本节书摘来自异步社区《贝叶斯思维:统计建模的Python学习法》一书中的第1章,第1.5节,作者【美】Allen B. Downey,更多章节内容可以访问云栖社区“异步社区”公众号查看
1.5 历时诠释
还有另外一种理解贝叶斯定理的思路:它给我们提供的是一种根据数据集D的内容变化更新假设概率H的方法。
这种对贝叶斯定理的理解被称为“历时诠释”。
“历时”意味着某些事情随着时间而发生;在本例,即是假设的概率随着看到的新数据而变化。
在考虑H和D的情况下,贝叶斯定理的表达式可以改写成:
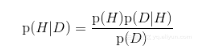
在这种解释里,每项意义如下:
- p(H)称为先验概率,即在得到新数据前某一假设的概率。
- p(H |D)称为后验概率,即在看到新数据后,我们要计算的该假设的概率。
- p(D|H)是该假设下得到这一数据的概率,称为似然度。
- p(D)是在任何假设下得到这一数据的概率,称为标准化常量。
有些情况,我们可以基于现有背景信息进行计算。比如在曲奇饼问题中,我们就将随机选中碗1或碗2的概率假设为均等。
在其他情况下,先验概率是偏主观性的;对某一先验概率,理性派的人可能会有不同意见,或许由于他们使用不同的背景信息做出判断,或者因为他们针对相同的前提条件做出了不同的解读。
似然度是贝叶斯计算中最简单的部分,在曲奇饼问题中曲奇饼来自来自哪个碗,则我们就计算那个碗中香草曲奇饼的概率。
标准化常量则有些棘手,它被定义为在所有的假设条件下这一数据出现的概率,但因为考虑的正是最一般的情况,所以不容易确定这个常量在具体应用场合的现实意义。
最常见的,我们可以指定一组如下的假设集来简化。
互斥的:集合中,至多一个假设为真。
完备的:集合中,至少一个假设必为真,且集合包含了所有的假设。
我使用suite这个词来表示具备上述属性的假设集。
在曲奇饼问题中,仅有两个假设:饼干来自碗1或者碗2,它们就是互斥的和完备的。
在本例中,我们可以用全概率公式计算p(D),即如果发生某一事件有互不容的两个可能性,可以像下面这样累加概率:
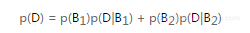
代入饼干问题中的实际值,得到:
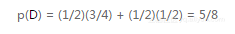
我们早前心算得到的结果也是一样的。
