本文把我通过Fluentd,把数据上传到DataHub的配置过程记录下来,希望对大家在配置中能有帮助。
安装
前序准备
本文使用一台CentOS 6.8的ECS来做测试的,机器上已经有yum。用户测试的时候,需要有一台能连接上公网的Linux机器。
-
安装依赖包
`yum -y install gcc gcc-c++ openssl* readline* ncurses* zlib* libxml* libjpeg* libpng* libxslt* libtool* ` - 下载并安装包
wget http://aliyun-datahub.oss-cn-hangzhou.aliyuncs.com/tools/fluentd-with-datahub-0.12.23.tar.gz&file=fluentd-with-datahub-0.12.23.tar.gz
tar -xzvf fluentd-with-datahub-0.12.23.tar.gz
cd fluentd-with-datahub这个wget的下载地址,是从文档里拿到的最新的安装包。以后版本可能会更新,用户也可以直接从文档上拿最新的安装包。
-
安装
目前安装包里只包含了ruby和插件的安装,没有提供fluentd的安装部分的脚本,这里可以做修改
vi install.sh
##修改里面的gem install --local fluent-plugin-datahub-0.0.1.gem,改成
gem install --local string-scrub-0.0.5.gem
gem install --local thread_safe-0.3.5.gem
gem install --local tzinfo-1.2.2.gem
gem install --local tzinfo-data-1.2016.4.gem
gem install --local sigdump-0.2.4.gem
gem install --local http_parser.rb-0.6.0.gem
gem install --local cool.io-1.2.3.gem
gem install --local yajl-ruby-1.2.1.gem
gem install --local msgpack-0.5.12.gem
gem install --local fluentd-0.12.23.gem
gem install --local fluent-plugin-datahub-0.0.2.gem
##注意以上版本号都是一键安装包里已经有的,以后如果版本更新,这里的版本号也从dependency_gem里看看当时提供的版本是多少
##wq保存退出
sudo sh install.sh最终结果是
配置
DataHub配置
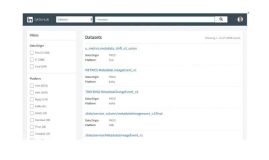
在DataHub的控制台里创建一个Project,然后创建一个Topic(Topic对应到数据库是一个表的概念)
因为只是测试,我这里就3个字段。
测试
我们在ECS上,用touch /tmp/test.log生成一个文件。我们通过fluentd监控这个文件的变化,并把变化的内容解析后传到datahub里。
配置Fluentd
这里,我们的datahub配置文件fluentd.conf的内容为
<source>
@type tail
path /tmp/test.log
tag test
format /(?<request_time>\d\d\d\d-\d\d-\d\d \d\d:\d\d:\d\d)\s\[(?<level>.+)\]\s(?<content>.+)/
</source>
<match test>
@type datahub
access_id your_access_id
access_key your_access_key
endpoint http://dh-cn-hangzhou.aliyuncs.com
project_name your_project_name
topic_name fluentd
column_names ["request_time", "level", "content"]
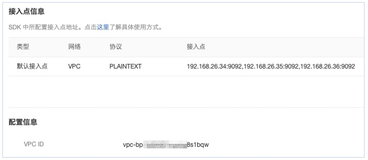
</match>这里我把我的project_name和access id/key信息给隐藏了。endpoint 的地址看这里,我纯测试,就用了公网地址。
配置文件生成好了后,使用bin/fluentd -c fluentd.conf启动fluentd
测试
我们通过date "+%Y-%m-%d %H:%M:%S [Info] login success" >> /tmp/test.log往/tmp/test.log里写日志,然后在fluentd 上,我们可以看到日志为:
来到datahub上可以看到新写进去的日志:
至此大功告成,/tmp/test.log上的新增数据会被实时推送到DataHub里了。