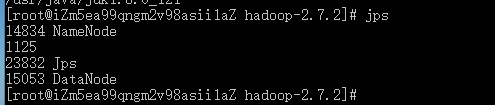
根据John Matherly的说法,不适当地配置HDFS服务器——主要是Hadoop安装——将会泄露超过5PB的信息。John Matherly是用于发现互联网设备的搜索引擎Shodan的创始人。
这位专家说,他发现了4487个HDFS服务器实例,这些服务器可通过公共IP地址获得,而且不需要身份验证。这些服务器总共泄露了超过5120TB的数据。
▲HDFS系统泄露地图
据Matherly说,47820个MongoDB服务器只泄露了25 TB的数据。从这个角度来看,与MongoDB服务器相比,HDFS服务器泄露的数据要多200倍,而与此同时,MongoDB服务器的数量是后者的10倍。Binary Edge于2015年公布的一份报告显示,在当时,Redis、MongoDB、Memcached和ElasticSearch服务器的数据只泄露了1.1 PB的数据。
大多数HDFS系统位于美国和中国
泄露最多HDFS实例的国家是美国和中国,但这并不奇怪,因为这两个国家拥有世界上超过50%的数据中心。
今年早些时候,攻击者意识到他们可以接管为受保护的服务器,在网络上泄露、窃取他们的内容,请要求赎金。黑客攻击首先针对的是MongoDB,但很快就转移到了CouchDB和Hadoop。
最初的时候,有124个服务器遭受勒索,这个数字最近增长到了500个。根据Matherly的说法,仍然有207个基于hdfs的集群有赎金要求,不过我们不清楚这些是不是今年1月袭击的遗留问题,还是现下仍然有服务器正被劫持。
针对这次Hadoop数据泄露事件,阿里云给出的企业级海量数据安全存储解决方案是,通过阿里云数加MaxCompute (原名:ODPS;https://www.aliyun.com/product/odps)存储、加工企业数据;
阿里云数加MaxCompute(原名ODPS)设计之初就是面向多租户,确保租户的数据安全是MaxCompute的必备功能之一。在MaxCompute系统的安全设计和实现上,MaxCompute的工程师们会遵循一些经过实践检验的安全设计原则(如Saltzer-Schroeder原则)。在常用密码算法及安全协议的设计和实现上,也会遵循业界相关标准(如PKCS-及FIPS-系列标准),并坚持最佳安全实践。
这里从如下几个方面来解刨一下MaxCompute的安全特性,让关心MaxCompute数据安全的读者有一个基本的了解。更多产品信息请访问https://www.aliyun.com/product/odps 。
1. API认证
认证是一个服务的安全入口。MaxCompute认证采用业界标准的API认证协议来实现,如HmacSHA1。MaxCompute还提供HTTP和HTTPS两种的EndPoint以满足用户对认证安全的不同要求。HTTP EndPoint是明文传输,那么HmacSHA1认证只能保证消息请求的真实性(Authenticity)和完整性(Integrity),适合于对数据安全不太敏感的用户。HTTPS EndPoint则能提供更多的安全性,比如信道加密,抗重放攻击等。适合于对数据安全比较敏感的用户。
2. 访问控制
当你创建项目空间后,你就是项目空间的owner。一个项目空间只有一个owner,只有owner对项目空间有完全控制权限。你可以上传/下载数据、提交SQL进行数据处理。在没有你的授权的情况下,任何其他用户都无权访问你的项目空间。 注意,MaxCompute平台并没有超级管理员的角色,所以MaxCompute的开发、测试、运维同学都是没有权限看到用户数据的。有人会问了,通过MaxCompute背后的运维管理控制台也不能访问用户数据吗?的确不能。运维同学只有在获得内部授权之后,可以通过该控制台来执行一些运维管理类操作,比如停止一个有恶意行为的用户作业,但该控制台没有操作用户数据的权限。
MaxCompute产品面向的是企业级用户,所以提供了丰富的项目空间内的用户管理及授权功能,有兴趣的同学可以参考MaxCompute用户手册中的相关章节。MaxCompute访问控制粒度非常精细,比如你可以授权一个用户只能读某个table的部分columns,并且可以要求该用户只能在某个时间范围内、而且必须从指定的某些IP地址来进行访问。换句话说,一个企业主可以做到只允许其员工在公司内、在正常上班时间才能访问数据,下班回家就不允许访问了。
3. 数据流控制
MaxCompute设计之初就是要满足数据分享(或数据交换)的场景。所以,只要有授权,用户就可以非常方便的进行跨项目空间的数据访问。比如,在获得相应的访问权限之后,项目空间A中的作业可以直接处理项目空间B中的数据,而不必事先将数据从项目空间B中复制到项目空间A。
数据保护有两层含义,一是防止未授权的数据访问;二是防止获得授权的用户滥用数据。很多商用系统并不提供后一种数据安全保证。但在MaxCompute平台上,用户的这种担忧比较明显:用户希望能确保对自己的数据拥有控制权,而一旦授权他人读取,他人就可能会做复制数据,那么就相当于失去了对数据的控制权。
MaxCompute通过支持数据流控制来防止跨项目空间的数据复制。如果你想确保项目空间中的所有数据都不允许流出去,那么你可以打开项目空间的数据流控设置。你还可以设置项目空间的数据保护策略,以限制哪些数据可以流出到哪些项目空间。
4. 用户作业的隔离运行
MaxCompute支持用户提交各种类型的作业(如SQL/XLib/MR)。为了确保不同用户作业在运行时互不干扰,MaxCompute将用户作业的Worker进程运行在飞天 Container沙箱中。如果用户作业含有Java代码(比如UDF),那么飞天Container沙箱中的Worker进程启动JVM时,还会设置严格的Java 沙箱策略以限制UDF的运行时权限。
5. 作业运行时使用最小权限
最小权限原则是系统安全和容错设计的一个基本指导原则,即让每个任务在运行时使用刚好满足需要(不多也不少)的权限来执行。
MaxCompute的作业运行过程一般是这样:用户提交的SQL/XLib/MR作业会被调度到某一计算集群上运行,运行时每个作业一般对应一组并行跑的Worker进程,Worker进程一般会从数据集群上读数据、处理完成后最终会将数据写回到数据集群。举个例子来理解MaxCompute是如何遵循最小权限原则的。我们假设用户Alice被授权读访问一个项目空间下t1和t2两个table数据,但她提交的某个SQL只需要读t1的数据。在MaxCompute中,这个SQL对应的Worker进程在运行时就只能读t1对应的底层数据文件,而不会有更多的数据访问权限。
MaxCompute最小权限是依赖于底层的飞天分布式操作系统提供的Kerberos认证和Capability访问控制来实现的。Kerberos认证用于解决飞天底层服务模块之间的身份认证,Capability则用于解决底层服务模块之间的访问控制技术。这与上层MaxCompute所提供的认证和访问控制是完全正交的安全机制,对MaxCompute用户是完全透明的。
6. 数据访问审计
MaxCompute还提供精准的、细粒度的数据访问操作记录,并会长期保存。MaxCompute平台体系所依赖的功能服务模块非常之多,我们可以把它称之为底层服务栈。对于数据操作记录来说,MaxCompute会收集服务栈上的所有操作记录,从上层table/column级别的数据访问日志,一直到底层分布式文件系统上的数据操作日志。最底层分布式文件系统上处理的每一次数据访问请求,也都能追溯到是最上层的哪个项目空间中的哪个用户的哪个作业发起的数据访问。
有了服务栈上的各层操作审计之后,即使是内部攻击者(工程师或渗透到内部系统中的黑客)想从内部(绕过MaxCompute服务)直接访问底层分布式文件系统上的用户数据的话,也一定是可以从操作日志中被发现的。所以,通过数据访问审计,用户就可以准确的知道他在MaxCompute上的数据是否存在未授权的数据访问。
7. 风险控制
除了不同层面的防御机制之外,MaxCompute产品还会提供一套安全监控系统,用于监控用户作业及用户数据的安全活动,如AccessKey滥用,项目空间安全配置不当,用户代码运行时触犯安全策略,以及用户数据是否遭受异常访问等。
安全攻击防不胜防,所以MaxCompute会通过安全监控手段来及时发现问题,一旦发现安全问题则会启动相应的处理流程,尽可能将用户损失降到最低。
结语:虽然没有绝对的安全,但安全性在MaxCompute产品设计和实现中享有最高优先级。MaxCompute团队已经汇聚了多领域的安全专家,以保障用户数据安全。同时,我们欢迎更多安全专家的加入,共同增强MaxCompute的数据安全。
购买&试用MaxCompute,请扫二维码加入钉钉群。

相关MaxCompute安全专题: