本节书摘来异步社区《HBase权威指南》一书中的第1章,第1.1节,作者: 【美】Lars George 译者: 代志远 , 刘佳 , 蒋杰 责编: 杨海玲,更多章节内容可以访问云栖社区“异步社区”公众号查看。
1.1 海量数据的黎明
我们生活在一个互联网时代,无论是想搜索最佳的火鸡菜谱,还是送妈妈什么样的生日礼物,都希望能够通过互联网迅速地检索到问题的答案,同时希望查询到的结果有用,而且非常切合我们的需要。
因此,很多公司开始致力于提供更有针对性的信息,例如推荐或在线广告,这种能力会直接影响公司在商业上的成败。现在类似Hadoop②这样的系统能够为公司提供存储和处理PB级数据的能力,随着新机器学习算法的不断发展,收集更多数据的需求也在与日俱增。
以前,因为缺乏划算的方式来存储所有信息,很多公司会忽略某些数据源,但是现在这样的处理方式会让公司丧失竞争力。存储和分析每一个数据点的需求在不断增长,这种需求的增长直接导致各公司电子商务平台产生了更多的数据。
过去,唯一的选择就是将收集到的数据删减后保存起来,例如只保留最近N天的数据。然而,这种方法只在短期内可行,它无法存储几个月或几年收集到的所有数据,因此建议:构建一种数学模型覆盖整个时间段或者改进一个算法,重跑以前所有的数据,以达到更好的效果。
对于海量数据的重要性,Ralph Kimball博士指出③:
“数据资产会取代20世纪传统有形资产的地位,成为资产负债表的重要组成部分。”
还指出:
“数据的价值已经超越了传统企业广泛认同的价值边界。”
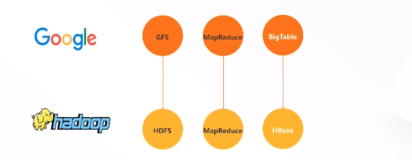
Google和Amazon是认识到数据价值的典范,它们已经开始开发满足自己业务需求的解决方案。例如,Google在一系列的技术出版物中描述了基于商业硬件的可扩展的存储和处理系统。开源社区利用Google的这些思想实现了开源Hadoop项目的两个模块:HDFS和MapReduce。
Hadoop擅长存储任意的、半结构化的数据,甚至是非结构化的数据,可以帮助用户在分析数据的时候决定如何解释这些数据,同样允许用户随时更改数据分类的方式:一旦用户更新了算法,只需要重新分析数据。
目前Hadoop几乎是所有现有数据库系统的一种补充,它给用户提供了数据存储的无限空间,支持用户在恰当的时候存储和获取数据,并且针对大文件的存储、批量访问和流式访问做了优化。这使得用户对数据的分析变得简单快捷,但是用户同样需要访问分析后的最终数据,这种需求需要的不是批量模式而是随机访问模式,这种模式相对于在数据库系统来说,相当于一种全表扫描和使用索引。
通常用户在随机访问结构化数据的时候都会查询数据库。RDBMS在这方面最为突出,但是也有一些少量的有差异的实现方式,比如面向对象的数据库。大多数RDBMS一直遵守科德十二定律(Codd’s 12 rules)④,这个定律对于RDBMS来说是刚性标准,并且由于RDBMS的底层架构是经过仔细研究的,所以在相当长的一段时间里这种架构都不会有明显的改变。近年来出现的各种处理方法,如列式存储的(column-oriented)数据库和大规模并行处理(Massively Parallel Processing,MPP)数据库,表明业界重新思考了技术方案以满足新的工作负载,但是大多数解决方案仍旧是基于科德十二定律来实现的,并没有打破传统的法则。
列式存储数据库
列式存储数据库以列为单位聚合数据,然后将列值顺序地存入磁盘,这种存储方法不同于行式存储的传统数据库,行式存储数据库连续地存储整行。图1-1形象地展示了列式存储和行式存储的不同物理结构。
列式存储的出现主要基于这样一种假设:对于特定的查询,不是所有的值都是必需的。尤其是在分析型数据库里,这种情形很常见,因此需要选择一种更为合适的存储模式。
在这种新型的设计中,减少I/O只是众多主要因素之一,它还有其他的优点:因为列的数据类型天生是相似的,即便逻辑上每一行之间有轻微的不同,但仍旧比按行存储的结构聚集在一起的数据更利于压缩,因为大多数的压缩算法只关注有限的压缩窗口。
像增量压缩或前缀压缩这类的专业算法,是基于列存储的类型定制的,因而大幅度提高了压缩比。更好的压缩比有利于在返回结果时降低带宽的消耗。

值得注意的是,从典型RDBMS的角度来看,HBase并不是一个列式存储的数据库,但是它利用了磁盘上的列存储格式,这也是RDBMS与HBase最大的相似之处,因为HBase以列式存储的格式在磁盘上存储数据。但它与传统的列式数据库有很大的不同:传统的列式数据库比较适合实时存取数据的场景,HBase比较适合键值对的数据存取,或者有序的数据存取。
如今数据的产生速度比几年以前已经有了迅猛的增长,随着全球化步伐加快,这个增长速度只会越来越迅猛,由此所产生的数据处理问题也会越来越严峻。像Google、Amazon、eBay和Facebook这样网站的用户已经覆盖到了地球上的绝大多数人。全球化网络应用(planet-size web application)的概念已经形成,在这种背景下,企业使用HBase更合适。
举例来说,Facebook每天增量存储到它们Hadoop集群的数据量超过15 TB⑤,并且随后会对所有这些数据进行处理。这些数据一部分是点击流日志,用户点击了它们的网站或点击了使用Facebook提供的社交插件的网站,每一步点击操作都会被记录并保存,这非常适合以批处理的模式,为预测和推荐系统构建机器学习模型。
Facebook还有一个实时组件,就是它们的消息系统,其中包括聊天、涂鸦墙和电子邮件,每个月会产生超过1350亿条数据⑥,存储几个月之后便会产生一个量级庞大的尾部数据,并且这些尾部数据需要被有效地处理。尽管电子邮件中占用存储量较大的部分(如附件)通常存储在二级系统中⑦,但这些消息产生的数据量还是令人难以置信的。以Facebook的数据产生条目为基础,假如按Twitter中的每条数据占用140字节来计算,Facebook每个月将会产生超过17 TB的数据,在将这些数据导入到HBase之前,现存的系统每个月也要处理超过25 TB的数据。⑧
目前在少数的重点行业中,面向Web业务的公司收集的数据量也在不断增长。
金融
如股票涨跌产生的数据。
生物信息学
如全球生物多样性信息机构(Global Biodiversity Information Facility,http://www.gbif.org/)。
智能电网
如OpenPDC(http://openpdc.codeplex.com/)项目。
销售
如销售终端(POS机)产生的数据,或者是股票系统、库存系统。
基因组学
如Crossbow(http://bowtie-bio.sourceforge.net/crossbow/index.shtml)项目。
移动电话服务、军事、环境工程
也产生了海量的数据。
有效存储PB级的数据并能高效地检索和更新并不是一件容易的事情。下面深入探讨一下我们将面临的挑战。