本节书摘来自异步社区《数据科学:R语言实战》一书中的第1章,第1.3节,作者 【美】Dan Toomey(丹·图米),更多章节内容可以访问云栖社区“异步社区”公众号查看
1.3 关联规则
关联规则说明了两个数据集之间的关联。此规则常用于购物篮分析。一组事务中的每个事务(购物袋)可能包含多个不同项目,那么如何能够让产品销售有关联呢?常见关联如下所示。
- 支持度:这是事务同时包含A和B的百分比。
- 置信度:这是事物已经包含A的情况下包含B的百分比(规则正确)。
- 提升度:这是置信度与包含B情况下百分比的比率。请注意:若提升度为
1,则A和B是独立的。
关联的挖掘
在关联规则中,R中广泛使用的工具是apriori。
1.用法
可调用apriori规则的程序库,如下所示:
apriori(data, parameter = NULL, appearance = NULL, control = NULL)下表对apriori程序库的不同参数进行了说明。
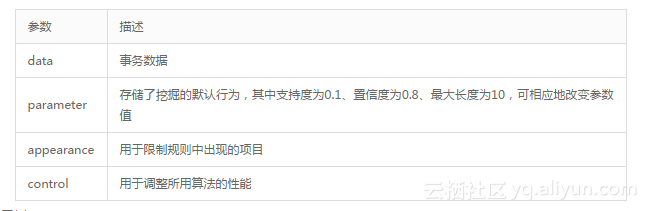
2.示例
需要加载apriori规则的程序库,如下所示:
> install.packages("arules")
> library(arules)加载购物篮数据:
> data <- read.csv("http://www.salemmarafi.com/wp-content/
uploads/2014/03/groceries.csv")然后,我们可以从数据中生成规则:
> rules <- apriori(data)
parameter specification:
confidenceminvalsmaxaremavaloriginalSupport support minlenmaxlen
target
0.8 0.1 1 none FALSE TRUE 0.1 1
10 rules
ext
FALSE
algorithmic control:
filter tree heap memopt load sort verbose
0.1 TRUE TRUE FALSE TRUE 2 TRUE
apriori - find association rules with the apriori algorithm
version 4.21 (2004.05.09) (c) 1996-2004 Christian Borgelt
set item appearances ...[0 item(s)] done [0.00s].
set transactions ...[655 item(s), 15295 transaction(s)] done [0.00s].
sorting and recoding items ... [3 item(s)] done [0.00s].
creating transaction tree ... done [0.00s].
checking subsets of size 1 2 3 done [0.00s].
writing ... [5 rule(s)] done [0.00s].
creating S4 object ... done [0.00s].在结果中有若干个突出的点:
正如从显示中所见,我们使用默认设置(置信度为0.8等)。
我们发现三个项目中有15295个事务(从655个全部可用项目中选取)。
我们生成了五个规则。
我们可以对已生成的规则进行检查,如下所示:
> rules
set of 5 rules
> inspect(rules)
lhsrhs support confidence lift
1 {semi.finished.bread=} => {margarine=} 0.2278522 1
2.501226
2 {semi.finished.bread=} => {ready.soups=} 0.2278522 1
1.861385
3 {margarine=} => {ready.soups=} 0.3998039 1
1.861385
4 {semi.finished.bread=,
margarine=} => {ready.soups=} 0.2278522 1
1.861385
5 {semi.finished.bread=,
ready.soups=} => {margarine=} 0.2278522 1
2.501226为了方便阅读,对代码的格式做了微调整。
仔细观察这些规则,发现在市场上购买面包、汤及人造黄油之间确实存在关系,至少在市场收集数据的时候是这样。
如果我们改变了计算中使用的参数(阈值),就会得到一组不同的规则。例如,核实下列代码:
> rules <- apriori(data, parameter = list(supp = 0.001, conf = 0.8))此代码生成了500多个规则,但是这些规则的含义值得质疑,原因在于,目前规则的置信度为0.001。

