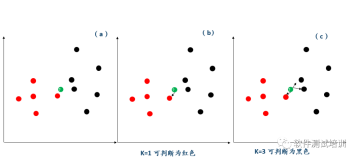
If x1,x2∈Rn, then:
闵可夫斯基距离 Minkowski Distance
欧氏距离 Enclidean Distance
L2 norm
标准化欧式距离/加权欧式距离 Weighted Euclidean Distance
where Sk is the standard deviation.
from numpy import *
vectormat=mat([[1,2,3],[4,5,6]])
v12=vectormat[0]-vectormat[1]
varmat=std(vectormat.T, axis=0)
normmat=(vectormat-mean(vectormat))/varmat.T
normv12=normmat[0]-normmat[1]
print(sqrt(normv12*normv12.T))曼哈顿距离 Manhattan Distance
L1 norm
切比雪夫距离 Chebyshev Distance
L∞ norm
from numpy import *
vector1=mat([1,2,3])
vector2=mat([4,5,7])
print(abs(vector1-vector2).max())夹角余弦 Cosine
汉明距离 Hamming Distance
In information theory, the Hamming distance between two strings of equal length is the number of positions at which the corresponding symbols are different. In other words, it measures the minimum number of substitutions required to change one string into the other. (referred from Wikipedia)
from numpy import *
matV=mat([[1,1,0,1,0,1,0,0,1],[0,1,1,0,0,0,1,1,1]])
smstr=nonzero(matV [0]-matV[1])
print(shape(smstr[0])[0])杰卡德相似系数 Jaccard Similarity Coefficient
Given two sets, A and B, the Jaccard similarity coefficient is defined as
杰卡德距离 Jaccard Distance
from numpy import *
import scipy.spatial.distance as dist
matV=mat([[1,1,0,1,0,1,0,0,1],[0,1,1,0,0,0,1,1,1]])
print(dist.pdist(matV,'jaccard'))马氏距离 Mahalanobis Distance
Given m sample vectors X1,…,Xm whose mean value is μ and covariance matrix is S, then the Mahalanobis distance of sample vector X and μ is defined as
that of sample vector Xi and Xj is