本节书摘来自华章出版社《移动数据挖掘》一 书中的第2章,第2.4节,作者连德富 张富峥 王英子 袁晶 谢幸,更多章节内容可以访问云栖社区“华章计算机”公众号查看。
2.4 语义信息标注
在重要地点检测之后,重要的工作就是进行语义标注。语义标注可以包含多种方法,其中一种是利用活动进行标注,比如从重要地点中带评论的文本信息中抽取的活动[156],或者是它所在区域的功能区块[141,145,41];另外一种重要的方法是利用附近的兴趣点进行标注,这种标注方法也称为地点命名[59,60]。下面我们将从这两个方面进行介绍。不过关于活动的标注方法,从文本中抽取活动将涉及文本抽取的知识,超出了本书所要介绍的方法,因此,在此只介绍如何确定区域的功能区块。
2.4.1 区域功能标记
快速发展的城市化进程和现代文明使得城市中形成了不同的功能区域,比如生活区域、商业区域、教育区域等,这些功能区域给人们的现代城市生活带来了很多便利,也为对大城市的细节化了解提供了新的视角。功能区域可能是城市的规划者从一开始就定义好的,也可能是人们在长期的生活中慢慢形成的。无论是区域的功能还是区域的规模和位置都会随着城市的发展而变化。
发掘不同区域的功能有着多方面的应用前景。举例来说,对于游客,轻松地分辨城市中的景点和商业区是一件对旅途十分有利的事情;对于城市规划者来说,城市在长期的发展中形成的功能区域与最初规划的很可能已经不一致了,了解当下真实的城市功能区域能够帮助他们更好地规划城市建设;对于从商人员或广告投放者来说,了解城市的构造能够大大增加他们的收益,比如在投建一个新超市的时候,只有了解了居民的生活区范围才能够最优化超市的未来盈利。
要发掘城市的不同功能区域,需要知道城市的兴趣点和城市内居民在不同区域间的移动轨迹。兴趣点包括了地点的地理坐标和种类,比如餐馆或商场。一方面,从大量的兴趣点数据中我们可以看出一个区域的功能,比如有许多大学和中学聚集的地方有很大概率是一个教育区域。但是另一方面,即使某一类型的兴趣点在两个区域都有着类似的分布,也不能说明这两个区域的功能一样,比如城市的不同区域都会有餐馆的分布,但是这些区域的功能不一定都是一致的。居民的移动轨迹可以从多种数据集中采集,比如手机的基站数据、开车过程中的行程记录、社交网络中的地理签到等。人们在不同区域之间的移动轨迹与各个区域的功能有着紧密的联系,联系主要可以分为两个方面:第一个是人们什么时候进入这个区域,什么时候离开;第二个是人们从哪个区域出发进入这个区域的,以及从这个区域出发会进入哪个区域。比如人们通常会在工作日的早晨离开居住区,晚上回到居住区,并且通常在工作日从工作的地方直接去娱乐场所,在周末则是从家里出发去娱乐场所。
挖掘不同区块的功能
要发掘不同区域的功能,首先需要对城市进行地理分割。城市中通常有遍布整个市区不同级别的路网,包括铁路和公路,这些路网将城市分成各个“单元区块”。每一个单元区块都是城市中的一个社交经济的基本单元,首先,人们的居住地和城市的兴趣点都是在这些单元区块中;其次,单元区块也是人们日常行程中的起始点和目的地。
划分好区块后,就可以开始挖掘不同区块的功能了。
定义3(移动模式) 一个移动模式M是一次移动行为中抽取的一个三元组。给定一次移动行为Tr=(Tr.rO,Tr.rD,Tr.tL,Tr.tA)(其中Tr.rO是起点、Tr.rD是终点、Tr.tL是出发时间、Tr.tA是到达时间),可以得到两个移动模式:离开移动模式ML=(Tr.rO,Tr.rD,Tr.tL)和到达移动模式MA=(Tr.rO,Tr.rD,Tr.tA)。
定义4(转移立方) 一个转移立方C是一个R×R×T的立方体,其中R是区块的数目,T是时间区间的数目。因为定义了两种不同的移动模式,因此这里要定义两种不同的转移立方;离开立方CL和到达立方CA。离开立方中索引为(i,j,k)的数据块表示在tk时间从ri离开去往rj的记录的数目,记录为
CL(i,j,k)={ML=(x,y,z)x=ri,y=rj,z=tk}
相似地,
CA(i,j,k)={MA=(x,y,z)x=ri,y=rj,z=tk}
将居民的移动行为轨迹映射到移动模式中,并且将每天分割成不同的时间区间,可以得到上面所定义的两种不同的转移立方。
概率主题模型在近些年得到了广泛的应用。假设语料库中的每篇文章样本都有多个主题,文章中的每个单词都支持着一个主题,那么给定每篇文章中的所有单词作为观测值时,该模型要做的就是发掘观测值背后隐藏着的主题。
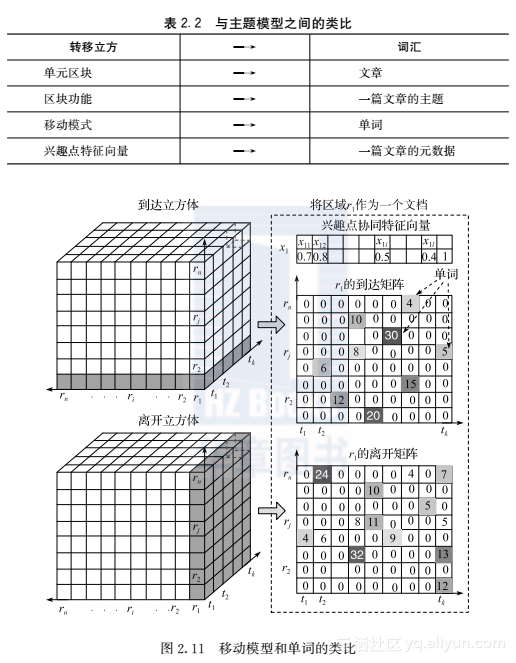
如表2.2中所示,可以将发掘一个区块的功能和发掘一篇文章的主题这两项工作很好地对应起来,一个包含多种功能的单元区块和一篇含有多个主题的文章具有很高的相似性。图2.11用了一个例子进一步展示了它们之间的类比。对于一个特定的区块ri,由CA(1:R,i,1:T)和CL(i,1:R,1:T)可以得到与ri相关的移动模式。图2.11的右边部分展示了组成r1的“文章”,其中一个数据模块代表了一个特定的移动模式,模块中的数字代表了模式出现的次数。一个兴趣点由一个三元组来表示,包括了兴趣点的类型、名字和地理位置(经度和纬度)。形式区块r的第i种兴趣点频率密度vi可以通过以下公式来计算vi=单元区块r中第i种兴趣点总的数目单元区块r的总面积r区块兴趣点的特征向量定义为xr=(v1,v2,…,vF,1),其中F是兴趣点的种类数目,最后添加的“1”是一个默认特征(在参考文献[84]中有具体说明)。兴趣点的特征向量被视为每个区块的元数据,与一篇文章中可以观察到的作者/邮箱/机构等特征类似。
基于狄利克雷多项式回归(DMR)[84]的主题模型,通过使用一个能支持自定义特征的灵活的架构,将可以观测到的一篇文章中的元数据都考虑在模型中,相比较其他只对特定数据友好的模型(比如作者主题模型等),基于DMR的主题模型拥有更广泛的使用空间。如图2.12所示,DMR模型的生成过程是:

这里是一个高斯分布,σ是其中的超参数,λk是与兴趣点特征向量长度一致的一个向量。单元区块r内第n个观察到的移动模式表示为mr,n。模型可以用EM算法或吉布斯采样算法来进行参数估计。
区域功能识别
得到了每个单元区块的主题之后,需要使用一个聚类算法将主题相似的区块聚合起来,使得同个聚类内的区块拥有相似的功能。对于区块r,假设用DMR模型计算得到的主题分布向量为θr=(θr,1,θr,2,…,θr,K),其中θr,k是第k个主题在区块r中的分布。使用K均值算法对R个区块的主题分布向量进行聚类,最终可以得到k个聚类,每个聚类表示一个功能区域。得到不同的功能区域后,还需要探讨一下区域真正的“语义”,也就是真正的“功能”,这与主题模型的可视化问题类似。在这里,通过考虑以下4个方面来实现这一点:①一个功能区域内的兴趣点结构。首先计算该功能区域的兴趣点特征向量的平均值,再对区域内的不同种类的兴趣点进行排序。②每个功能区域最高频的移动模式。③功能密度。将一个移动模式内的起始地和目的地输入到一个核密度估计(KDE)模型中来获得功能区域的功能密度,具体来说,给定一个2D空间里面的n个点x1,x2,…,xn,KDE对一个地点s的密度估算定义为
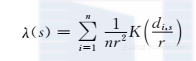
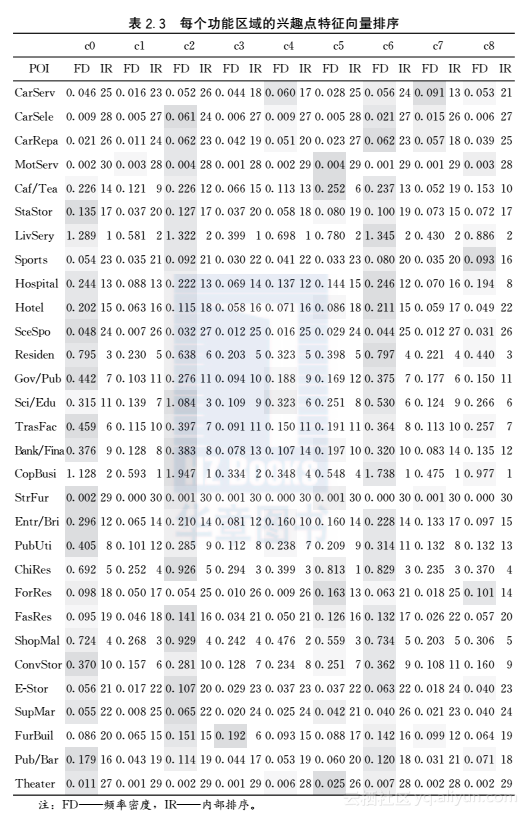
其中di,s是xi到s的距离,r是频宽,K(·)是核函数,这里使用高斯函数作为KDE估计的核函数。用这种方法可以获得每个功能核中具有代表性的兴趣点,从而可以估计区域的功能,比如如果某个功能区域的核中有很多大学和中学,那么这个功能区很可能就是一个教育区域。④人工标注的区域。有一些非常有名的区域的功能是显而易见的,比如包含紫禁城的旅游区域,通过聚类算法,一个聚类内的若干个人工标注的区域可以帮助我们理解聚类内其他区域的功能。图2.13展示了三种不同的方法挖掘出的不同城市功能区分割,其中每个区域的兴趣点特征向量排序可参考表2.3。

2.4.2 地点命名
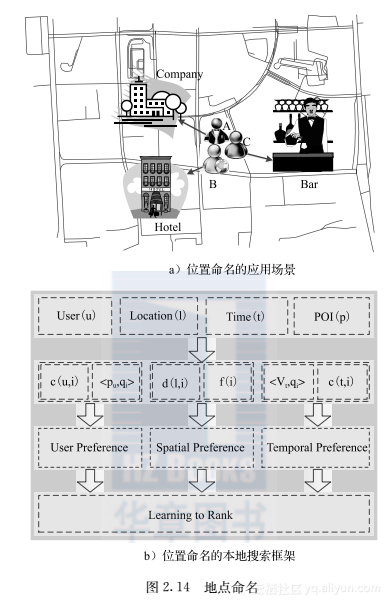
对重要地点进行语义标注的另一种做法就是利用附近的兴趣点进行标注,即地点命名。不过由于存在定位误差及兴趣点的高密度特性,一般无法直接利用距离最近的兴趣点进行直接标注。比如,考虑图2.14a中的应用场景:假设有三个用户A、B、C在某个星期六的下午三点都在同一位置“北纬39.976,东经116.331”的附近停留了很长时间。不过,若根据以前的观测,用户A经常在附近的写字楼上班,用户B在很多城市的宾馆和景点都有访问记录,而用户C经常访问游乐场所,那么可以推断A来这里加班,B可能在附近找住宿的地方由于附近有旅游景点,C应该是在这附近游玩。在命名时,这三个地方应该分别被命名为A的办公室、适合用户B偏好的酒店,以及用户C经常去的游乐场所。也就是说在对重要地点进行标注时,应该结合个性化的需求。为此,我们将该问题规约为一个排序学习问题,输入为用户的编号、访问时间及重要地点的经纬度,输出为附近兴趣地点的排名。排序学习的问题关键在于利用输入和兴趣地点来寻找排序的重要特征,以及如何学习这些特征的权重。参考文献[59,60]基于本地搜索的框架,设计了如图2.14b所示的学习框架。在这个框架下,提出了用户时空偏好模型,结合了用户偏好(UP)——fu(i)、空间偏好(SP)——fl(i)和时间偏好(TP)——ft(i)三大类偏好模型。这些偏好模型都会为每一个兴趣点输出一个偏好分数。将这些分数作为排序学习算法的输入来获取每一个兴趣点最终的偏好分数。
用户偏好模型
用户偏好(fu(i))通过排序学习的技术结合了用户在兴趣地点上的访问频数和用户对兴趣地点的兴趣值。用户u在兴趣地点i上的访问次数表示为cu,i,是通过对该地点的访问历史进行统计获得的。用户对兴趣点i的兴趣值fUIu(i)则表示成fUIu(i)=〈pu,qi〉
这种表示方法实际上是受参考文献[98]的影响,认为单纯地使用用户在兴趣地点的访问频率是会面临稀疏性问题的,即对很多地点的访问次数是零,因而可借助这种分解的方法来缓解稀疏性。在这个公式中,pu∈RKUP是用户u的长度为KUP的隐向量,可以被解释为用户u在某些潜在类别上的兴趣;qi∈RKUP是兴趣地点i的长度为KUP的隐向量,为对应到属于相应内在类别的可能性。用户隐向量和兴趣点隐向量的内积〈pu,qi〉可以认为是用户通过这些内在类别传递的对兴趣点的兴趣值。如果假设总共有M个用户、N个兴趣地点,那么就有(M+N)×{KUP}个参数,远远少于用户兴趣地点矩阵里面的元素个数(M×N)。原来的高纬空间(min(M,N))被降到了由这些潜在语义维所张成的低纬度的隐性空间(KUP)。换句话说,基于这种分解的方法来估计用户对兴趣地点的兴趣值,实际上是借助了相似用户的偏好来帮助找到他们可能感兴趣但从未访问过的地点,即访问次数为0的地点,因而也就减轻了用户移动数据历史稀疏性问题。
空间偏好模型
空间偏好模型(fl(i))考虑如何在只给定物理位置的情况下进行位置命名。换句话说,空间偏好模型不会区分不同的人和不同的时间。因此,它只是依赖于查询点l和兴趣地点i之间的距离dist(i,l)和兴趣点i的流行度f(i)。直观上说,空间偏好模型倾向于用那些更近的、更流行的兴趣地点来命名位置。关于兴趣点i的流行度,首先考虑了人们在兴趣点i签到的总次数ci,通过对地点访问历史的统计便可获得。除此以外,还考虑了来自于点评网站(比如大众点评网、Yelp等)的关于兴趣地点的点评数目和点评的平均分数。由于这些点评网站给人们提供了一个点评本地商店、分享点评信息的平台,所以一般具有高评分和多点评数的兴趣地点会更具有吸引力。在抽取得到这些分数之后,作为特征放入排序学习算法里面以得到最终的空间偏好。
时间偏好模型
由于用户的行为是随时间变化的,人们在不同的时间一般是如何进行位置命名的呢?由于人们的行为具有以周为单位的周期性,这种动态性需要建模成以周为周期的模式。比如说,人们一般在工作日上班、在周末休息或外出游玩。另外,人们的行为也有一定的天周期的模式,所以以周为周期的模式空间中存在一个低纬度的模式空间。然而,一周内不同的“天”里面的模式也会有些不同,比如说周末的模式会不同于工作日;工作日的第一天、最后一天和其他时间也会有所不同。因此,我们也需要区分一周内不同“天”的模式。然而,通常很难以启发式方式准确地定义这样的周期模式。为此,可以借助矩阵分解这种降维的方法来自动地发现这种称为时间兴趣的低纬结构。因而,在时间t对兴趣地点i的时间兴趣fTIt(i)就可以表示为fTIt(i)=〈rt,wi〉(2.11)其中rt∈RKTP是周小时t∈{0,…,T=167(7×24-1)}的隐向量,可以解释为用户在周小时t在潜在类别上的兴趣;而wi∈RKTP是兴趣地点i的隐向量,与用户偏好模型中的qi类似。这里区分它们的原因在于,它们所在空间的维度可能不同(KUP≠KTP)。除了这个时间段内的兴趣是时间偏好(ft(i))的一个特征以外,参考文献[60]还结合了在不同的时间点(包括周时间hw(t)和天小时hd(t))上兴趣地点的签到次数chw(t),i和chd(t),i,其中hw(t)和hd(t)是从时间t到周小时和天小时的映射函数。这三个值都将作为时间偏好模型中的排序学习算法的特征。
偏好学习
上述用户偏好和时间偏好模型中兴趣估计中的参数是通过最大化BPR-OPT[100]来学习的。BPR-OPT会在5.1.3节进行更系统的介绍。这里只针对具体的情形来说明:利用BPR-OPT作为矩阵分解优化目标的原因在于它可以刻画访问地方和未访问地方之间两两之间的排序偏好,这个与我们最终利用排序的方法来进行位置命名的目标是一致的。特别地,参考文献[100]通过优化有反馈的物品(正例)和其他物品(负例)之间的排序偏好(也就是BPR-OPT)来学习这些隐向量。针对如何在用户兴趣估计问题和时间兴趣估计问题中定义这个目标,并且进一步扩展来约束朋友或邻近时间段的隐向量之间的临近性。
首先把包含了所有参数的Θ放入给定情境a的评分函数fa(i)中,也就是fa(i;Θ),其中a∈{u,t}。根据参考文献[100],BPR-OPT被定义为
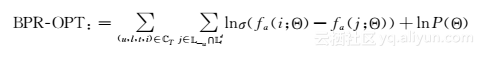
其中σ(x)=11+e-x是一个逻辑斯特函数,把任意的实值隐射到(0,1)区间内。这里定义的BPR-OPT和原来的有所不同:这里只有在情境a中没出现,而且离用户物理位置不到d公里的兴趣点(也就是P-a∩Pdl)是作为负例j的。这些负例不仅是用户没有去过的点,而且需要在用户当时所处的位置附近。直观来讲,对于那些在用户周围的兴趣点,用户应该对它是有所了解的。用户不去这个地方可以说明用户对这些地方不是很感兴趣。P(Θ)是参数的先验分布。在参考文献[100]中,它是一个球形的高斯分布(同一类型参数的正则化系数是一样的)。在此情况中,除了这个球形的高斯分布,还可以考虑在参考文献[73]中使用过的高斯马尔可夫随机场(Gaussian Markov Random Field)先验,来限制朋友或邻近时间段的隐向量之间的临近性。比如,如果两个人是社交网络上的朋友,那么他们的隐向量应该差距较小。其背后的假设是,朋友之间具有某种共同的兴趣爱好。同样,同一天的下午3点到4点的时间段和4点到5点的时间段也被认为是一种邻居,所以它们的隐向量也应该具有较小的差异性。利用MRF作为先验也是受参考文献[77]中的比较结果启发而来的,因为该方法会比在参考文献[73,74,77,46]中提出的其他方法更好。根据在参考文献[73]中提到的,这两个先验以专家积(product of experts)的方式结合在一起。考虑了这两个先验信息之后,BPR-OPT的目标就变成
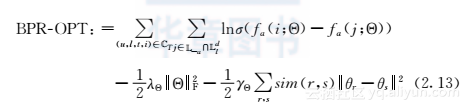
其中r和s是时间或用户的索引,而θr和θs就是相应的隐向量。r和s之间的先验知识是sim(r,s),而它们的隐向量之间的临近性则是通过它们之间的欧氏距离的平方来满足,也就是θr-θs2。因而公式(2.13)最后一项(包括负号)的最大化可以使得邻居的隐向量具有低差异性,其中γΘ>0是一个控制这种限制的系数。另外Θ2F是Frobenius范数的平方,用来防止过拟合的,λΘ是一个控制过拟合程度的系数。针对修改后的BPR-OPT的优化,可以借助随机梯度下降SGD[100],即每次采用一个三元组(u,i,j),其中用户u访问过地点i但是没有访问过地点j。而且j是从集合L-a∩Ldl上采样得到的。
排序学习组合特征:对于每一个来自于地点访问历史的记录c,用户c.u访问了兴趣地点c.i,则它被标记为正类(相关类)。在访问地点的过程中,附近周围的(d公里以内的)除了c.u访问过的兴趣地点Lc.u,即Ldc.l-Lc.u,在这个时刻下可能是用户不喜欢的,所以它们被标记成负类(不相关类)。组合这些特征学习相应权重的过程实际上对应到了一个具有二值相关性的排序学习问题。然后为L=Ldc.l-Lc.u+1个兴趣点抽取相应的特征和类别标记。特别地,对于其中每一个兴趣点i,我们可以从访问历史和辅助数据源中抽取相应的特征从而形成一个特征向量fia∈RF,其中a是我们之前提到过的情境,而F是抽取得到的特征个数。如果我们以用户时空模型为例,fia是一个长度为3的实值向量,也就是fia=[fl(i);fu(i);ft(i)]∈R3×1,其中“[]”是向量和矩阵组合操作符。把这些长度为L的列向量按列堆积得到一个特征矩阵X=[fi1a,…,fiLa]T∈RL×F,其中XT是矩阵X的转置。因而,特征矩阵的每一行就代表了某个兴趣地点的特征向量。然后给L个兴趣地点用之前方法得到的相关性标签来标记相关性,从而得到一个与特征矩阵X中的顺序相对应的标记向量y∈RL×1,也就是说y=[yi1;…;yiL]。特别地,yij∈{0,1},0≤j≤L是L个兴趣地点中兴趣地点ij的相关性标签。通过抽取这些特征和标签,移动历史就被表示成一个特征标记对(X,y)的集合,其中每一对都对应了一条移动记录。然后三类排序学习算法(单点法pointwise、配对法pairwise和列表法listwise)被应用来学习从特征矩阵X映射到标记向量y。单点法只是考虑了单个特征向量和相应标签的映射,类似于传统的有监督学习过程,因而大部分的分类和回归算法都可以被应用。配对法考虑(fia,yi)和(fja,yj)之间的相对顺序,同样这个问题也被归为一个基于(fia,fja,rel(yi,yj))的分类问题,其中rel(yi,yj)表示了两个标签的相对顺序。换句话说,配对法把一对特征向量(fia,fja)作为输入,输出它们在情境a下的相对偏好。列表法是把(X,y)作为一个整体来输入的,从而来考虑在情境a下这L个兴趣地点的全局排序。关于更多排序学习的介绍和它们的分类,可以参考刘铁岩老师的综述文章[71]。