本节书摘来自异步社区《设计模式沉思录》一书中的第2章,第2.7节多用户文件系统的保护,作者【美】John Vlissides,更多章节内容可以访问云栖社区“异步社区”公众号查看。
2.7 多用户文件系统的保护
我们已经讨论了如何给我们正在设计的文件系统添加简单的单用户保护。前面提到我们会将这个概念扩展到多用户环境,在这个环境中许多用户共享同一个文件系统。无论是配以中枢文件系统的传统分时系统,还是当代的网络文件系统,对多用户的支持都是必不可少的。即使那些为单用户环境所设计的个人计算机操作系统(如OS/2和Windows NT),现在也已经支持多用户。无论是什么情况,多用户支持都给文件系统保护这一问题增加了难度。
我们将再一次采用最简易的设计思路,效仿Unix系统的多用户保护机制。Unix文件系统中的一个节点是与一个“用户”相关联的。在默认的情况下,一个节点的用户就是创建该节点的人。从节点的角度来看,这种关联把所有用户分为两类:该节点的用户,以及其余所有的人。用标准的Unix术语来说,“其余所有的人”就是other⑪。
通过对一个节点的用户和其他人进行区分,我们可以给每种类型分别指定保护级别。例如,如果一个文件对它的用户是可读的,但对其他人是不可读的,那么我们说该文件是“用户可读的”但“其他人不可读的”。对写保护和可能会提供的其他保护模式(如扩展性、自动存档等)来说,它们的工作方式与此相似。
用户必须有一个登录名,无论是对系统还是对其他用户来说,这个登录名都唯一标识了该用户。虽然在现实中一个人可以有多个登录名,但对系统来说,“用户”和“登录名”是不可分割的。重要的是要保证一个人不能将自己与任何不属于他的登录名(假设他有一个登录名)相关联。这就是为什么我们在登录到Unix系统时,不仅需要提供登录名,而且还要提供密码来验证身份的原因。这个过程被称为身份验证。Unix不遗余力地对伪装加以防范,这是因为冒名顶替者能够访问合法用户能够访问的任何东西。
现在可以讨论具体的细节了。我们该如何对用户进行建模?作为面向对象的开发人员,答案很显然:使用对象。每个对象都有一个类,因此我们要定义一个User类。
我们现在需要考虑User类的接口。客户代码能够用User对象做什么?事实上,在目前的阶段更重要的是客户代码不能用User对象做什么。特别是,我们不应该允许客户代码随意创建User对象。
为了理解其中的原因,让我们假设User对象和登录名之间存在一对一的映射。(虽然我们可以允许一个登录名有多个User对象,但目前这样的需求尚不明确。)进一步假设一个User对象必须有一个合法的登录名与之相关联。这个假设是合理的,因为从系统的角度而言,没有登录名的用户是没有意义的。最后,如果客户没有同时提供登录名和密码,那么我们不能让他们创建User对象。否则,一个流氓程序只需要用相应的登录名创建User对象,就可以访问机密的文件和目录了。
一个User对象的存在代表了一次身份验证。于是很明显,我们必须对创建User对象实例的过程严加控制。如果应用程序提供了错误的登录名或密码,那么创建User对象实例的尝试应该失败,而且同时不会产生不完整的User对象,也就是那些由于在创建的时候缺乏必需的信息而导致无法正常使用的User对象。这几乎排除了我们用传统的C++构造函数来创建User实例的可能性。
我们需要一种安全的方法来创建User对象,在客户代码使用的接口中,这种方法不应该涉及构造函数。这里安全的意思是,客户代码应该无法通过任何不正当的方式来创建User对象的实例。那么我们如何用面向对象的术语来表述这样的安全性呢?
让我们考虑一下面向对象概念的三个基本要素:继承、封装和多态。其中与安全性最相关的非封装莫属。事实上,封装是安全性的一种形式。根据定义,客户代码是肯定无法访问封装后的代码和数据的⑫。那么在我们的例子中我们想要封装什么?至少应该包括整个身份验证的过程,这个过程以用户的输入为开始,以User对象的创建为终止。
我们已经找到了问题。现在我们需要寻找一个解决方案,并用对象来把这个解决方案表达出来。也许现在是看一些模式的时候了。
此时此刻,我承认在模式的选择上,我们还没有什么指导方法。但我们知道对象的创建和封装都是非常重要的部分。为了缩小搜索的范围,《设计模式》根据每个模式的目的将它们分为三组:创建型、结构型以及行为型。其中创建型模式看起来和我们的问题联系最紧密:ABSTRACT FACTORY、BUILDER、FACTORY METHOD、PROTOTYPE以及SINGLETON。因为一共只有5个模式,所以我们可以先快速浏览每个模式,看是否能从中找到一个合适的模式。
ABSTRACT FACTORY关注的是创建一系列的对象而无需指定具体的类。这很好,但我们的设计问题并没有涉及一系列对象,而且我们也不反对创建具体的类(即User类)的实例。因此我们就排除了ABSTRACT FACTORY。下一个是BUILDER,它关心的是创建复杂的对象。它让我们使用相同的一些步骤来构造对象,而这些对象具有不同的表现形式,这和我们的问题没有太大的关系。除了没有强调对系列的支持,FACTORY METHOD的意图与ABSTRACT FACTORY相似,因此它和我们的问题也没有很紧密的联系。
PROTOTYPE怎么样?它把待创建对象实例的类型放到参数中。这样我们就可以用一个实例(这个实例在运行的时候是可以替换的)作为原型,并调用它的copy操作来创建新的实例,而无需编写代码用new操作符和类名(在运行的时候是无法改变的)来创建新的实例。如果要改变被实例化的对象的类,只需用一个不同的实例作为原型即可。
但这也不对。我们的兴趣并不在于改变要创建什么对象,而在于对客户代码如何创建User对象加以控制。由于任何人都可以对原型进行复制,因此和原始的构造函数相比,我们并没有获得更多的控制权。此外,在系统中保持一个User对象作为原型会对我们的身份验证模型产生危害。
剩下的只有SINGLETON了。它的意图是确保每个类只有一个实例,并提供一个全局访问点来访问该实例。该模式规定了一个名为Instance的静态成员函数,该函数不带任何参数,它会返回这个类的唯一实例。为了防止客户代码直接使用构造函数,所有的构造函数都是受保护的。
乍一看这似乎也不怎么适用——一个程序可能需要一个以上的User对象,不是吗?但即便我们不想把实例的数量限制为只有一个,我们确实想禁止每个用户有一个以上的实例。无论是哪种情况,我们都要对实例的数量加以限制。
因此,SINGLETON可能还是适用的。再仔细看一下SINGLETON的效果部分,我们发现了下面的描述:
[SINGLETON] 允许实例的数量是可变的。该模式让我们能够非常容易地改变想法来允许SINGLETON类有一个以上的实例。此外,我们还可以用相同的方法来对应用程序使用的实例数量加以控制。只有那个有权访问SINGLETON实例的[Instance]操作才需要修改。
就是它了!我们的情况正是SINGLETON模式的一个变体,我们可以将Instance操作重新命名为logIn并给它指定一些参数。
static const User* User::logIn(
const string& loginName, const string& password
);
logIn确保只为每一个登录名创建一个实例。为了达到这个目的,User类可能会维持一个私有的静态散列表,该散列表以登录名为索引,用来保存User对象。logIn在这个散列表中查找loginName参数。如果找到了对应的User项,那么就返回该项,否则logIn就执行下面的操作。
(1)创建一个新的User对象,通过密码来进行身份验证。
(2)在散列表中登记该User对象,以便今后访问。
(3)返回该User对象。
下面对User::logIn操作的属性进行了总结。
可以在应用程序的任何地方访问它。
它防止用户为每个登录名创建一个以上的实例。
与构造函数不同的是,如果登录名或密码不正确,那么它会返回0。
应用程序不能通过从User派生子类的方式来修改logIn。
必须承认的是,这是对SINGLETON模式的一种非正规应用。客户代码能够创建一个以上的User实例,这意味着我们并未严格遵循该模式的意图。但是,我们确实要对实例的数量进行控制,而该模式对此也提供了支持。我们都明白,模式并不代表唯一的解决方案。一个好的模式不仅仅只是对一个问题的解决方案的描述,它还给我们以洞察力和理解力,从而能够对解决方案进行修改,使之符合我们自己的情况。
即便如此,SINGLETON并没有告诉我们一切。例如,由于我们已经提供了logIn操作,因此如果客户代码期望我们提供一个对应的logOut操作来让用户登出系统,那将是个合理的要求。logOut将会引出一些重要的问题,这些问题与Singleton对象的内存管理有关。然而奇怪的是,SINGLETON模式对这些问题却只字未提。我们将在第3章就这些问题展开讨论。
※ ※ ※
下一个问题:客户代码如何使用User对象?为了找到答案,让我们先来看一些用例。
首先,考虑登录的过程。假设当用户想要访问系统(或者至少是系统中受保护的部分)时,系统会执行一个登录程序。登录程序会调用User::logIn来得到一个User对象。然后登录程序通过某种方式让其他应用程序能够访问该User对象,这样该用户就不必再次登录了。
其次,让我们考虑一个应用程序如何访问一个几天前创建的文件,该文件的创建者的登录名为“johnny”。假设这个应用程序的用户登录名为“mom”,并且该文件是用户可读的但其他人不可读的。因此,系统不应该允许“mom”访问该文件。在单用户系统中,应用程序通过调用streamOut操作并在参数中传入一个流,来要求得到文件的内容。
void streamOut(ostream&);
我们希望这个调用在多用户的情况下最好保持不变,但它没有在参数中引用正在访问该文件的用户。缺少了这个引用,系统将无法确保用户具有访问文件的权限。我们要么将这个引用在参数中显式地传入。
void streamout(ostream&, const User*);
要么通过登录过程隐式地得到这个引用。大部分的情况下,应用程序会在整个生命周期中代表唯一一个用户。在这种情况下,需要不停地在参数中提供User对象是很烦人的。但是,一个协作式的应用程序可供多个用户使用,这很容易想象而且很合理。在这种情况下,给每个操作指定User对象是必需的。
因此,我们需要给Node接口中的每个操作增加一个const User*参数——但同时不应该强迫客户代码必须提供该参数。默认参数所提供的灵活性让我们能够得体地处理这两种情况。
const string& getName(const User*= 0);
const Protection& getProtection(const User*= 0);
void setName(const string&, const User*= 0);
void setProtection(const Protection&, const User*= 0);
void streamIn(istream&, const User*= 0);
void streamOut(ostream&, const User*= 0);
Node* getChild(int, const User*= 0);
void adopt(Node*, const User*= 0);
void orphan(Node*, const User*= 0);
通常情况下,用户是隐式的,我们需要一个全局可访问的操作来得到这个唯一的User实例。这就是SINGLETON,但为了灵活性,我们还应该允许应用程序设置SINGLETON实例。因此,我们不使用唯一的User::Instance静态操作,而是使用下面的get和set静态操作。
static const User*User::getUser();
static void User::setUser(const User*);
setUser让应用程序将隐式的用户设置为任何const User,当然这个const User应该是通过正当手段得到的。现在登录程序就可以调用setUser来设置全局User实例了,因为其他应用程序也应该使用该实例⑬。
extern const int maxTries;
// ...
const User* user = 0;
for (int i=0; i< maxTries; ++i) {
if (user = User::logIn(loginName, password)) {
break;
} else {
cerr << "Log-in invalid!" << endl;
}
}
if (user) {
User::setUser(user);
} else {
// too many unsuccessful log-in attempts;
// lock this login name out!
// ...
}
到目前为止,一切都很容易理解。但我一直在回避一个简单的问题:所有这些是如何对streamOut和Node接口中的其他模板方法的实现产生影响的?或者更加直接一点,它们如何使用User对象?
与单用户的设计相比,关键的区别并不在于模板方法本身,而在于返回类型为布尔值的基本操作。例如,streamOut变成了如下所示。
void Node::streamOut (ostream& out, const User*u) {
User* user = u ? u : User::getUser();
if (isReadableBy(user)) {
doStreamOut(out);
} else {
doWarning(unreadableWarning);
}
}
在第二行我们可以看到一个明显的区别。如果参数中指定了用户,那么局部变量user会被初始化为指定的用户,如果参数中没有指定用户,那么user会被初始化为默认的User对象。但更为显著的区别是在第三行,其中isReadableBy取代了isReadable。isReadableBy根据存储在节点中的信息,检查该节点是用户可读还是其他人可读。
bool Node::isReadableBy (const User*user) {
bool isOwner = user->owns(this);
return
isOwner && isUserReadable() ||
!isOwner && isOtherReadable();
}
isReadableBy揭示了对User::owns的需求——这个操作检查User对象中的登录名以及与节点相关联的登录名。如果两者的值相同,那么该用户拥有节点。owns操作需要一个接口来从节点获取登录名。
const string& Node::getLoginName();
节点也需要isUserReadable和isOtherReadable之类的基本操作,这些操作就用户和其他人是否能够读写节点提供了更详细的信息。Node基类可以在实例变量中保存一些标志,并将这些操作简单地实现为对这些标志的访问,或者也可以将此类与存储有关的细节交给子类去处理。
※ ※ ※
我们已经讨论了足够多的细节,现在让我们重新回到设计层面。
读者应该还记得我们把世界一分为二——用户和其他人。但那样可能有些过于极端了。举个例子,如果我们正在和一些同事开发一个项目,那么我们很可能想要访问彼此的文件。我们可能还要对文件进行保护,使开发组之外的人员无法窥探它们。这正是UNIX提供了第三种类型(即group)的原因之一。一个group是经过命名的一组登录名。使节点成为组可读(group-readable)或组可写(group-writable)使我们能够对访问权限进行精细的控制,对需要相互协作的工作环境来说,这样的控制能够很好地满足要求。
要在设计中加入组的概念,我们需要了解哪些信息?我们知道两条信息。
(1)一个组有零个或多个用户。
(2)一个用户可以是零个或多个组的成员。
第二条意味着应该使用引用,而不应该使用聚合,因为删除一个组并不会删除其中包含的用户。
根据我们对组的理解,用对象来表示它们再合适不过了。问题是,我们是要定义一个新的类层次,还是只对已有的类层次进行扩展呢?
我肯定User类是唯一适合扩展的候选类。另一种选择是将Group类定义为一种类型的Node,这种选择既没有意义也没有用处。因此让我们来考虑一下Group和User之间的继承关系会给我们带来什么。
我们已经熟悉了COMPOSITE模式。它描述了叶节点(如File)和复合节点(如Directory)之间的递归关系。它给所有的节点以完全相同的接口,这样我们不仅能以统一的方式来处理它们,而且能以层级的形式来组织它们。也许我们想要的是用户和组之间的复合关系:User是Leaf类,而Group是Composite类。
让我们再回顾一下COMPOSITE模式的适用性部分,其中提到该模式适用于下面的情况。
我们想要表示一个部分—整体的对象层次结构。
我们想让客户代码忽略复合对象和个体对象之间的区别。客户代码将以统一的方式来处理复合结构中的所有对象。
根据这些标准,我们可以确信COMPOSITE模式并不适用。下面三条就是原因。
类之间的关系并不是递归的。由于Unix文件系统不允许一个组里包含其他的组,因此我们不需要这样的支持。仅仅因为该模式指定了递归关系并不代表我们的应用程序就一定需要用到这种关系。
一个用户可能隶属多个组。因此类之间的关系并不是严格意义上的层次结构。
以统一的方式来处理用户和组是有问题的。用一个组来登录是什么意思?用一个组来进行身份验证又是什么意思?
这三条原因反驳了User和Group之间的复合关系。但由于系统必须记录哪些用户隶属哪些组,因此我们仍然需要在用户和组之间建立某种关联。
事实上,为了得到最佳的性能,我们需要双向映射。系统中用户的数量很可能要比组的数量多得多,因此系统必须能够在不检查每个用户的前提下,确定一个组中的所有用户。查找一个用户隶属的所有的组也同样重要,因为这可以让系统更快地检查用户是否是某个组的成员。
实现双向映射的一个显而易见的方法是给Group和User类增加集合:在Group类中加入一个节点集合,在User类中加入一个组集合。但这种方法有两个严重的缺点。
(1)映射关系难以修改。我们至少必须修改一个基类,甚至可能要修改两个基类。
(2)所有对象都必须承担集合的开销。不包含任何用户的组需要承担集合的开销,不属于任何组的用户也需要承担集合的开销。即使在开销最小的情况下,每个对象仍然需要额外存储一个指针。
组和用户之间的映射不仅复杂,而且可能会发生变化。上面这个显而易见的方法将管理和维护映射的职责分散了,从而导致了刚才提到的缺点。有一个不太显而易见的方法可以避免这些缺点,那就是将职责集中起来。
MEDIATOR模式将对象间的交互升格为完整的对象状态。通过不让对象显式地相互引用,它促进了松耦合,从而让我们能够单独地改变对象之间的交互,同时无需改变对象本身。
图2-5是在应用该模式之前的典型情况。有许多相互交互的对象(该模式将它们统称为colleague),每一个colleague都直接引用了(几乎所有的)其他colleague。
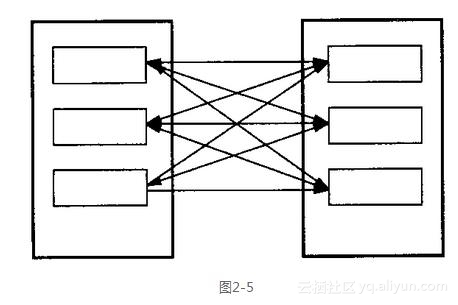
图2-6所示是应用该模式后的结果。
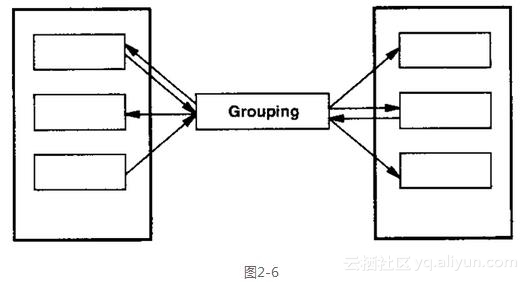
该模式的核心是一个Mediator对象,它对应于第二张图中的Grouping对象。各colleague之间没有显式地相互引用,而是引用了mediator。
在我们的文件系统中,Grouping对象定义了用户和组之间的双向映射。为了使映射易于修改,该模式为所有的Mediator对象定义了一个抽象基类,我们可以从这个基类派生与映射有关的子类。下面是Grouping(mediator)提供的一个简单接口,该接口让客户代码实现用户与组之间的注册和注销操作。
class Grouping {
public:
virtual void ~Grouping();
static const Grouping*getGrouping();
static void setGrouping(const Grouping*, const User*= 0);
virtual void register(
const User*, const Group*, const User*= 0
) = 0;
virtual void unregister(
const User*, const Group*, const User*= 0
) = 0;
virtual const Group*getGroup(
const string& loginName, int index = 0
) = 0;
virtual const string& getUser(
const Group*, int index = 0
) = 0;
protected:
Grouping();
Grouping(const Grouping&);
};
这个接口中第一个要注意的地方是静态的get和set操作,这两个操作类似于我们将SINGLETON模式应用于User类时定义的静态操作。我们在此应用SINGLETON模式也是出于相同的原因:映射需要是全局可访问和可设置的。
通过在运行的时候替换Grouping对象,我们能够一下子改变映射。例如,也许出于监管的目的,一个超级用户能够对映射进行重定义。我们必须对修改映射的操作进行严密保护,这也是为什么客户代码在调用setGrouping时必须传入一个经过身份验证的const User*的原因。与此类似,在建立或解除映射关系时,传给register和unregister操作的用户参数也必须经过身份验证。
最后两个操作getGroup和getUser用来得到相应的组和用户。可选的索引参数为客户代码提供了一种便捷的方式来遍历多个值。具体子类可以给这些操作定义不同的实现。注意,这些操作并没有直接用到User对象,而是用一个字符串来表示相应的登录名。这使得任何客户代码即使无权访问某个User对象,仍然可以知道该用户与哪些组相关联。
※ ※ ※
MEDIATOR模式的隐患之一是它有产生巨型Mediator类的趋向。由于Mediator类封装的交互可能非常复杂,因此它可能会成为一个难以维护和扩展的巨型类。运用其他一些模式有助于预防这样的可能性。例如,我们可以使用TEMPLATE METHOD来允许子类对mediator的部分行为进行修改。STRATEGY不仅能让我们完成同样的任务,而且还提供了更好的灵活性。COMPOSITE让我们能够以递归的形式把一些较小的部分组合成一个mediator类。
