本节书摘来自异步社区《谷歌语义搜索》一书中的第1章,第1.3节,作者【英】David Amerland,更多章节内容可以访问云栖社区“异步社区”公众号查看
1.3 语义搜索如何工作
谷歌语义搜索
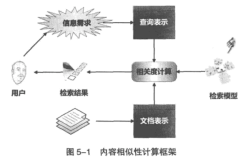
和普通的搜索一样,我们可以将语义搜索分解为几个组成部分来确切地了解它是怎样工作的—它与我们过去习惯了的搜索不太一样。更重要的是,来了解这种不同是如何发生的。
在我们深入细节之前,首先看一看图1.1将会很有帮助,其中展现了帮助建立语义搜索的那些元素。
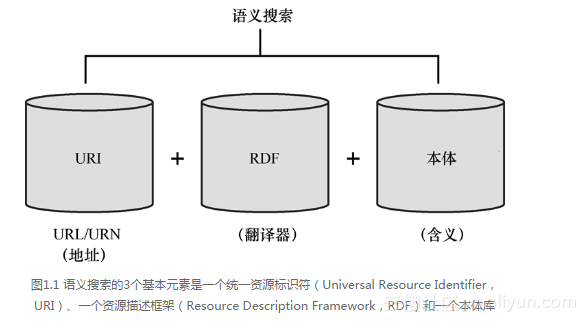
为了建立起能够用你我的方式理解字词的语义搜索,三个元素需要组合在一起。
首先是一个统一资源标识符(Universal Resource Identifier,URI)。这可以是我们都熟悉的Web上的一个URL,或者可以是一个统一资源名称(Universal Resource Name,URN)—这是一种特别的方式用来说明它是比如一个人的名字。URI是必要的,因为它是初始数据集的来源,是的,这个过程中仍然会涉及到一个蜘蛛。然而,仅有这个初始数据集是不够的。可以将它们视作海量的原始数据,在这个阶段它们还没什么用,需要进一步地分类和提炼。
正如甘蔗经过一道提炼工序将其从类似竹竿的东西变为了可以让我们的饮料和甜品变甜的细白砂糖,URI在其可用之前也需要进一步提炼。这种提炼在一个资源描述框架(Resource Description Framework,RDF)的帮助下完成。可以将RDF视作一个规则集,支持数据从存储这些URI的一个数据库向另外一个传输(或称翻译),并且既不丢失含义也不弄混取值。
为了阐明这一点,让我们来看一个简单的例子,即我在英国的家庭住址。我的住处由我的名字、门牌号、街道、城市、郡、邮政编码和国家组成。在一个英国数据库中,一个邮政编码由字母和数字组成。现在假设我的数据正被移植到一个美国数据库中,这样我才可以订阅一份美国印制的出版物。用以前的方式来做马上就会出现一些小问题。首先,在美国,郡被州代替了;其次,邮政编码(post code)通常称为美国邮编(ZIP code);第三,邮政编码的格式是不同的,通常全是数字。
如果没法告诉美国数据库它已经接收到的是哪类信息,就没法有意义地来使用,于是比方说我就不能订阅任何美国杂志,除非我决定移民到美国并在那儿买一幢房子。
幸运的是,RDF可以把我的英国数据翻译成那些对美国数据库而言有意义的字段,于是我就可以用我的曼彻斯特家庭住址收到从美国投递的杂志了。不仅如此,RDF 还允许美国数据库保持我的英国邮政编码格式,同时看起来它又是一个美国邮编。
因此,在这一情境中,RDF为一个网络爬虫或者蜘蛛所索引的原始数据提供了含义,并允许这些数据在几乎任何地方都有意义。我说的是几乎任何地方,是因为尽管给机器去读的数据可以是非常精确的,但人们使用的词却不是这样的。同一个词可以有不同的含义甚至不同的用法。这种歧义问题可以用本体(ontology)—即含义的汇集来解决。
例如,一个本体可以定义:地址在城市中,城市在郡中,郡在国家中。当有人问我们要我们的地址时,你我直觉就会如此理解,但机器却做不到,并且如果没有一个本体来指导它们,它们永远都做不到。
本体很容易被构造为一些类和这些类的一些子集,继而再为它们添加一条推理规则。例如,一条推理规则可能说如果一条地址在某个城市中,并且这个城市在某个郡中,那么这条地址就在那个郡中—即便没有提过这一点。因此,通过详述我的地址以及我住在英国曼彻斯特这一点,语义搜索可以像人一样容易地推导出我住在柴郡—即便我没有特别提过这一点。
计算机并没有真正理解我是一个英国居民、我的家在英国,以及英国被分为具有邮政编码而非美国邮编的若干个郡。但通过组合语义搜索的三个元素,计算机学会了翻译数据并将其以一种看起来智能的方式与特定的含义关联起来。某种意义上,如果我把自己的名字链接到那条地址上,计算机就会“知道”我是一个英国居民,而并不需要任何在线文档或数据曾提及这一点。语义搜索可以将它推导出来。更好的一点是,通过将我的地址关联到我的一种联系方式,也就可以把我的电话号码和电子邮件地址提出来呈现在搜索中,而不再需要去翻几十页来找到可以联系到我的最佳方式。
对于人来说显得有些笨重的本体却可以极好地在Web上工作。当网络爬虫们访问一个网站时,它们可以获得海量的数据而不会像人一样迷失其中或感到疲倦。过去它们所不能做的是像人一样搞清楚它们收集到的数据的含义。
然而,如今,随着引入了使用URI并通过RDF和本体来解析它的程序,数据获得了更精确的值从而允许谷歌的搜索从它索引的数据的关联中推导含义,并因此显得让我们觉得有些智能。
在图1.2中,通过搜索“works of da vinci”(达芬奇的作品),我们可以看到被赋予含义的数据之间的关联所形成的威力。过去这会返回一组截然不同的结果,很可能对我而言是不够精确的,因而我不得不重新用查询“works of Lenoardo da Vinci”(莱昂纳多·达芬奇的作品)来改进搜索。
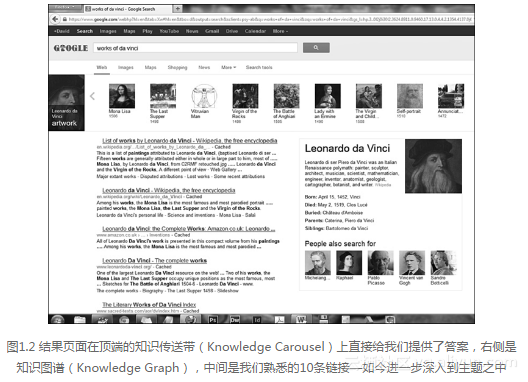
观察图1.2所示的搜索结果,我们发现这里的搜索算法已经聪明到能够理解“da vinci”指的是莱昂纳多·达芬奇以及我正在找他的艺术作品。在右侧它还给了我一些额外的个人简历信息,甚至建议了一些其他的相关搜索。
尽管这一特征和语义搜索的核心并没有直接的关联,但它对搜索结果页面仍是一个有价值的补充。它更正式一点的名字叫做意外发现(serendipity discovery),搜索技术中有一个领域都在处理意外信息检索以及支配它的驱动力。对我们来说,只要知道对于你业务的营销和你在未来找到客户的方式而言它有着巨大的影响就足够了,我们在本书中会探索这些影响,并将其形式化为能够帮助你利用它的一套实践。