本节书摘来异步社区《TensorFlow技术解析与实战》一书中的第1章,第1.2节,作者:李嘉璇,更多章节内容可以访问云栖社区“异步社区”公众号查看。
1.2 什么是深度学习
深度学习,顾名思义,需要从“深度”和“学习”两方面来谈。
1.深度
深度学习的前身是人工神经网络(artificial neural network,ANN),它的基本特点就是试图模仿人脑的神经元之间传递和处理信息的模式。神经网络这个词本身可以指生物神经网络和人工神经网络。在机器学习中,我们说的神经网络一般就是指人工神经网络。
图1-3给出的是一个最基本的人工神经网络的3层模型。
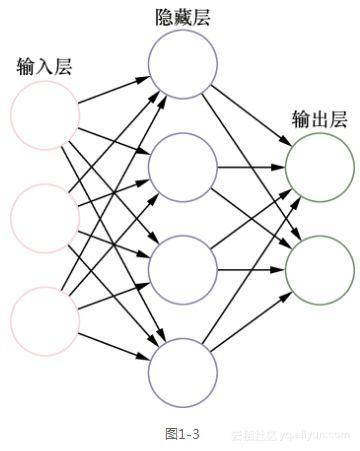
人工神经网络由各个层组成,输入层(input layer)输入训练数据,在输出层(output layer)输出计算结果,中间有1个或多个隐藏层(hidden layer),使输入数据向前传播到输出层。“深度”一词没有具体的特指,一般就是要求隐藏层很多(一般指5层、10层、几百层甚至几千层)。
人工神经网络的构想源自对人类大脑的理解——神经元的彼此联系。二者也有不同之处,人类大脑的神经元是按照特定的物理距离连接的,而人工神经网络有独立的层和连接,还有数据传播方向。
例如,我们拿一张图片,对它做一些预处理,如图像居中、灰度调整、梯度锐化、去除噪声、倾斜度调整等,就可以输入到神经网络的第一层。然后,第一层会自己提取这个图像的特征,把有用的特征向下传递,直到最后一层,然后输出结果。这就是一次前向传播(forword propagation)。
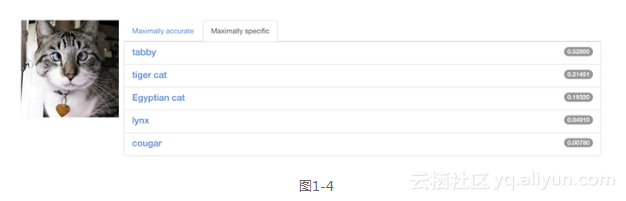
最后一层的输出要给出一个结论,例如,在分类问题中,要告诉我们到底输入的图像是哪个类别,一般它会给出一个“概率向量”。如图1-4所示,列出了这只猫所属品种的前5个概率值。
人工神经网络的每一层由大量的节点(神经元)组成,层与层之间有大量连接,但是层内部的神经元一般相互独立。深度学习的目的就是要利用已知的数据学习一套模型,使系统在遇见未知的数据时也能够做出预测。这个过程需要神经元具备以下两个特性。
(1)激活函数(activation function):这个函数一般是非线性函数,也就是每个神经元通过这个函数将原有的来自其他神经元的输入做一个非线性变化,输出给下一层神经元。激活函数实现的非线性能力是前向传播(forword propagation)很重要的一部分。
(2)成本函数(cost function):用来定量评估在特定输入值下,计算出来的输出结果距离这个输入值的真实值有多远,然后不断调整每一层的权重参数,使最后的损失值最小。这就是完成了一次反向传播(backword propagation)。损失值越小,结果就越可靠。
神经网络算法的核心就是计算、连接、评估、纠错和训练,而深度学习的深度就在于通过不断增加中间隐藏层数和神经元数量,让神经网络变得又深又宽,让系统运行大量数据,训练它。
2.学习
什么是“学习”?有一些成语可以概括:举一反三、闻一知十、触类旁通、问牛知马、融会贯通等。计算机的学习和人类的学习类似,我们平时大量做题(训练数据),不断地经过阶段性考试(验证数据)的检验,用这些知识和解题方法(模型)最终走向最终(测试数据)的考场。
最简单也最普遍的一类机器学习算法就是分类(classification)。对于分类,输入的训练数据有特征(feature),有标记(label),在学习中就是找出特征和标记间的映射关系(mapping),通过标记来不断纠正学习中的偏差,使学习的预测率不断提高。这种训练数据都有标记的学习,称为有监督学习(supervised learning)。
无监督学习(unsupervised learning)则看起来非常困难。无监督学习的目的是让计算机自己去学习怎样做一些事情。因此,所有数据只有特征而没有标记。
无监督学习一般有两种思路:一是在训练时不为其指定明确的分类,但是这些数据会呈现出聚群的结构,彼此相似的类型会聚集在一起。计算机通过把这些没有标记的数据分成一个个组合,就是聚类(clustering);二是在成功时采用某种形式的激励制度,即强化学习(reinforcement learning,RL)。对强化学习来说,它虽然没有标记,但有一个延迟奖赏与训练相关,通过学习过程中的激励函数获得某种从状态到行动的映射。强化学习一般用在游戏、下棋(如前面提到的AlphaGo)等需要连续决策的领域。(6.7.1节会讲解强化学习的应用。)
有人可能会想,难道就只有有监督学习和无监督学习这两种非黑即白的关系吗?二者的中间地带就是半监督学习(semi-supervised learning)。对于半监督学习,其训练数据一部分有标记,另一部分没有标记,而没标记数据的数量常常极大于有标记数据的数量(这也符合现实,大部分数据没有标记,标记数据的成本很大)。它的基本规律是:数据的分布必然不是完全随机的,通过结合有标记数据的局部特征,以及大量没标记数据的整体分布,可以得到比较好的分类结果。
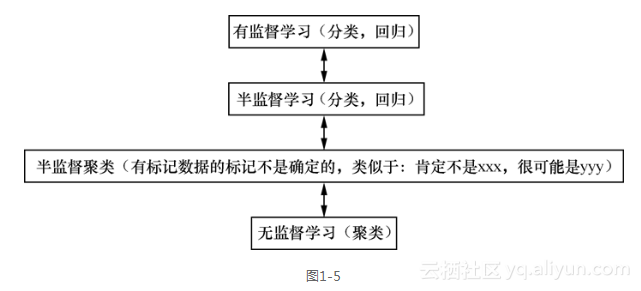
因此,“学习”家族的整体构造如图1-5所示[3]。
关于有监督学习和无监督学习在实战中的应用,会在本书“实战篇”中介绍。