本节书摘来自华章出版社《移动数据挖掘》一 书中的第2章,第2.3节,作者连德富 张富峥 王英子 袁晶 谢幸,更多章节内容可以访问云栖社区“华章计算机”公众号查看。
2.3 重要地点检测
很多移动轨迹数据都具有非常高的冗余性,比如,志愿者收集的GPS轨迹和出租车的GPS轨迹都是间隔几秒记录一次GPS点。然而,这些移动对象在短短几秒内乃至十几秒内一般不会有大的变化。另外,有很多中间的物理,用户只是经过,并不感兴趣。因而,需要对所收集的这些移动轨迹数据进行预处理,抽取出用户感兴趣的地方。这类兴趣地点应该具有停留时间较长的特点。也就是说,这类兴趣地点应该在空间维度具有聚集效应。为此,大部分先前的重要地点检测的方法是在时间约束的情况下在空间维度进行聚类。这类工作的先驱者是佐治亚理工学院的阿什布鲁克和斯达纳教授。他们在文章[6,5]中提出了place(地方)和location(地点)的概念,认为地方是带有时间区间(即停留时间)的GPS位置,而地点则是地方(place)的聚类。place的检测比较简单,首先需要将GPS轨迹中在顺序上邻接的距离在GPS误差范围(10米以内)以内的GPS点合并,作为一个place,其GPS位置即为这些GPS的平均值,同时取出该place在轨迹中第一次出现的时间和最后一次出现的时间,这两个时间之间的时间间隔作为该place的停留时间。他们的文献所阐述的关于place的聚类算法类似于mean-shift聚类的思想。即每次从一个place开始,带上一个半径,然后针对所有存在于place半径范围内的place点来计算均值。这个均值点作为新的place,再重复上述过程,直到均值不再变化为止。这个时候就找到了第一个location。然后把这个location相关的place点删除。针对剩下的place点进行上述聚类方法,直到将所有的点都删除完。图2.8给出了聚类的示例。关于聚类中取多少个类的问题,作者采用了绘制聚类个数随着半径增长的图,然后从图中找到拐点处(knee)作为最终的聚类半径。这里的拐点和数学中拐点的定义不同。数学中的拐点是可微分曲线中改变凹凸性的点,而

这里需要注意的是,聚类算法是不考虑时间上的约束的,即不管这两个place在访问时间上是否相隔很久。此外,该文献中还考虑了location的地理层次性问题,并定义了sublocation的概念,并应用上述类似的聚类算法在每个location中寻找sublocation。
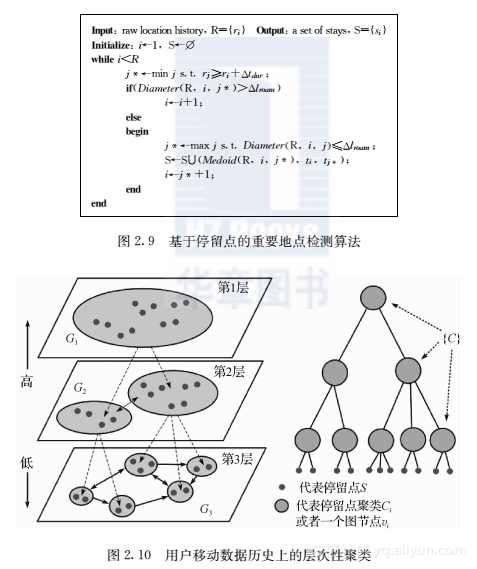
在此之后,很多相关的重要地点检测的算法[38,47,48,69,159,16]先后被提出。大部分算法的思想都是类似的,可能location和place的相关概念有所不同,或者是把location的形成和place的抽取合并为一个过程。比如在参考文献[47,48]中,提出了一种基于时间的聚类方法,这种聚类方法不仅能够自动确定聚类的个数,而且还会过滤掉一些噪声点。这个聚类算法对GPS的轨迹流进行聚类,并且丢弃停留时间很短的那些小簇。特别地,轨迹流的第一个GPS点形成一个当前簇,之后的每一个GPS点都会与当前簇的所有GPS点进行比较,如果平均距离大于某个阈值,则会形成一个新的簇,否则将并入原来的簇中。关于算法中的时间阈值和距离阈值的确定,同样是通过类似于上述的拐点的方法来获得的。另一类方法始于参考文献[38],其中提出了与place类似概念的停留点(stay of point)。参考文献[55,69]做了跟进,不过并没有在重要地点检测这个问题上做出方法的创新。停留点定义为停留了一段时间的某个地方。从字面上看,这个词由于有“停留”,蕴含了时间概念,因而表述更加贴切,因此后续的研究中被使用得更多。停留点依赖于两个参数,一个是停留阈值,代表停留的最少时间;另一个是距离阈值,代表这个地方的最大地理范围。下面给出参考文献[38]的算法框架,如图2.9所示。算法中的函数Medoid(R,i,j)和Diameter(R,i,j)是在集合{rkrk∈R,i≤k不过在检测停留点之后,从不同轨迹中检测出来的停留点之间可能是不一致的,即有些离得很近的停留点却是不同的,被赋予了不同的停留点编号,这为所有人进行用户移动建模和基于移动行为进行朋友关系预测制造了很大的困难。为此,与斯达纳教授团队的研究类似,也需要对这些来自不同轨迹的停留点进行聚类。不同的研究工作在聚类算法上大同小异[55,16],一般都是利用K均值或类似于DBSCAN的密度聚类法,而且一般是具有层次性的,如图2.10所示。它们的差异性主要体现在使用的特征上,比如在参考文献[6,55]中,使用停留点之间的物理距离来进行聚类。而在参考文献[16]中,不仅使用了距离,还使用了停留点的语义信息,比如停留点的访问时间差异性、停留时间差异性、访问用户群体的相似性,以及相关语义信息。