
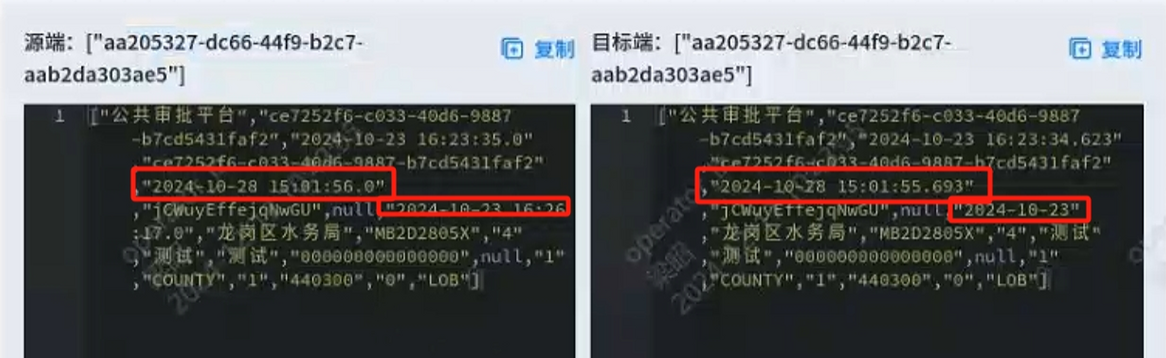
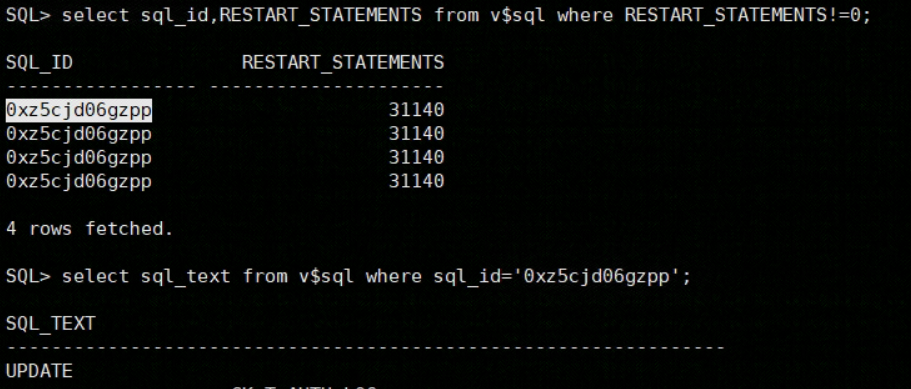
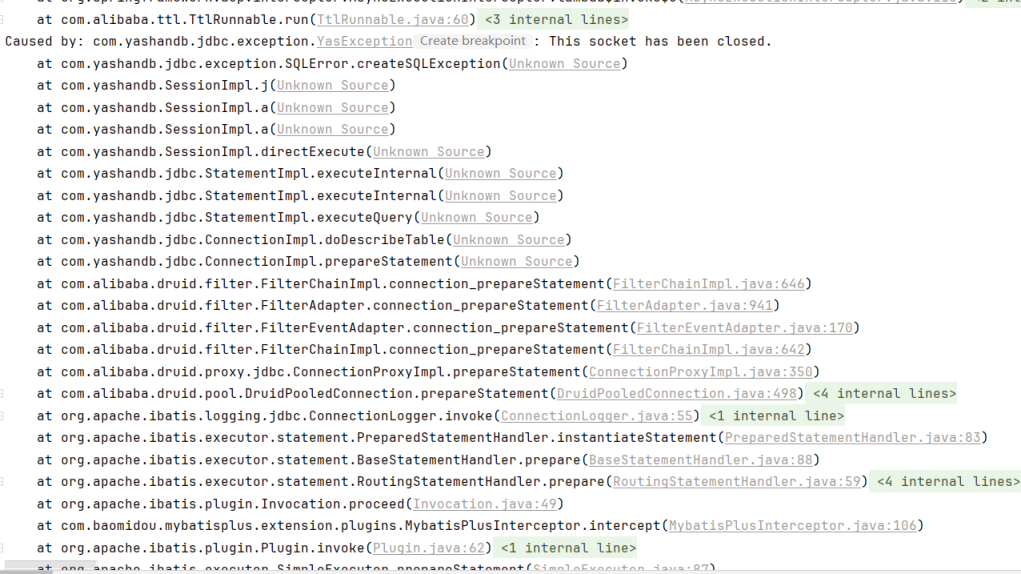
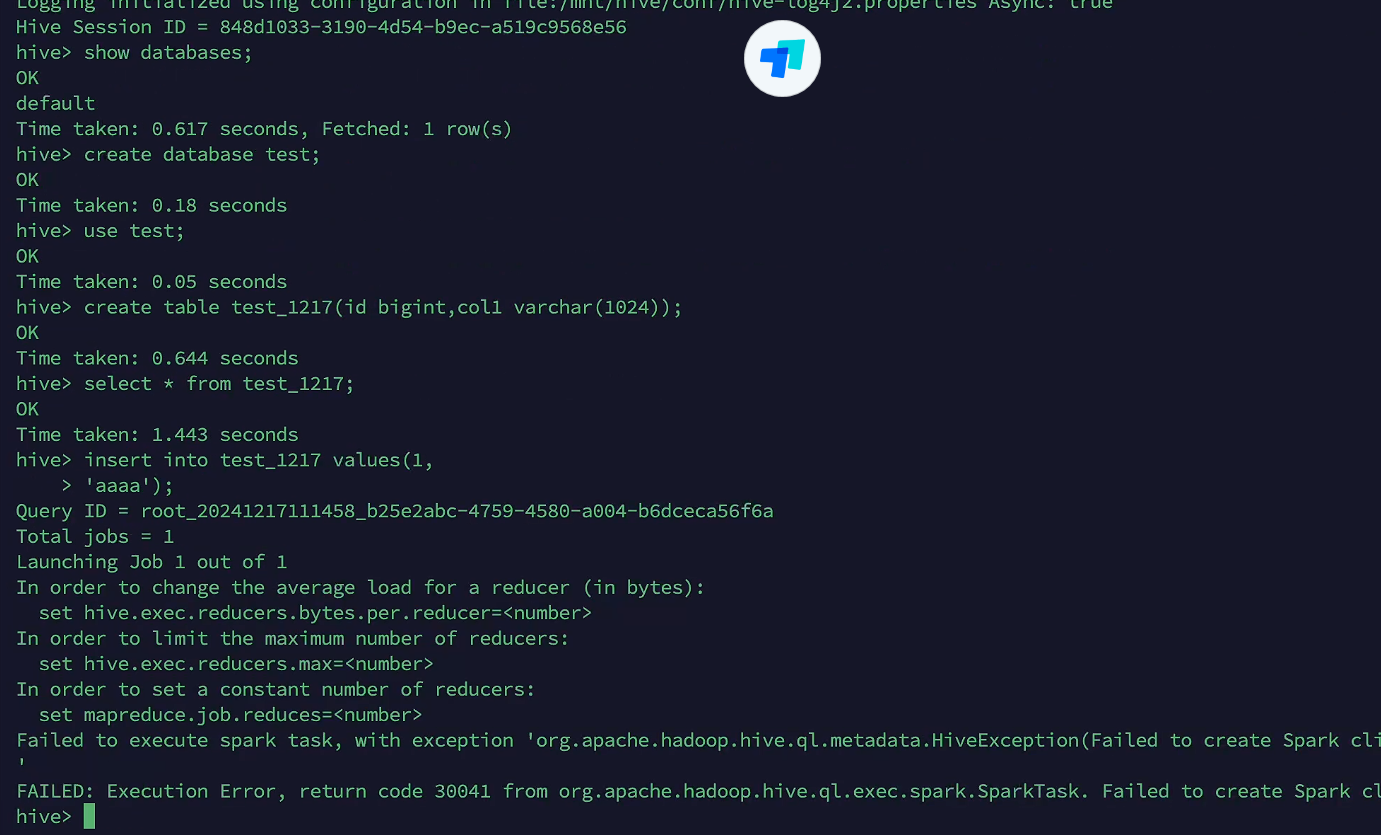
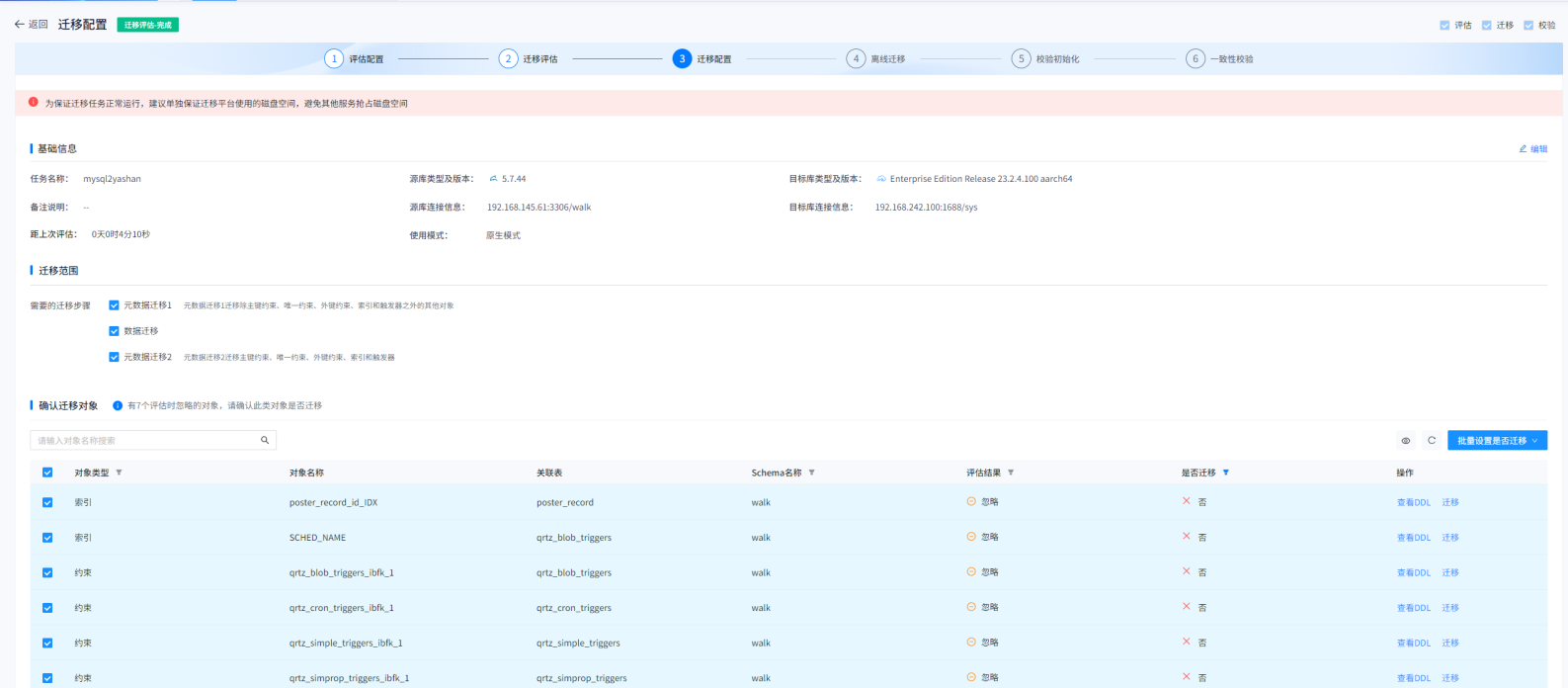
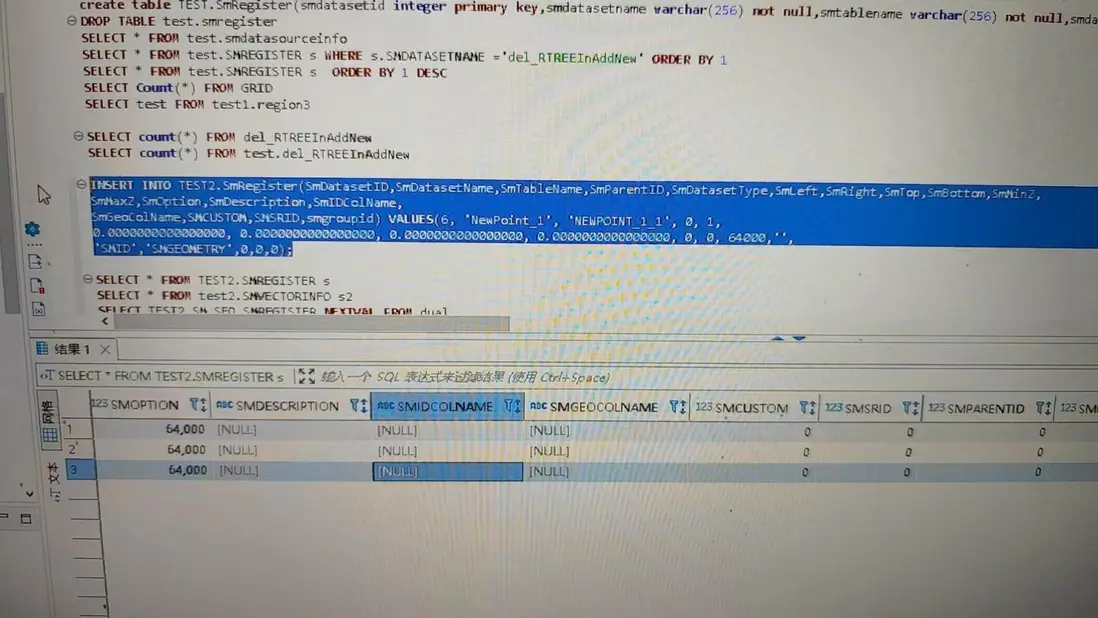
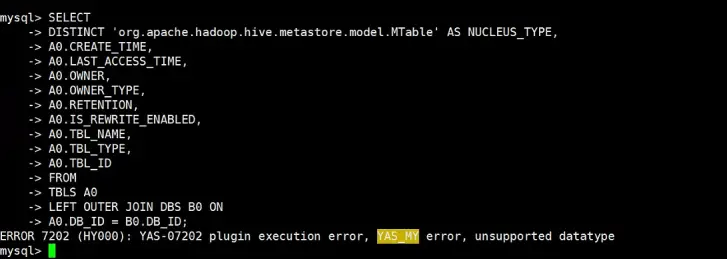
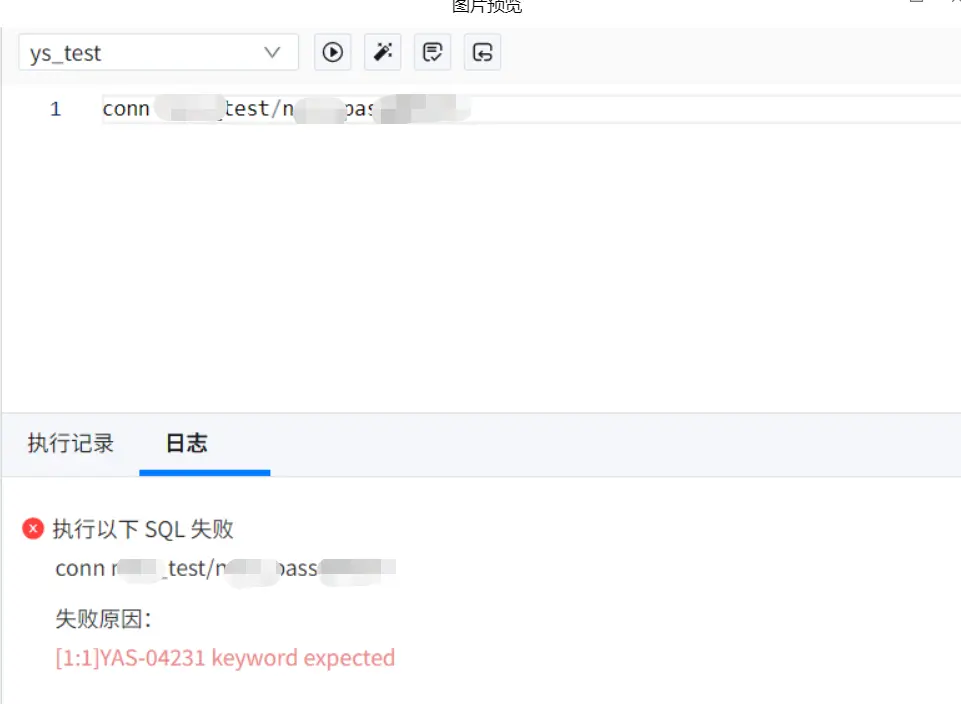
【YashanDB 知识库】YAS-04115 "SELECT" expected but missing



















你好,我是AI助理
可以解答问题、推荐解决方案等
