本节书摘来自华章出版社《位置大数据隐私管理》一 书中的第2章,第2.4节,作者潘晓、霍 峥、孟小峰,更多章节内容可以访问云栖社区“华章计算机”公众号查看。
2.4 位置依赖攻击
2.1节至2.3节中介绍的攻击模型仅关注快照(snapshot)位置,若用户位置发生连续更新将产生新的攻击模型,典型的攻击模型有位置依赖攻击和连续查询攻击。本节先介绍位置依赖攻击,2.5节将介绍连续查询攻击模型。
位置依赖攻击模型也被称为基于速度的连接攻击模型,指当攻击者获知用户的运动模式(如最大运动速度)时产生的位置隐私泄露现象。具体来讲,根据用户的最大运动速度,可得到用户在某一时间段内的最大可达范围。因此,可以将用户的位置限制在最大可达到的区域与第二次发布的匿名区域的交集中,进而产生位置隐私泄露[57, 54]。在位置依赖攻击中,攻击者的背景知识包括历史匿名区域组成的集合和用户的最大运动速度。定义2-14给出了位置依赖攻击的形式化定义。
位置依赖攻击:假设
- 用户u在时刻ti和tj的匿名区域分别是 和 。
- 用户u的最大运动速度为vu。

则称用户u的位置隐私受到威胁,称此攻击为位置依赖攻击。
位置依赖攻击表达的语义是:如果攻击者知道用户上一个时刻匿名区域 和最大运动速度vA,则用户A在ti+1的位置被限定于最大运动边界(Maximum Movement Boundary,MMB) 当中。从而攻击者可以推测出用户在ti+1时刻一定位于 和 的交集中。类似地,攻击者通过用户在ti+1时刻发布的匿名区域 可以得到从时刻ti到ti+1期间,用户A可以从哪些位置到达 中,形成匿名集。所以用户A在上一个时刻ti被限定于 和 的交集中。在最坏情况下,如果两个阴影区域中的任何一个成为精确点,则用户位置隐私泄露。
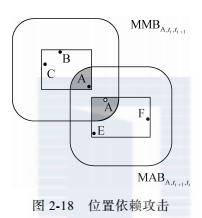
下面用一个具体实例说明位置依赖攻击模型的语义。图2-18的例子中,用户A、B、C在时刻ti组成匿名集,其匿名区域是 ;用户A、E、F在时刻ti+1组成匿名集,匿名区域是 。服务提供商收集用户连续的匿名区域 和 ,以及用户A的最大运动速度vA。
攻击者根据已知的用户上一个时刻的匿名区域 和最大运动速度vA,可以推测用户A在ti+1时刻的位置一定在 (如图2-18左上角圆角矩形所示)中。从而攻击者可以推测出用户A在时刻ti+1一定位于右下角灰色阴影区域( 和 的交集)中。类似地,攻击者通过用户A在ti+1时刻发布的匿名区域 可以得到从时刻ti到ti+1期间,用户A可以从哪些位置到达 中,形成匿名集,即图2-18中右下角的圆角矩形。所以用户A在上一个时刻ti被限定于左上角阴影区域)中( 和 的交集)。用户A的 是图2-18中的右下角灰色阴影区域。因为 ,所以此例中的A在ti+1时刻的位置泄露。另外, 是图2-18中左上角阴影区域, ,所以用户A在时刻ti的位置亦泄露。
位置依赖攻击是由用户运动模式已知造成的。防止位置依赖攻击的匿名方法可以沿用位置k-匿名模型保护用户的标识符,采用空间粒度标准,即时空匿名法保护用户的位置信息。文献[29]中提出,对于时刻ti和时刻tj的匿名区域Ri到Rj,从Ri到Rj (从Rj到Ri)的最大最小距离若满足MaxMinD(Ri, Rj)≤vu(tj -ti)(MaxMinD(Rj, Ri)≤vu(tj -ti)),任意两个时刻发布的匿名区域均可防止位置依赖攻击(具体保护方法可参见4.1节)。

