本节书摘来自异步社区《贝叶斯思维:统计建模的Python学习法》一书中的第1章,第1.4节,作者【美】Allen B. Downey,更多章节内容可以访问云栖社区“异步社区”公众号查看
1.4 贝叶斯定理
现在,我们准备好进行贝叶斯定理推导需要的所有条件了。首先,我们注意到,联合概率是乘积可交换(乘法交换律)的,即:
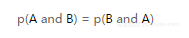
对于任何A,B表示的事件都成立。
然后,我们写出一个联合概率的表达式:
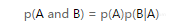
由于我们并没有明确定义A和B的含义,因而可以对A、B进行互换操作。
交换它们的位置:
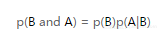
把这些表达式连接起来,我们得到下面的表达式:
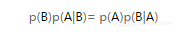
这意味着我们有两种方式计算联合概率,已知p(A),乘以p(B|A);或者从另一方向,已知p(B),乘以p(A|B)。两种方法是相同的。
最后,将上式除以p(B),得到:
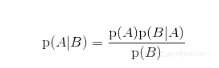
这正是贝叶斯定理!看起来不起眼,不过它会显示出令人吃惊的强大之处。
例如,我们可以用它来解决曲奇饼问题。
假设B1表示曲奇饼属于碗1的概率,V表示曲奇饼是香草曲奇饼的概率。
带入贝叶斯定理我们得到:
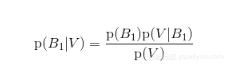
等式左边就是我们希望得到的,一块香草曲奇饼来自碗1的概率。
等式的右边表示:
- p(B1):这是我们忽略得到曲奇饼这个条件时(零条件下)选中碗1的概率。因为选择碗的过程是随机的,我们可以假设p(B1)=1/2。
- p(V|B1):这是从碗1得到一个香草曲奇饼的概率=3/4。
- p(V):从任意碗里得到一个香草曲奇饼的概率。因为考虑到选择碗的机会均等,而且每个碗的曲奇饼数量都是40,得到曲奇饼的机会是相同的。两个碗中香草和巧克力曲奇饼总数各是50和 30,因此p(V)=5/8。
把它们放在一起,我们得到:
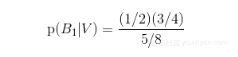
结果是3/5。所以,“得到一块香草曲奇饼”是支持于假设“来自碗1”的证据,因为香草曲奇饼来自碗1的可能性更大。
这个例子演示了一个应用贝叶斯定理的案例:它提供了一个从p(B|A) 得到p(A|B)的策略。
这种策略在解决类似“曲奇饼问题”的情况下是有用的,即从贝叶斯等式的右边计算要比左边容易的情况下。
