本节书摘来自异步社区《Python参考手册(第4版•修订版)》一书中的第2章,第2.4节,作者David M. Beazley,更多章节内容可以访问云栖社区“异步社区”公众号查看。
2.4 字符串字面量
字符串字面量用于指定一个字符序列,其定义方法是把文本放入单引号(')、双引号(")或三引号('''或""")中。这三种引号形式在语义上没有差别,但要求在字符串开始和结尾使用的引号类型必须相同。置于单引号和双引号中的字符串必须定义在一行上,而三引号的字符串可以分布在多行上,并且会将所有格式符号(即换行符、制表符、空格等)包含在内。像"hello" 'world'这样的相邻字符串(由空格、换行符或续行符隔开)将被连接起来,形成一个字符串"helloworld"。
在字符串字面量中,反斜杠()字符用于转义特殊字符,如换行符、反斜杠本身、引号和非打印字符。表2-1列出了可识别的一些转义码。无法识别的转义符序列将保持原样,包括最前面的反斜杠在内。

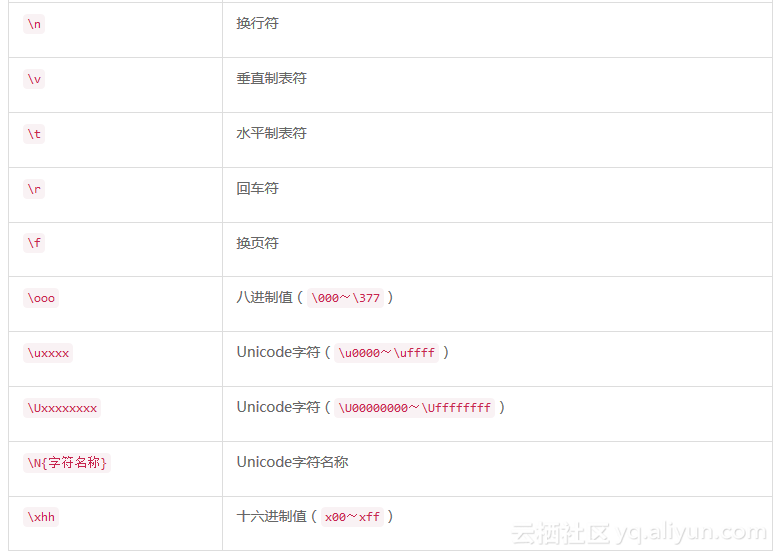
转义码OOO和x用于将字符嵌入到很难输入的字符串字面量(如控制码、非打印字符、符号、国际字符等)中。对于这些转义码,你必须指定对应于字符值的整数值。例如,若要输入单词Jalapeño的字符串字面量,可以输入"Jalapexf1o",其中的xf1就是ñ的字符代码。
在Python 2中,字符串字面量对应于8位字符或面向字节的数据。这种字符串有一个很严重的缺陷,即它们无法完全支持国际字符集和Unicode。为了解决这个问题,Python 2对Unicode数据使用了单独的字符串类型。要输入Unicode字符串字面量,应在第一个引号前加上前缀"u",例如:
s = u"Jalape\u00f1o"
在Python 3中不必加这个前缀字符(而且如果加上会算作语法错误),因为所有字符串已经使用了Unicode编码。如果使用-U选项运行解释器,Python 2将会模拟这种行为。(即所有字符串字面量将被作为Unicode字符对待,u前缀可以省略。)
无论你使用哪个Python版本,表2-1中的u、U和N转义码都可用于在Unicode字面量中插入任意字符。每个Unicode字符都有一个指定的码点(code point),在Unicode字符集中一般表示为U+XXXX,其中XXXX是由4个或更多个十六进制数字表示的序列。(注意,这种表示法并非Python语法,但作者们在描述Unicode字符时经常使用它。)例如,字符ñ的码点是U+00F1。u转义码用于插入码点范围在U+0000和U+FFFF之间的Unicode字符(如u00f1)。U转义码用于插入码点范围在U+10000及以上的字符(如U00012345)。使用U转义码时请注意,码点在U+10000以上的Unicode字符通常被分解为一对字符,称为代理编码对(surrogate pair)。这与Unicode字符串的内部表示有关,第3章将会对此进行更详细的介绍。
Unicode字符还有一个描述性名称。如果知道名称,就可以使用N{字符名称}转义序列,例如:
s = u"Jalape\N{LATIN SMALL LETTER N WITH TILDE}o"
关于码点和字符名称的权威性参考,请参阅http://www.unicode.org/charts。
另外,可以在字符串字面量前面加上r或R,如r'd'。这些字符串称为原始字符串,因为其中所有的转义字符都会原封不动地保留,也就是说,这种字符串包含的文本只表示其字面上的含义,包括反斜杠在内。原始字符串的主要用途是指定其中反斜杠字符是有实际含义的字面量。例如,指定配合re模块一起使用的正则表达式,或者Windows计算机上的一个文件名(如r'c:newdata tests')。
原始字符串不能以单个反斜杠结尾,如r""。在原始字符串中,如果前面字符的数量是奇数个,uXXXX转义序列仍然会解释为Unicode字符。例如,ur"u1234"定义的是包含单个字符U+1234的原始Unicode字符串,而ur"\u1234"定义的则是包含7个字符的字符串,其中前两个字符是反斜杠,余下5个字符是字面量"u1234"。此外,如上所示,在Python 2.2中,r必须出现在原始Unicode字符串中的u之后。在Python 3.0中,u前缀是可选的。
不能使用对应于UTF-8或UTF-16等数据编码的原始字节序列来定义字符串字面量。例如,直接输入像'Jalapexc3xblo'这样的原始UTF-8编码字符串,将会产生一个9个字符的字符串U+004A、U+0061、U+006C、U+0061、U+0070、U+0065、U+00C3、U+00B1、U+006F,这可能不是你想要的结果。因为在UTF-8中,多字节序列xc3xb1代表一个字符U+00F1,而不是两个字符U+00C3和U+00B1。要将一个已编码的字节字符串指定为字面量,在第一个引号前加上"b",即b"Jalapexc3xblo"。这样才能从字面上创建一个单字节的字符串。我们可以使用decode()方法解码字节字面量的值,将这种表示法的字节字面量转换为一个普通的字符串。关于这方面的更多细节,将在第3章和第4章中介绍。
字节字面量在大多数程序中都极少使用,因为这种语法直到Python 2.6才出现,而且在该版本中,字节字面量和普通字符串之间没有差别。但在Python 3中,字节字面量变成了与普通字符串不同的新的bytes数据类型(参见附录A)。
