本节书摘来自异步社区《谷歌语义搜索》一书中的第2章,第2.4节,作者【英】David Amerland,更多章节内容可以访问云栖社区“异步社区”公众号查看
2.4 你的业务与知识图谱
谷歌语义搜索
在我看来,知识的价值总是在于一旦你获得它之后你能得到什么。尽管出于知识的缘故,知识是一个有价值的目标,但它也是时间上的一种巨大浪费。例如,电只有在它被用来驱动一些东西的时候才是有益的。仅仅拥有它无助于释放它自身的价值,无助于让我们个人或者我们的世界受益。如果知道的东西没有被使用,我们就等同于不知道它。
如今,技术已使我们走在一条由意图而非存在构成的道路上。我们说世界是有线的、广泛连接起来的,业务所面向的那些人“总是打开着”,但奇怪的是这却让业务的每个潜在市场变得更小、更难去打开并且充满了由个性化的用法造成的高门槛。
普遍存在的联系还没有建立起一个全新的巨大市场。它已经启动了一个正加速发展的区位化(nichification1)进程。例如,考虑一下你典型的目标客户。没准你都很可能想不到,他(或她)在Web上,而Web可以通过台式机访问。即便笔记本电脑推广开来并为计算增加了大量的移动性之后,也没有太大的改变。Web仍然是Web,桌面搜索仍然是桌面搜索,而“客户”仍然在那儿。
面向这样的客户是很容易的。你需要一个网站、某种在线广告、(可能还有)电子邮件营销以及一些能将客户带回到你的网站的手段。你知道当客户要寻找信息时,他或她会去搜索,而搜索是由关键词主导的。排名是由入链主导的(因此你需要更多地构建),而信任则部分地是由网站设计和PageRank主导(所以你需要好的设计和一个高的PageRank值)。
这种“连点画图”一定程度上澄清了一些已经被漏掉的工作。当一个人搜索“世界上最好的披萨”时,如果你已经针对Web的特点做了一些事情,并且针对关键词“世界上最好的披萨”做了优化,那么你的网站才会出现。如果你已经积极建立了一个反向链接阵营,其中大量的其他网站以锚文本“世界上最好的披萨”反向链接到你,那么你的网站就会出现。如果你已经创建了大量的关于为什么你的餐馆做出了“世界上最好的披萨”的无意义的内容,那么你的网站就会出现。
也许某个地方的一些评论说到“嘿,你知道吗,这真不是世界上最好的披萨”,但它们被深深埋藏到以至大部分在线访客都看不到它们。并且,如果它们错误地反向链接到了你,你想要的关键词仍旧出现了,事实上对你的搜索排名而言利大于弊。也许有一些网站实际上在说你的“世界上最好的披萨”确确实实不是真的,但它们可能不会被发现。你的网站被更好地优化了,你的SEO团队成功了,并且你总是可以用编造的正面结果来埋藏负面结果。
你成为了搜索引擎世界的王者。
在前语义搜索时代,在线营销的成功是由一个人实际上能喊出多大声音所决定的。搜索引擎等价于外向营销(outbound marketing)。
以下是所发生的改变。
你的潜在受众如今在下面这些地方出现:
- 传统的桌面搜索;
- 移动搜索;
- 语音搜索;
- 预测式搜索(谷歌即时基于位置在用户的移动设备上预加载信息);
- 定制的搜索(由诸如亚马逊这样的商业网站建立);
- 手机应用软件(将信息和客户的注意力封锁在手机应用软件的边界以内);
- 个性化搜索(基于用户的搜索历史和社交联系呈现结果);
- 本地化搜索(使用位置感知技术基于你移动设备的GPS信号来呈现信息);
- 特定服务搜索(例如YouTube乃至Google+)。
如今,你的潜在客户执行一条搜索时所看到的结果是基于对他们查找目标的理解—精确到使得过去的SEO工作变得收效甚微。你的目标受众的社交联系和他们的个人线上行为也融入了这个影响到人们在执行搜索后能看到什么的复杂循环中。
其最终结果是过去只靠烧钱就能控制的搜索体验已经发生了不可逆转的改变。
我很庆幸如今像这样的搜索仿佛注定要失败。理所当然,读完所有这些并认识到问题的严重性之后,你可能会问你自己:面对如今搜索中的信息交叉引用自这么多源的这一事实,又还能做些什么来将搜索带回到有业务要运行、有产品要出售以及有人要养活的业务主的控制之下呢?
简短回答就是“能”。这一切之中的救命稻草在于语义搜索评价其提供结果的质量采用的三个标准在数学上模拟了我们过去村庄广场的决策过程:
- 信任(trust);
- 声誉(reputation);
- 权威(authority)。
就像任何与搜索有关的事物一样,也有特定的方式来建立它们、增强它们以及确保你在Web上的存在稳定到足以确保在任何搜索界面中的高曝光度。在这一混乱之中,我将奉上两束额外的希望之光:意外发现(serendipity)和引用(citation)。它们事实上都是被语义搜索的算法校正所采用的术语,并影响着你的业务在Web上被找到的能力。
它们很重要,因为有一些特定的触发它们的可行之事,于是它们成为你搜索引擎优化军火库中的新的智能武器。
以下是它们的工作原理。随着语义搜索提供给我们的结果越来越精确,一种理论上的危险是它将我们挡在我们需要的知识之外—如果其位于我们搜索查询的狭窄范围之外的话。我们一般认可的是,我们对于搜索的东西的描述往往是不精确的。可能有一些能够丰富我们的搜索、更好地回答它或者帮着我们发现一些略有些偏离我们想要通过搜索解决的问题的东西,其在我们搜索时恰好超出了我们关注的范围或者超出了我们的描述能力。
如果语义搜索无法支持这些,我们将不得不做多次搜索,试着去猜测我们漏掉了什么。这都不是对我们的时间或者对搜索的很好利用,并且未能增强总体的搜索体验。幸运的是,我们并不需要去这样做,我们有意外发现来应对。维基百科将意外发现定义为“一个‘幸福的意外’或者‘愉快的惊喜’;具体而言,是意外找到一些有益或者有用的东西,而并没有专门去搜索它”。这正是搜索引擎工程师们对它的理解。
在实际中,这意味着语义搜索背后的程序利用一些信号来找到可能不是与我们的搜索直接有关但又有一些相关的内容。信息来自于网络中源于分享和互动内容的社交信号,但它们也来自于其他搜索查询。
如果你熟悉亚马逊在每个产品底部的产品推荐“购买x的顾客也会购买y”,那么你就开始理解意外发现是怎样运转的了。亚马逊附加的产品推荐利用了成千上万其他买家的行为来试图预测一个意图。这背后的理论是如果有足够多的买过鼠标的人接下来也继续浏览并同时或者在之后订购一个护腕,那么这两者就通过一个可能也对你有效的价值建议关联起来。在多数情况下,这在其他你可能需要买的东西方面打开了你的思维,并节省了你日后的时间。
亚马逊在其进入搜索领域时是一个非常封闭的世界。尽管亚马逊的天地非常广阔,与巨大的Web相比仍然是非常渺小的。即便是亚马逊也不得不去筛选大量的数据,而仅仅是为了在其相关产品的推荐中取得一定程度的有意义的可靠性。
谷歌做着类似的事情,但它审视的是Web的全景而非一个在线购物环境和一些购买模式,并且使用了谷歌搜索以及终端用户输入的搜索查询。
关于搜索查询被使用的方式,阿姆斯特丹数学信息中心(Wiskundeen Informatics Centre)的研究人员Vera Hollink、Theodora Tsikrika和ArjendeVries发表了一篇题为《查询修改的语义》(The Semantics of Query Modification)的论文,展现了如何通过比较大量来自搜索引擎框的用户查询之间的关系,从而有可能识别一些语义修改模式—例如反映了用户经常搜索两个共享同一属性的实体(例如两个来自同一队伍的运动员)。那么就有可能使用这样的数据去为查询生成推荐,并且在质量方面优于过去那种根据记录被查询的数量来生成一个统计模型的统计方法。
意外发现在搜索编程的圈子里实际上叫做意外信息检索(serendipitous information retrieval),它支持创建一些我们将要讨论的方法,其能够在潜在客户的精确搜索查询没有包含你的品牌时,也能让它出现在他们的视野中。这些方法用一种至少看起来类似亚马逊的方式来扩展搜索结果。在编程上则有很大的区别,但在这里这与我们不是那么相关。我们要讨论的是这一特征可以用来在潜在客户的精确搜索查询没有包含你的品牌名称或者没有包含你可能已经用来帮助让你的内容显露于搜索中的任何关键词时,帮助你的品牌出现在他们的视野中的那些方式。
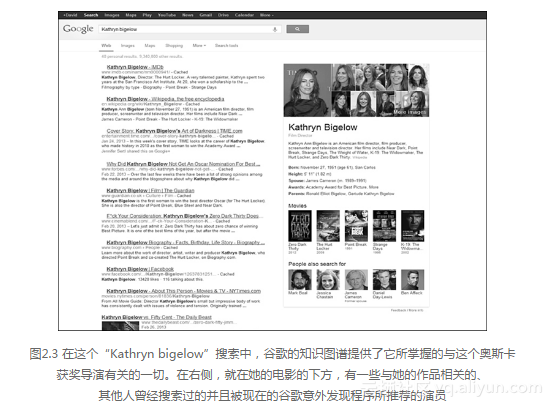
你注意到在搜索Kathryn Bigelow时,我根本没有输入图 2.3 中谷歌推荐的任何一个演员的名字,然而我却可以点击并找到更多关于他们、他们的职业生涯以及他们参演的其他电影的信息,就这样意外地发现相关的信息,这从知识的角度丰富了信息,并且这对于我所进行的搜索是完完全全的意外。
这里呈现出的潜力是那些利用了谷歌意外发现程序的业务可以让自己延伸到比传统SEO技术所能提供的更广的范围。
这里的可行之事如下所示。
创建广泛的内容来将你的业务涉及的一切都以一种有意义的方式联系起来(例如,如果你卖的是皮夹克,你可能想要拥有的内容是涉及皮革的道德采购,或者是关于皮革护理信息、皮革修复或者是非常喜欢皮夹克的好莱坞明星)。
引导社交媒体网络上的在线谈论,来拓展你的公司或品牌所涉及的范围。
用你的社交网络档案去链接到能为你做的事情增加额外价值的内容(例如,分享那些能够拓展你的营销范围的信息,像是一个自行车业务链接到各地的自行车道并拥有大量关于骑自行车度假的信息)。
如果意外发现正开始看起来像一种当你的潜在客户并未主动找寻你的业务时仍能闯入他们意识的良好途径,那么引用则是另一种途径。
搜索中的引用关注的是你的网站、公司或者品牌在Web上与特定品质的联合提及。回到我之前举的“城里面最好的披萨”的例子,如果你的披萨店的名字在Web上单独出现并时不时地与你的披萨的高质量联合提及,那么当人们查找“最好的披萨店”时,它就会作为一个选择出现,即便你事实上并没有做任何事情去推动它。
这种运转方式只在机器逻辑和搜索的情境中才令人震惊。在人们的真实世界中,信任、声誉和权威这三种品质是我们本能地用来评价我们是否想要与一个人或一个业务扯上关系的标准,这种通过我们个人网络中的间接联系点来找到我们信息的间接方式则是一种常态。
概括而言,知识图谱是等价于你在Web上的声誉(与你的业务关联的信息)、你拥有的权威(你被认为有多大的影响力)以及其他人对你的信任(你的产品的质量排名)的总和的搜索引擎结果。如果你有业务致力于为客户创造价值、提升其作为并不断发展以用真实的解决方案应对真实的需求,那么就有可以采纳的具体步骤来确保你被外界察觉到的信任、声誉和权威会帮助你实现更多的销售。
1nichification是指不仅客户能找到所需的商品或服务,广告也能主动找到潜在的客户。“区位化”可能不是一个很好的翻译,但译者尚未找到更好的译法。——译者注