枚举,逐一分配符号链接的地址。
在本例中,_imp_puts是操作系统加载程序(OS loader)为hello world程序提供的外部函数地址,属于32位变量。程序只需要使用LDR指令取出这个变量,并且将它赋值给PC寄存器,就可以调用puts()函数。
可见,一次性地给每个符号链接分配独立的内存地址,可以大幅度地减少OS loader在加载方面的耗时。
前文已经指出,如果只能靠单条指令、而不借助内存的读取操作,CPU就无法把32位数值(指针或立即数)赋值给寄存器。所以,可以建立一个以ARM模式运行的独立函数,让它专门处理动态链接库的接口问题。此后Thumb模式的代码就可以跳转到这个处理接口功能的单指令专用函数。这种专用函数称为(运行模式的)形实转换函数(thunk function)。
前面有一个ARM模式的编译例子,它就使用BL指令实现相同功能的形实转换函数。但是那个程序使用的指令是BL而不是BLX,可见处理器并没有切换运行模式。
形实转换函数(thunk function)的由来
形实转换函数,是“形参与实参互相转换的函数”的缩写。它不仅是缩写词,而且是外来词。这一专用名词的出处可参见:http://www.catb.org/jargon/html/T/thunk.html。
P. Z. Ingerman在1961年首次提出了thunk的概念,这个概念沿用至今:在编译过程中,为满足当时的过程(函数)调用约定,当形参为表达式时,编译器都会产生thunk,把返回值的地址传递给形参。
微软和IBM都对“thunk”一词有定义,将从16位到32位和从32位到16位的转变叫作“thunk”。
3.4.5 ARM64
GCC
使用GCC 4.8.1将上述代码编译为ARM64程序,可得到如下所示的代码。
指令清单3.15 Non-optimizing GCC 4.8.1 + objdump
1 0000000000400590 <main>:
2 400590: a9bf7bfd stp x29, x30, [sp,#-16]!
3 400594: 910003fd mov x29, sp
4 400598: 90000000 adrp x0, 400000 <_init-0x3b8>
5 40059c: 91192000 add x0, x0, #0x648
6 4005a0: 97ffffa0 bl 400420 <puts@plt>
7 4005a4: 52800000 mov w0, #0x0 // #0
8 4005a8: a8c17bfd ldp x29, x30, [sp],#16
9 4005ac: d65f03c0 ret
10
11 ...
12
13 Contents of section .rodata:
14 400640 01000200 00000000 48656c6c 6f210000 ........Hello!..
一方面,ARM64的CPU只可能运行于ARM模式、不可运行于Thumb 或 Thumb-2模式,所以它必须使用32位的指令。另一方面,64位平台的寄存器数量也翻了一翻,拥有了64个X-字头寄存器(请参见附录B.4.1)。当然,程序还可以通过W-字头的名称直接访问寄存器的低32位空间。
上述程序的STP(Store Pair)指令把两个寄存器(即X29,X30)的值存储到栈里。虽然这个指令实际上可以把这对数值存储到内存中的任意地址,但是由于该指令明确了SP寄存器,所以它就是通过栈来存储这对数值。ARM64平台的寄存器都是64位寄存器,每个寄存器可存储8字节数据。所以程序要分配16字节的空间来存储两个寄存器的值。
这条指令中的感叹号标志,意味着其标注的运算会被优先执行。即,该指令先把SP的值减去16,在此之后再把两个寄存器的值写在栈里。这属于“预索引/pre-index”指令。此外还有“延迟索引/post-index”指令与之对应。有关两者的区别,请参见本书28.2节。
以更为易懂的x86指令来解读的话,这条指令相当于PUSH X29和PUSH X30两条指令。在ARM64平台上,X29寄存器是帧指针FP,X30起着LR的作用,所以这两个寄存器在函数的序言和尾声处成对出现。
第二条指令把SP的值复制给X29,即FP。这用来设置函数的栈帧。
ADRP和ADD指令相互配合,把“Hello!”字符串的指针传递给X0寄存器,继而充当函数参数传递给被调用函数。受到指令方面的限制,ARM无法通过单条指令就把一个较大的立即数赋值给寄存器(可参见本书的28.3.1节)。所以,编译器要组合使用数条指令进行立即数赋值。第一条ADRP把4KB页面的地址传递给X0,而后第二条ADD进行加法运算并给出最终的指针地址。详细解释请参见本书28.4节。
0x400000 + 0x648 = 0x400648。这个数是位于.rodata数据段的C字符串“Hello!”的地址。
接下来,程序使用BL指令调用puts()函数。这部分内容的解读可参见3.4.3节。
MOV指令用来给W0寄存器置零。W0是X0寄存器的低32位,如下图所示。
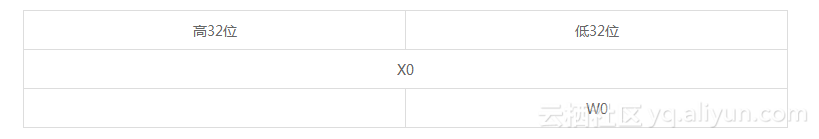
main()函数通过X0寄存器来传递函数返回值0。程序后续的指令依次制备这个返回值。为什么这里把返回值存储到X0寄存器的低32位,即W0寄存器?这种情况和x86-64平台相似:出于兼容性和向下兼容的考虑,ARM64平台的int型数据仍然是32位数据。对于32位的int型数据来说,X0寄存器的低32位足够大了。
为了进行演示,我对源代码进行了小幅度的修改,使main()返回64位值。
指令清单3.16 main()返回uint64_t 型数据
#include <stdio.h>
#include <stdint.h>
uint64_t main()
{
printf ("Hello!\n");
return 0;
}
返回值虽然相同,但是对应的MOV指令发生了变化。
指令清单3.17 Non-optimizing GCC 4.8.1 + objdump
4005a4: d2800000 mov x0, #0x0 // #0
在此之后,LDP (Load Pair)指令还原X29和X30寄存器的值。此处的这条指令没有感叹号标记,这意味着它将率先进行赋值操作,而后再把SP的值与16进行求和运算。这属于延时索引(post-index)指令。
RET指令是ARM64平台的特色指令。虽然它的作用与BX LR相同,但是它实际上是按照寄存器的名称进行跳转的(默认使用X30寄存器指向的地址),通过底层指令提示CPU此处为函数的返回指令、不属于普通转移指令的返回过程。RET指令经过了面向硬件的优化处理,它的执行效率较高。
开启优化功能之后,GCC生成的代码完全一样。本文不在对它进行介绍。