本节书摘来自异步社区《用Python写网络爬虫》一书中的第1章,第1.3节,作者 [澳]Richard Lawson(理查德 劳森),李斌 译,更多章节内容可以访问云栖社区“异步社区”公众号查看。
1.3 背景调研
在深入讨论爬取一个网站之前,我们首先需要对目标站点的规模和结构进行一定程度的了解。网站自身的robots.txt和Sitemap文件都可以为我们提供一定的帮助,此外还有一些能提供更详细信息的外部工具,比如Google搜索和WHOIS。
1.3.1 检查robots.txt
大多数网站都会定义robots.txt文件,这样可以让爬虫了解爬取该网站时存在哪些限制。这些限制虽然仅仅作为建议给出,但是良好的网络公民都应当遵守这些限制。在爬取之前,检查robots.txt文件这一宝贵资源可以最小化爬虫被封禁的可能,而且还能发现和网站结构相关的线索。关于robots.txt协议的更多信息可以参见http://www.robotstxt.org 。下面的代码是我们的示例文件robots.txt中的内容,可以访问http://example.webscraping.com/robots.txt 获取。
# section 1
User-agent: BadCrawler
Disallow: /
# section 2
User-agent: *
Crawl-delay: 5
Disallow: /trap
# section 3
Sitemap: http://example.webscraping.com/sitemap.xml在section 1中,robots.txt文件禁止用户代理为BadCrawler的爬虫爬取该网站,不过这种写法可能无法起到应有的作用,因为恶意爬虫根本不会遵从robots.txt的要求。本章后面的一个例子将会展示如何让爬虫自动遵守robots.txt的要求。
section 2规定,无论使用哪种用户代理,都应该在两次下载请求之间给出5秒的抓取延迟,我们需要遵从该建议以避免服务器过载。这里还有一个/trap链接,用于封禁那些爬取了不允许链接的恶意爬虫。如果你访问了这个链接,服务器就会封禁你的IP一分钟!一个真实的网站可能会对你的IP封禁更长时间,甚至是永久封禁。不过如果这样设置的话,我们就无法继续这个例子了。
section 3定义了一个Sitemap文件,我们将在下一节中了解如何检查该文件。
1.3.2 检查网站地图
网站提供的Sitemap文件(即网站地图)可以帮助爬虫定位网站最新的内容,而无须爬取每一个网页。如果想要了解更多信息,可以从http://www.sitemaps.org/protocol.html 获取网站地图标准的定义。下面是在robots.txt文件中发现的Sitemap文件的内容。
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<url><loc>http://example.webscraping.com/view/Afghanistan-1
</loc></url>
<url><loc>http://example.webscraping.com/view/Aland-Islands-2
</loc></url>
<url><loc>http://example.webscraping.com/view/Albania-3</loc>
</url>
...
</urlset>网站地图提供了所有网页的链接,我们会在后面的小节中使用这些信息,用于创建我们的第一个爬虫。虽然Sitemap文件提供了一种爬取网站的有效方式,但是我们仍需对其谨慎处理,因为该文件经常存在缺失、过期或不完整的问题。
1.3.3 估算网站大小
目标网站的大小会影响我们如何进行爬取。如果是像我们的示例站点这样只有几百个URL的网站,效率并没有那么重要;但如果是拥有数百万个网页的站点,使用串行下载可能需要持续数月才能完成,这时就需要使用第4章中介绍的分布式下载来解决了。
估算网站大小的一个简便方法是检查Google爬虫的结果,因为Google很可能已经爬取过我们感兴趣的网站。我们可以通过Google搜索的site关键词过滤域名结果,从而获取该信息。我们可以从http://www.google.com/advanced_search 了解到该接口及其他高级搜索参数的用法。
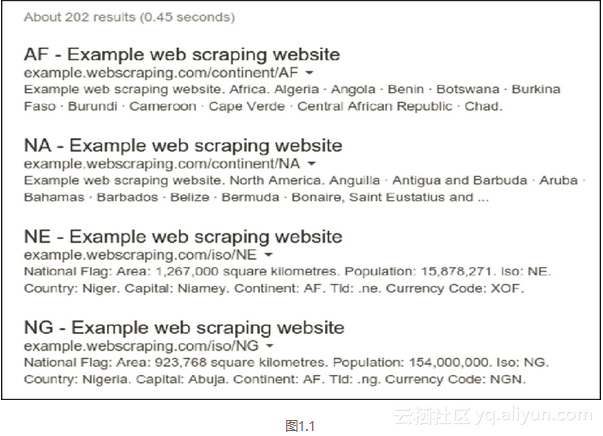
图1.1所示为使用site关键词对我们的示例网站进行搜索的结果,即在Google中搜索site:example.webscraping.com。
从图1.1中可以看出,此时Google估算该网站拥有202个网页,这和实际情况差不多。不过对于更大型的网站,我们会发现Google的估算并不十分准确。
在域名后面添加URL路径,可以对结果进行过滤,仅显示网站的某些部分。图1.2所示为搜索site:example.webscraping.com/view的结果。该搜索条件会限制Google只搜索国家页面。
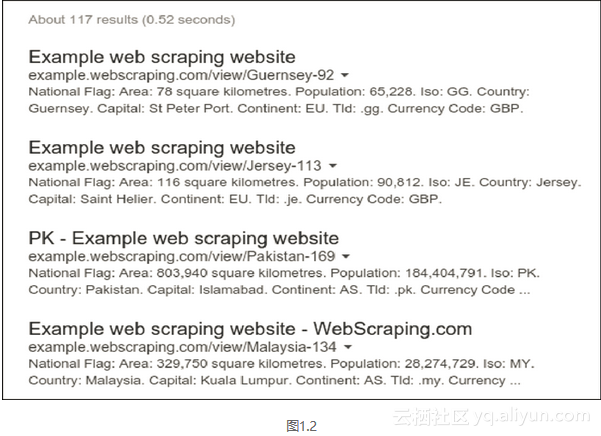
这种附加的过滤条件非常有用,因为在理想情况下,你只希望爬取网站中包含有用数据的部分,而不是爬取网站的每个页面。
1.3.4 识别网站所用技术
构建网站所使用的技术类型也会对我们如何爬取产生影响。有一个十分有用的工具可以检查网站构建的技术类型——builtwith模块。该模块的安装方法如下。
pip install builtwith
该模块将URL作为参数,下载该URL并对其进行分析,然后返回该网站使用的技术。下面是使用该模块的一个例子。
>>> import builtwith
>>> builtwith.parse('http://example.webscraping.com')
{u'javascript-frameworks': [u'jQuery', u'Modernizr', u'jQuery UI'],
u'programming-languages': [u'Python'],
u'web-frameworks': [u'Web2py', u'Twitter Bootstrap'],
u'web-servers': [u'Nginx']}从上面的返回结果中可以看出,示例网站使用了Python的Web2py框架,另外还使用了一些通用的JavaScript库,因此该网站的内容很有可能是嵌入在HTML中的,相对而言比较容易抓取。而如果改用AngularJS构建该网站,此时的网站内容就很可能是动态加载的。另外,如果网站使用了ASP.NET,那么在爬取网页时,就必须要用到会话管理和表单提交了。对于这些更加复杂的情况,我们会在第5章和第6章中进行介绍。
1.3.5 寻找网站所有者
对于一些网站,我们可能会关心其所有者是谁。比如,我们已知网站的所有者会封禁网络爬虫,那么我们最好把下载速度控制得更加保守一些。为了找到网站的所有者,我们可以使用WHOIS协议查询域名的注册者是谁。Python中有一个针对该协议的封装库,其文档地址为https://pypi.python.org/pypi/python-whois ,我们可以通过pip进行安装。
pip install python-whois
下面是使用该模块对appspot.com这个域名进行WHOIS查询时的返回结果。
>>> import whois
>>> print whois.whois('appspot.com')
{
...
"name_servers": [
"NS1.GOOGLE.COM",
"NS2.GOOGLE.COM",
"NS3.GOOGLE.COM",
"NS4.GOOGLE.COM",
"ns4.google.com",
"ns2.google.com",
"ns1.google.com",
"ns3.google.com"
],
"org": "Google Inc.",
"emails": [
"abusecomplaints@markmonitor.com",
"dns-admin@google.com"
]
}从结果中可以看出该域名归属于Google,实际上也确实如此。该域名是用于Google App Engine服务的。当我们爬取该域名时就需要十分小心,因为Google经常会阻断网络爬虫,尽管实际上其自身就是一个网络爬虫业务。





