本节书摘来自异步社区《数据科学与大数据分析——数据的发现 分析 可视化与表示》一书中的第2章,第2.3节,作者【美】EMC Education Services(EMC教育服务团队),更多章节内容可以访问云栖社区“异步社区”公众号查看
2.3 第2阶段:数据准备
数据分析生命周期的第2阶段是数据准备,其中包括在建模和分析前对数据的探索、预处理和治理。在这一阶段,团队需要建立一个强大的用于探索数据的非生产环境。通常,这个环境是一个分析沙箱。为了将数据导入沙箱,团队需要执行对数据的提取、转换操作和加载,即ETLT。一旦数据被导入沙箱,团队需要了解和熟悉这些数据。详细了解数据是项目成功的关键。团队还必须决定如何治理和转换数据,使其格式便于后续分析。团队可以利用数据可视化来帮助团队成员了解数据,包括数据趋势、异常值、数据变量之间的关系。本节将讨论数据准备阶段的每个步骤。
数据准备往往是分析生命周期中最费力的。事实上常见的是,在数据科学项目中至少50%的团队时间都花在这个重要阶段。如果不能获取到足够高质量的数据,团队可能无法进行生命周期过程中的后续阶段。
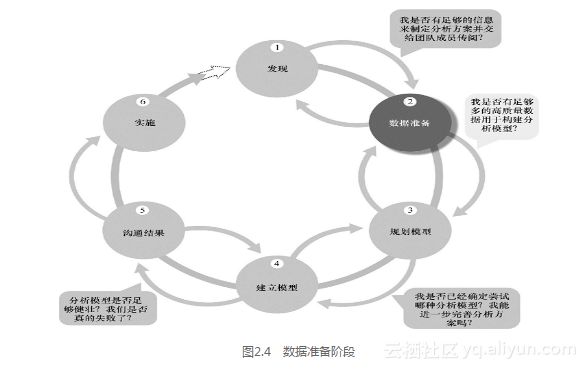
图2.4显示了数据分析生命周期的第2阶段。通常,数据准备阶段是最繁复的,同时又是最容易被团队轻视的。这是因为大多数团队和领导者都急于开始分析数据、检验假设、获得第1阶段提出的一些问题的答案。许多人会在没有花足够时间准备数据的情况下就急于跳到第3和第4阶段去快速开发模型和算法。结果,当他们发现手中的数据无法兼容想要执行的模型时,他们又不得不回到第2阶段。
2.3.1 准备分析沙箱
数据准备阶段的第1个子阶段,团队需要获取一个分析沙箱(通常也称为工作区),以便在不干扰到生产数据库的前提下探索数据。假设团队需要处理公司的财务数据,那么团队应该在分析沙箱中用财务数据的拷贝进行分析,而不是直接用公司的生产数据库进行分析。直接操作生产数据库是受到严格控制的,只有在制作财务报表时才能进行。
当准备分析沙箱时,最好能收集所有数据放入沙箱,因为团队成员在进行大数据分析时需要访问大量的不同种类的数据。取决于计划进行的分析,这些数据可能包括汇总的聚合数据、结构化数据、原始数据,以及从通话记录和网页日志中获取的非结构化文本数据。
这种全盘收集数据的方式和许多IT组织机构提倡的方式非常不同。许多IT部门只会为特定目的提供特定数据段的访问。通常,IT部门的心态是提供最少的数据,让团队实现目标即可,而数据科学团队则想着拿到所有数据。对于数据科学团队来说,数据越多越好,因为数据科学项目通常混合了目的驱动型分析和测试各种想法的实验性方法。在这种情况下,如果访问每个数据集和每个数据属性都需要单独申请,这对于数据科学团队是非常有挑战的。由于在数据访问和数据使用上有不同的考量,数据科学团队与IT部门的合作至关重要,一定要共同明确需要完成什么样的目标,并且目标一致。
在与IT团队沟通时,数据科学团队需要证明一个独立于组织机构内由IT部门管理的传统数据仓库的分析沙箱的必要性。为了在数据科学团队和IT部门之间取得成功且良好的平衡,需要在多个团队和数据所有者之间建立积极的工作关系。而这样做产生的回报是巨大的。分析沙箱使得组织机构可以执行目标更远大的数据科学项目,超越传统数据分析和商业智能的范畴,进行更为强大和高级的的预测分析。
沙箱可能会很大。它可能包含原始数据、聚合数据和其他在组织机构不常使用的数据类型。沙箱的大小可以根据项目的不同有所变化。一个有用的准则是沙盘至少应该是原始数据集的5~10倍大小,部分原因在于项目中数据的多份拷贝可能被分别用来创建特定的数据表或存储以进行特定的数据分析。
尽管分析沙箱是一个相对较新的概念,已经有公司着手于这一领域,寻找沙箱和工作区的解决方案,以便数据科学团队能够采用一种可被IT部门所接受的方式来访问和处理数据集。
2.3.2 执行ETLT
当团队开始转换数据时,需要确保分析沙盘拥有足够的带宽和可靠的网络来连接到底层数据源,以进行不间断的数据读写。在ETL过程中,用户从数据存储中提取数据,执行数据转换,并将数据加载回数据存储。然而,分析沙箱方法略有不同,它主张先提取、加载,然后转换,即ELT。在这种情况下,数据是以原始格式提取的,然后加载到数据存储中,在那里分析员可以选择将数据转换到一个新的状态或者保持它的原始状态。使用这种方法是因为保留原始数据并将它在发生任何转变之前保存到沙箱具有重要的价值。
例如,考虑信用卡欺诈检测的分析案例。很多时候,数据中的异常值代表着象征信用卡欺诈行为的高风险交易。使用ETL的话,这些异常值在被加载到数据存储之前,可能就已经被无意中过滤掉或者被转换和清洗。在这种情况下,用于评估欺诈活动的数据已经被无意中丢弃,团队也就无从进行相应的分析。
遵循ELT方法可以在数据存储中为团队提供干净的数据用于分析,也可以让团队访问数据的原始形式,以查找数据中隐藏的细微差别。分析沙箱的大小之所以能够快速增长,部分原因正在于采用了ELT方法。团队既可能想要干净的数据和聚合的数据,也可能需要保存一份原始格式的数据以进行比较,或者是在清洗数据前找到数据中隐藏的模式。这整个过程可以被概括为ETLT,意味着团队可以选择在一个分析案例中执行ETL,而在另一个案例中执行ELT。
根据数据源的大小和数量,团队可能需要考虑如何将数据并行地导入到沙箱。导入大量数据有时候被称为Big ETL。数据导入可以使用Hadoop或MapReduce等技术并行化。我们将在第10章中详细介绍这些技术,它们可以用于执行并行数据摄取,以及在很短的一段时间内并行产生大量的文件或数据集。Hadoop可以用于数据加载以及后续阶段的数据分析。
在将数据导入到分析沙箱之前,确定要在数据上执行的转换。这涉及评估数据质量和构建合适的数据集,以便在后续阶段的分析。此外,考虑团队将可以访问哪些数据,以及需要从数据中生成哪些新的数据属性来支持分析,也很重要。
作为ETLT的一部分,建议盘点数据,并将当前可用的数据与团队需要的数据进行比较。这种差距分析能帮助理解团队目前可以利用的数据集,以及团队需要在何时何地开始收集或访问当前不可用的新数据集。这个子过程涉及从可用源提取数据,以及确定用于原始数据、在线事务处理(OLTP)数据库、联机分析处理(OLAP)数据集或其他数据更新源的数据连接。
应用程序编程接口(API)是一种越来越流行的访问数据源的方式[8]。现在许多网站和社交网络应用程序都提供可以访问数据的API,用于为项目提供支持,或者补充团队正在处理的数据集。例如,通过Twitter API可以下载数以百万计的Twitter信息,用于对一个产品、一个公司或一个想法的情感分析项目。大部分的Twitter数据都是公开的,可以在项目中和其他数据集一起被使用。
2.3.3 研究数据
数据科学项目的关键之一是熟悉数据。通过花时间了解数据集的细微差别,可以帮助理解什么是有价值的和预期的结果,以及什么是意外的发现。此外,重要的是要对团队可以访问的数据源进行归类,并识别团队可以利用但是暂时无法访问的其他数据源。这里做的一些事情可能会与在发现阶段对数据集的初始调查有重叠。研究数据是为了达成几个目标。
明确数据科学团队在项目时可以访问的数据。
识别组织机构内那些对团队来说可能有用但是暂时还无法访问的数据集。这样做可以促使项目人员开始与数据拥有者建立联系,并寻找合适的方法分享数据。此外,这样做可以推动收集有利于组织机构或者一个特定的长期项目的新数据。
识别存在于组织机构外的,可以通过开放的API、数据共享,或者购买的方式获取的新数据,用于扩充现有数据集。
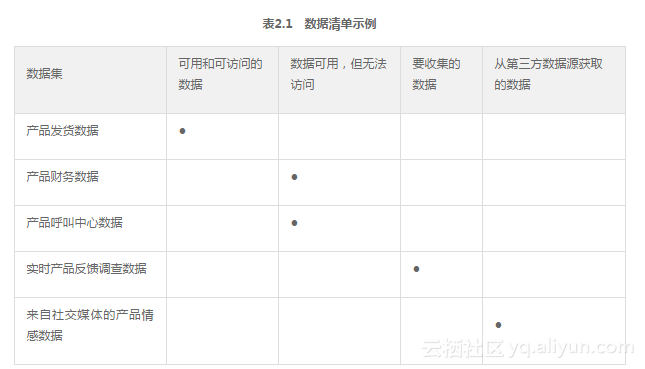
表2.1展示了一种数据清单的组织方法。
2.3.4 数据治理
数据治理(data conditioning)是指清洗数据、标准化数据集和执行数据转换的过程。作为数据分析生命周期中的一个关键步骤,数据治理可以涉及许多关联数据集,合并数据集,或者其他使数据集日后能被分析的复杂操作。数据治理通常被视为数据分析的预处理步骤,因为在开发模型来处理或分析数据之前,数据治理还需要对数据集进行多种操作。这意味着数据治理是由IT部门、数据所有者、DBA或者数据工程师执行的。然而,让数据科学家参加数据治理也很重要,因为数据治理阶段所做的许多决策会影响到后续的分析,包括确定特定数据集的哪些部分将被用于后续阶段的分析。团队在这一阶段开始需要决定保留哪些数据,转换或丢弃哪些数据,而这些决策应由大多数团队成员共同参与。如果让一个人来拍板,可能会导致团队日后返回这一阶段来获取已经被丢弃的数据。
在前面信用卡欺诈检测的案例中,团队在选择要保留的数据和要丢弃的数据时需要深思熟虑。如果团队在数据处理的过程中过早地丢弃了许多数据,可能会导致重新回溯前面的步骤。通常,数据科学团队宁愿保存更多而不是更少的数据用于分析。与数据治理相关的其他问题和考量如下所示。
数据源是什么?目标字段是什么(例如,数据表的列)?
数据有多干净?
文件和内容一致吗?如果数据包含的值与正常值有偏差,确定数据值缺失和数据值不一致到哪种程度?
评估数据类型的一致性。例如,如果团队期望某些数据是数值型的,要确认它是数值型的或者是字母数字字符串和文本的混合。
审查数据列的内容或其他输入,并检查以确保它们有意义。例如,如果项目涉及分析收入水平,则要预览数据确定收入值都是正值,如果是0或者负值需确认是否可接受。
寻找任何系统性错误的证据。比如由于传感器或其他数据源的不为人察觉的损坏,导致数据失效、不正确,或者缺失数据值。此外,要审查数据以衡量数据的定义在所有的尺度标准下是否是相同的。在某些情况下,数据列被重新调整,或者是数据列被停止填充,而且这些变化并没有被注释或没有通知给其他人。
2.3.5 调查和可视化
在团队收集和获得用于后续分析的部分数据集后,一种有用的步骤是利用数据可视化工具来获得数据的概述。观察数据的抽象模式可以帮助人们快速理解数据特征。一个例子是使用数据可视化来检查数据质量,比如数据是否包含很多非预期值或者其他脏数据的迹象(脏数据将在第3章进一步讨论)。另一个例子是数据倾斜(skewness),比如,大部分数据集中在某个数值或者连续统(continuum)的一端。
Shneiderman[9]因其可视化数据分析的理念(即全盘观察,放大及过滤,然后按需获取细节)而众所周知。这是一个务实的可视化数据分析方法。它允许用户找到感兴趣的领域,然后通过放大和过滤来找到与数据的特定区域相关的更详细信息,最后找到特定区域背后详细的数据。这种方法提供了数据的一个高层视图,可以在相对较短的时间内获悉给定数据集的大量信息。
当该方法与数据可视化工具或统计软件包一起使用时,推荐下述指导意见和考量。
审查数据以确保针对一个数据字段的计算在列内或者在表间保持一致。例如,客户寿命的值在数据收集的中期有改变吗?或者当处理财务信息时,利率计算是否在年底由单利变为复利?
所有数据的数据分布是否都保持一致?如果没有,应该采取怎样的措施来解决这个问题?
评估数据的粒度、取值范围和数据聚合水平。
数据是否代表目标群体呢?对于营销数据,如果项目关注的是育儿年龄的目标客户,数据是否代表这些群体?还是也包含老年人和青少年?
对于与时间相关的变量,是以每日、每周还是每月来测量呢?这些测量间隔是否足够?是否都在以秒计算时间?或者有些地方以毫秒为单位?确定分析所需的数据粒度,并评估当前数据的时间戳级别能够满足需要。
数据是标准化/规范化的吗?数据尺度一致吗?如果不是,数据是如何不一致或不规则的?
对于地理空间数据集,数据中的州或国家的缩写一致吗?人的姓名是规范化的吗?是英制单位还是公制单位?
当团队评估项目中所获得的数据时,这些典型的考量应该是思考过程的一部分。在后面阶段构建和运行模型时,对数据的深入了解非常关键。
2.3.6 数据准备阶段的常用工具
这个阶段有下面几种常用的工具。
Hadoop[10]可以执行大规模并行数据摄取和自定义分析,可用于Web流量解析、GPS定位分析、基因组分析,以及来自多个源的大规模非结构化数据的整合。
Alpine Miner[11]提供了一个图形用户界面(GUI)来创建分析工作流程,包括数据操作和一系列分析事件,例如在Postgress SQL和其他大数据源上的分段数据挖掘技术(例如,首先选择前100名顾客,然后运行描述性统计和聚类)。
Openrefine(以前称为Google Refine)[12]是一个免费、开源、强大的杂乱数据处理工具。这是一个流行的带GUI的工具,用于执行数据转换,而且是目前可用的最强大的免费工具之一。
Data Wrangel[13]和OpenRefine相似,是一个用于数据清洗和转换的交互式工具。Data Wrangler是斯坦福大学开发的,可以对一个给定的数据集执行许多转换。此外,数据转换的输出可以使用JAVA或Python处理。这个特性的优点是,可以通过Data Wrangler的GUI界面来操控数据的一个子集,然后相同的操作可以以JAVA或Python代码的方式用来在本地分析沙箱中对更大的完整数据集进行离线分析。
在第2阶段,数据科学团队需要来自IT部门、DBA或EDW管理员的帮助,以获取需要使用的数据源。