本节书摘来自异步社区《Haskell并行与并发编程》一书中的第2章,第2.3节示例:并行化数独解算器,作者【英】Simon Marlow,更多章节内容可以访问云栖社区“异步社区”公众号查看
2.3 示例:并行化数独解算器
Haskell并行与并发编程
本节将分析一个实例,考察如何并行化一个程序,使之对多组输入数据执行相同的计算。该计算实现了数独求解的功能。解算器(solver)速度相当快,能在2分钟内求解所有给定了17个已知数的共49 000个谜题。
仅作为需要的对多组输入数据执行大量相同计算的例子,对于解算器如何工作的细节,这里并不感兴趣。这里进行讨论的目的是并行化解算器,使之能够同时解多个谜题。出于该目的,解算器将被当作黑盒处理。
解算器在模块Sudoku中实现,模块提供了一个函数solve,类型如下:
solve :: String -> Maybe Grid
每一个数独问题都通过一个String``{![即字符串。——译者注]}表示,该String的每个字符依次表示九宫格中一格的内容,或是空的,通过字符.表示,或是数字1~9。
函数solve返回值的类型是Maybe Grid,具体包括两种情况,无解用Nothing表示,有解则是Just g,这里g的类型是Grid。出于本例的目的,这里只对是否有解感兴趣,而对解本身(Grid)不感兴趣。
下面先从普通的串行代码开始说明。代码从文件中读取一系列数独问题,然后求解。
sudoku1.hs
import Sudoku
import Control.Exception
import System.Environment
import Data.Maybe
main :: IO ()
main = do
[f] <- getArgs --
file <- readFile f --
let puzzles = lines file --
solutions = map solve puzzles --
print (length (filter isJust solutions)) -- 上面这段简短的程序工作方式如下。
获取命令行参数,并要求只带一个参数,即包含输入数据的文件的文件名。
读取给定文件的内容。
将文件内容分割成行,每行一个谜题。
通过函数solve映射列表的每一行1,求解所有谜题。
先从列表中去除值为Nothing的元素,然后计算列表的长度,从而得出有解的谜题数量,最后将该值打印出来。即使对解本身不感兴趣,但对代码中的filter isJust还是有必要了解的:若缺少该部分代码,程序就不会对列表的元素求值,因此也就不会进行实际的求解计算(请回忆一下2.1节中length的例子)。
通过对一组样例问题的求解,可以检查程序是否正常工作。首先,编译程序:
`$ ghc -O2 sudoku1.hs -rtsopts
[1 of 2] Compiling Sudoku ( Sudoku.hs, Sudoku.o )
[2 of 2] Compiling Main ( sudoku1.hs, sudoku1.o )
Linking sudoku1 ...`
需要记住,当目标是程序性能时,使用完整的优化(-O2)进行编译非常重要。毕竟目标是让程序运行得更快。
现在,运行程序解1000个样例问题:
`$ ./sudoku1 sudoku17.1000.txt
1000`
这1 000个问题均有解,所以答案是1 000。但由于目的是让程序运行得更快,所以真正感兴趣的是程序运行的时间。因此,增加一些命令行参数再运行一遍:
$ ./sudoku1 sudoku17.1000.txt +RTS -s
1000
2,352,273,672 bytes allocated in the heap
38,930,720 bytes copied during GC
237,872 bytes maximum residency (14 sample(s))
84,336 bytes maximum slop
2 MB total memory in use (0 MB lost due to fragmentation)
Tot time (elapsed) Avg pause Max pause
Gen 0 4551 colls, 0 par 0.05s 0.05s 0.0000s 0.0003s
Gen 1 14 colls, 0 par 0.00s 0.00s 0.0001s 0.0003s
INIT time 0.00s ( 0.00s elapsed)
MUT time 1.25s ( 1.25s elapsed)
GC time 0.05s ( 0.05s elapsed)
EXIT time 0.00s ( 0.00s elapsed)
Total time 1.30s ( 1.31s elapsed)
%GC time 4.1% (4.1% elapsed)
Alloc rate 1,883,309,531 bytes per MUT second
Productivity 95.9% of total user, 95.7% of total elapsed参数+RTS -s让GHC运行时系统输出上面的统计结果。对分析性能的第一步来说,这些数据特别有帮助。这些输出的细节在GHC用户指南中均有解释,但这里只对Total time(总时间)这一项特别有兴趣。总时间这项包含两个数据:程序使用的总的CPU时间和elapsed时间或wall-clock时间。由于程序是在单核处理器上运行的,所以两者基本相等(由于系统的其他的活动,有时elapsed时间会稍长一些)。
下面的代码使用并行编程,利用两个处理器核心进行计算。首先将问题列表分成两份,然后并行地对这两个部分的问题进行求解。
sudoku2.hs
main :: IO ()
main = do
[f] <- getArgs
file <- readFile f
let puzzles = lines file
(as,bs) = splitAt (length puzzles `div` 2) puzzles --
solutions = runEval $ do
as' <- rpar (force (map solve as)) --
bs' <- rpar (force (map solve bs)) --
rseq as' --
rseq bs' --
return (as' ++ bs') --
print (length (filter isJust solutions))将问题列表分为两等份(若列表长度为奇数,则两部分长度相差一)。
使用前一节介绍的rpar/rpar/rseq/rseq模式对两个问题列表并行求解。但是,求解过程并非是完全直接的,因为rpar仅求值生成弱首范式。若仅使用rpar(map solve as),求值过程会在列表的第一个(:)这里停住,不再继续下去,因此rpar不会产生任何实际的并行计算。整个列表及其元素均需要进行求值,而不是部分求值,因此使用了force:
force :: NFData a => a -> a
函数force对其参数的整个结构进行求值,约化为范式,然后再返回。该函数在模块Control.DeepSeq中。对于NFData类,2.4节会继续讲解,现只要将其认为是一类可以求值为范式的类型即可。
使用rpar时,求值不够深入是一种常见的错误,因此,对于每一个rpar,养成思考其对应结构需要进行多少程度并行求值的习惯,会是一个不错的办法(实际上,在后面要介绍的Par monad中,设计人员在这方面做得有些过度以至于默认使用force,同样是一个常见的问题)。
通过使用rseq,等待两个列表求值结束。
将两个列表合并起来,形成完整的解列表。
下面运行程序,并测量并行化带来的性能提升:
$ ghc -O2 sudoku2.hs -rtsopts -threaded
[2 of 2] Compiling Main ( sudoku2.hs, sudoku2.o )
Linking sudoku2 ...
程序可以使用两个核运行:
$ ./sudoku2 sudoku17.1000.txt +RTS -N2 -s
1000
2,360,292,584 bytes allocated in the heap
48,635,888 bytes copied during GC
2,604,024 bytes maximum residency (7 sample(s))
320,760 bytes maximum slop
9 MB total memory in use (0 MB lost due to fragmentation)
Tot time (elapsed) Avg pause Max pause
Gen 0 2979 colls, 2978 par 0.11s 0.06s 0.0000s 0.0003s
Gen 1 7 colls, 7 par 0.01s 0.01s 0.0009s 0.0014s
Parallel GC work balance: 1.49 (6062998 / 4065140, ideal 2)
MUT time (elapsed) GC time (elapsed)
Task 0 (worker) : 0.81s ( 0.81s) 0.06s ( 0.06s)
Task 1 (worker) : 0.00s ( 0.88s) 0.00s ( 0.00s)
Task 2 (bound) : 0.52s ( 0.83s) 0.04s ( 0.04s)
Task 3 (worker) : 0.00s ( 0.86s) 0.02s ( 0.02s)
SPARKS: 2 (1 converted, 0 overflowed, 0 dud, 0 GC'd, 1 fizzled)
INIT time 0.00s ( 0.00s elapsed)
MUT time 1.34s ( 0.81s elapsed)
GC time 0.12s ( 0.06s elapsed)
EXIT time 0.00s ( 0.00s elapsed)
Total time 1.46s ( 0.88s elapsed)
Alloc rate 1,763,903,211 bytes per MUT second
Productivity 91.6% of total user, 152.6% of total elapsed可以注意到的是,现在总时间(Total time)显示出了CPU时间(1.46 s)和elapsed时间(0.88 s)的不同。之前,elapsed时间是1.31 s,可以计算出使用双核的加速比是 1.31/0.88 = 1.48。查看CPU时间有助于了解核心的忙碌程度,但从上面可以看到,使用多核运行程序的CPU时间经常比单核运行的wall-clock时间要长。因此使用CPU时间和wall-clock时间之比来计算加速比常令人误解(在这里是1.66 s)。所以加速比总是使用wall-clock时间之比计算。
一般来说,有多种原因导致了加速比只有1.48而没到2,并非所有的原因都受Haskell程序员控制。但在该问题中,有部分是由代码的写法造成的,可以通过ThreadScope工具诊断出来。为了使用ThreadScope剖析程序性能,需要用-eventlog标志重新编译程序,然后运行时再加+RTS -l参数。这样,程序运行时会输出一个名为sudoku2.eventlog的日志文件,供threadscope使用。
`$ rm sudoku2; ghc -O2 sudoku2.hs -threaded -rtsopts -eventlog
[2 of 2] Compiling Main ( sudoku2.hs, sudoku2.o )
Linking sudoku2 ...
$ ./sudoku2 sudoku17.1000.txt +RTS -N2 -l
1000
$ threadscope sudoku2.eventlog`
ThreadScope的性能剖析如图2-8所示,该图通过ThreadScope的“Export image”选项生成,因此只包含时间线图,而没有其他GUI部分。
图2-8中x轴为时间,水平方向的3条带状图形显示程序随时间的执行情况。最上面一条是“活跃”(activity)情况,显示当时有多少核心在执行Haskell代码(而非处于空闲或垃圾回收状态)。下面的每条代表一个核心,显示该核心在此时执行什么内容。每条分成两个部分:上面的,高一些呈绿色的表示核心在执行Haskell代码;下面的,低一些的,橙色或绿色的表示核心在进行垃圾回收。
图2-8 sudoku2 ThreadScope性能剖析
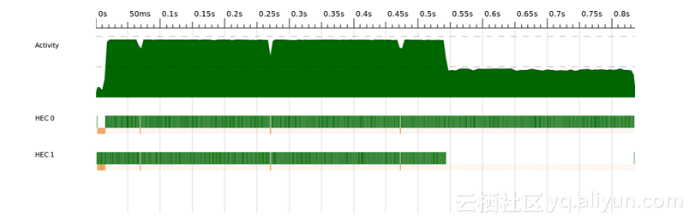
从图中可以看到,程序运行接近结束的一段时间里,只有一个核在执行程序,另一个处于空闲状态(除了GHC的并行垃圾回收器所必须的常规性垃圾回收操作)。这说明两个并行任务是不平均的:一个执行的时间比另一个要长。未充分的利用两个核心,是导致不理想的加速比的原因。
尽管问题列表被平分成两份,而且问题是偶数个,但每个问题求解花费的时间并不相同,具体的时间全都依赖数据解算器的搜索策略2,所以两个核心的工作负荷并不平均。
以上说明了并行化代码的一个重要原则:避免将工作划分成少量的固定数目工作块。具体有以下两个原因。
• 实际上,每块的工作量基本都不会相等,这部分不平衡会导致加速比的损失,正如例子里面所看到的。
• 并行化的程度受划分的块数限制。在本例中,即使工作负荷平均,无论使用了多少个核心,加速比也不会超过2。
即使通过将工作划分成与核心数相同的工作块来解决第二个问题,第一个问题依然存在,即每个工作块需要处理的工作量可能不同。
对于rpar的调用次数,GHC并没有强制的要求,调用次数完全由使用者决定,系统会自动将并行工作分配到可用的核心上去。若工作划分的更细,则系统就能让全部核心维持更长时间的忙碌。
将工作进行固定的分割常被称为静态划分(static partitioning),而在运行时将较小单位的工作分配到各处理器则被称为动态划分(dynamic partitioning)。GHC已经提供了动态划分的机制,只需通过足够频繁的调用rpar来产生足够的任务,GHC就能完成动态划分并平衡工作量。
函数rpar的参数被称为spark。运行时(runtime)将spark收集到spark池,当有处理器空闲时,通过一种称为工作密取(work stealing)的技术,从spark池中取出并执行。spark可能在未来某个时刻被求值,也可能不会——均取决于是否有空闲的核心。创建spark的开销非常低:rpar函数本质上是将一个指向表达式的指针写入一个数组。
下面对数独的求解尝试动态划分。首先,将并行地应用函数于一个列表的操作抽象成一个函数parMap:
`parMap :: (a -> b) -> [a] -> Eval [b]
parMap f [] = return []
parMap f (a:as) = do
b <- rpar (f a)
bs <- parMap f as
return (b:bs)`函数parMap的定义类似于monad风格的map函数,不同之处在于通过rpar将函数f应用于列表元素a的计算嵌入Eval monad中。因此,函数parMap会遍历整个列表,对每个元素a,为计算f a创建一个spark,最终返回一个新的列表。当函数parMap返回时,列表中的每个元素都有一个对应的spark。现在可以并行对所有的解进行求值。
sudoku3.hs
main :: IO ()
main = do
[f] <- getArgs
file <- readFile f
let puzzles = lines file
solutions = runEval (parMap solve puzzles)
print (length (filter isJust solutions))注意到该版本和第一版的sudoku1.hs基本上完全一样,仅有的区别在于将map solve puzzles替换为了runEval(parMap solve puzzles)。
运行新版的程序,加速比进一步提升:
Total time 1.42s ( 0.72s elapsed)
对应的加速比为1.31/0.72 = 1.82,接近理想的加速比2。此外,GHC运行时系统还提供了spark创建的数量:
SPARKS: 1000 (1000 converted, 0 overflowed, 0 dud, 0 GC'd, 0 fizzled)
程序运行中创建的spark正好是1000个,而且全部是converted(被转换,即在运行时确实被并行执行)的。下面是spark可能发生的其他情况。
overflowed(溢出)
spark池的大小是固定的,当spark池满时,试图创建spark会被丢弃,这种情况即溢出。
dud
当rpar应用于一个已被求值的表达式时,被认为是dud,该rpar将被忽略。
GC’d(被垃圾回收)
用于创建spark的表达式未被程序使用,因此该spark被运行时移除。更多细节会在3.4节讨论。
fizzled
表达式在创建spark时还未被求值,但后来被程序独立的求值了。这类spark也会被移出spark池。
这版程序的ThreadScope性能剖析看上去比前面的好得多(见图2-9)。此外,工作分配是由运行时管理的,程序可自动适应更多处理器的情况。例如,同一个程序在8核的机器3上测量出了5.83的加速比。
图2-9 sudoku3 ThreadScope性能剖析
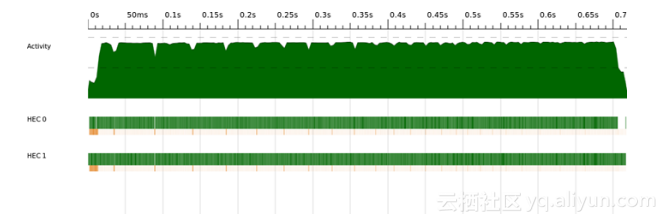
若仔细观察双核的性能剖析,可以发现在开始的一小段时间里似乎没有处理多少工作。实际上,在ThreadScope(见图2-10)里将这段时间放大,可以看到两个核心都在工作,但主要是垃圾回收,而且主要是由一个核心完成的。事实上,此时程序正在读取输入文件(惰性地),然后按行分割,再调用函数parMap,遍历这些行。将文件内容分割成行会产生大量的数据,从图中看似乎是在第二个核心上执行的。然而,可以注意到,即使分割文件是串行的,程序并未等待分割结束后才开始并行操作。当函数parMap获取到列表的第一个元素,即第一行的内容时,就创建了第一个spark。因此,在文件全部分割成行前,两个核心均已开始工作。在某种意义上,惰性求值让程序的并行程度变得更高。
图2-10 sudoku3:放大后的ThreadScope性能剖析
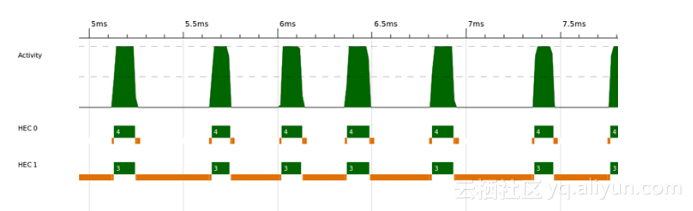
通过添加下面这行代码(见sudoku4.hs),可以试验强制完成行分割,然后再进行数独求解的效果:
evalute (length puzzles)
函数evalate就像IO monad中的seq:该函数将其参数求值为弱首范式,然后再将其返回。
evalute ::a → IO a
早期强制对行进行求值会略微降低程序的并行程度,由于行分割的过程和数独求解的过程不再有重叠,这时双核的运行时间是0.76 s。不过,这样就可以在ThreadScope里面清楚地看到串行和并行部分的边界(见图2-11)。
图2-11 sudoku4 ThreadScope性能剖析

观察上图,可以看到程序串行运行了16.7 ms,然后开始并行运行。若一个程序中包含了串行部分,就如此例,那么将不可能达到理想加速比。事实上,可以通过阿姆达尔定律来计算给定核心数时的最大加速比:
1/((1 - _P_) + _P_/_N_)
式中P为可并行运行的时间比例,N是可用的处理器数量。此例中,P为(0.76 − 0.0167)/ 0.76 = 0.978,最大可能的加速比是1.96。对两个处理器来说,串行部分比例太小,无法对理论最大加速比造成有效的影响。但如果有更多的处理器,假设64个,那么串行部分显得重要起来:1 /((1−0.978)+ 0.978/64)= 26.8。不管怎样,程序中这微小的串行部分都会将64核运行的加速比限制在26.8。事实上,即使是1024核,也仅能达到44左右的加速比,而且无论用多少核,加速比也无法达到46。从阿姆达尔定律可以看出,不但随着核心数的增加,并行加速变得更加困难,而且存在一个理论的最大并行度。
__
1映射的原文为map,即对列表的每个元素应用函数solve。——译者注
2实际上,输入的样例问题是经过排序的,使得能够清楚地示范这个问题。
3机器是Amazon EC2 High-CPU extra-large实例。

