本节书摘来自异步社区《深入理解Scala》一书中的第2章,第2.5节多态场景下的判等,作者[美]Josh Suereth,更多章节内容可以访问云栖社区“异步社区”公众号查看
2.5 多态场景下的判等
深入理解Scala
众所周知,为多态的面向对象系统定义合适的判等和散列方法是个特别难的过程。这是因为子类可能在整个过程中造成一些相当怪异的问题,尤其是当类型层次上有多个实体(concrete)级别的时候。一般来说,对于需要比引用判等更强的判等(译者注:比如需要判断对象内部数据)的类,最好避免多层实体类层次。这是什么意思呢?有些时候类只需要引用判等就够了。也就是说只要两个对象不是同一个实例就判为不等。但是如果我们需要判断两个不同实例是否相等,而且又有多层实体类层次(multiple concrete hierarchies),那我们在实现判等的时候就要特别小心了。
为了理解这个问题,我们来看下如何写一个好的判等方法。为此,我们从写一个显示和渲染时间线和事件的库开始。
2.5.1 例子:时间线库
我们想构建一套时间线,或称日历构件。这个构件需要显示日期、时间、时间安排,以及每天相关的事件。这个库的基础概念叫作一个瞬时(a instantaneoustime)。
我们用InstantaneousTime类表示时间序列中一个特定的时间片。我们本可以用java.util.Date类,但是我们更希望使用某种具有不变性的东西,因为我们刚刚学到了不变性使写好的equals和hashCode方法变得简单。为了简化例子,我们把时间保存为返回自1970年1月1日00:00:00 GMT以来的秒数(译者注,java.util.Date是毫秒数)。我们假定所有的其他时间都能格式化为这种形式的表示,而且时区和表现形式是正交的不同问题。我们还对应用中关于判等的使用做如下的一般假设。
• 如果调用equals返回true,这是因为两个对象是同一个引用。
• 大部分对equals的调用返回false。
• 我们实现的hashCode足够稀疏,对于大部分判等比较,hashCode会是不同的。
• 计算散列值比做一次深度判等比较的效率高。
• 引用判等比做一次深度判等比较的效率高。
上述假设是大部分判等实现的标准假设。但对你的应用来说不一定始终正确。我们现在初步实现这个类和简单的equals、hashCode方法,看下是什么样子。

这个类只有一个成员,repr,是个整数,表示自1970年1月1日00:00:00 GMT以来的秒数。因为repr是这个类里唯一的数据值,并且它具有不变性,equals和hashCode方法就基于这个值来实现。在JVM里实现equals时,一般来说在做深度判等前先判断引用是否相等的性能更高。但是在这个例子里就没必要这么做了。对于有一定复杂度的类来说,这么做(先判断引用相等)能够极大地提高性能,然而这个类太简单,真没必要这么做。设计好的equals方法的另一个常用范式是(在深度判等之前)用hashCode做个早期判断。在散列值足够稀疏且易于计算的情况下,这是一个好主意。跟引用判等一样,在当前这个例子里不是很需要这么做,但对于一个足够复杂的类来说,性能会高很多。
这个类告诉我们两个道理:① 好的判等方法很重要。② 你应该经常挑战代码里的假定条件。在这个例子里,按照“最佳实践”实现的判等方法,尽管对于足够复杂的类非常有用,但对于我们这个简单的类就几乎没上面好处。
注意:在给自己的类实现判等方法时,确认一下标准的判断实现方式中的一些假设对你的类是否适用。
我们的equals实现还有一个瑕疵,那就是多态。
2.5.2 多态判等实现
一般来说,最好避免在需要深度判等的情况下使用多态。Scala语言自身就出于这个原因不再支持case class的子类继承。然而,还是有些时候这样做是有用甚至是必要的。要做到这一点,我们需要确保正确地实现了判等比较,把多态放在脑子里,并且在方案中利用多态。
我们来实现一个InstantaneousTime的子类,这个子类比父类多保存了标签(label)。我们在时间线上保存时间的时候使用这个类,所以我们就叫它Event。我们假定同一天的事件被散列到同一个桶里,因此具有相同的散列值。但是判等则还要检查事件的名字是否相等。我们快速地实现一个。

我们抛弃了之前代码里的hashCode早期检测,因为在我们这个特定的案例里,检测repr的值性能是一样的高。你会注意到的另一件事是我们修改了模式匹配,使得只有两个Event对象才能做判等。我们在REPL里试用一下。
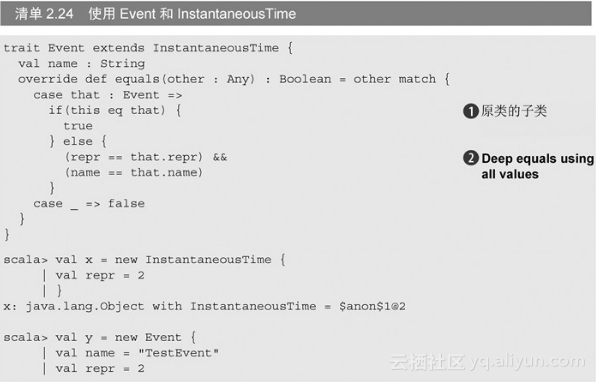
发生什么事了?旧的类使用旧的判等方法,因此没检查新的name字段,我们需要修改基类里最初的判等实现,以便考虑到子类可能希望修改判等的实现方法。在Scala里,有个scala.Equals特质能帮我们修复这个问题。Equals特质定义了一个canEqual方法,可以和标准的equals方法串联起来用。通过让equals方法的other参数有机会直接造成判断失败,canEqual方法使子类可以跳出(opt-out)其父类的判等实现。为此我们只需要在我们的子类里覆盖canEqual方法,注入我们想要的任何判断标准。
在考虑到多态的情况下,我们用这两个方法来修改我们的类。

我们做的第一件事是在InstantaneousTime里实现canEqual,当other对象也是一个InstantaneousTime时返回true。然后我们在equals实现里考虑到other对象的canEqual结果。最后,Event类里覆盖canEqual方法,使Event只能和其他Event做判等。
作者注:在覆盖父类的判等方法时,同时覆盖canEqual方法。
canEqual方法是个控制杆,允许子类跳出父类的判等实现。这样子类就可以安全地覆盖父类的equals方法,而避免父类和子类的判等方法对相同的两个对象给出不同的结果。
我们来看下之前的REPL会话,看看新的equals方法是否有所改善。

我们成功地定义了恰当的判等方法。我们现在可以写出一般情况下通用的equals方法,也可以正确处理多态场景了。