本节书摘来自华章出版社《位置大数据隐私管理》一 书中的第1章,第1.5节,作者潘晓、霍 峥、孟小峰,更多章节内容可以访问云栖社区“华章计算机”公众号查看。
1.5 典型的位置隐私保护技术
传统的LBS隐私保护技术可以归纳为3类:基于数据失真的位置隐私保护方法、基于抑制发布的位置隐私保护方法以及基于数据加密的位置隐私保护方法。不同的位置隐私保护技术基于不同的隐私保护需求以及实现原理,在实际应用中各有优缺点。
1.5.1 基于数据失真的位置隐私保护技术
基于数据失真的方法,顾名思义是指通过让用户提交不真实的查询内容来避免攻击者获得用户的真实信息。对于一些隐私保护需求不严格的用户,该技术假设用户在某时刻的位置信息只与当前时刻攻击者收集到的数据有关,满足直觉上的隐私需求,提供较高效的隐私保护算法和较快的服务响应。采取的技术主要包括随机化、空间模糊化和时间模糊化3种形式。这3类技术的共同点是一般假设在移动用户和服务器之间存在一个可信任的第三方服务器,该服务器可以将用户的位置数据或查询内容转换成接近但不真实的信息,然后再提交给服务器。同时,将服务器返回的针对模糊数据的查询结果转化成用户需要的结果。
1.随机化
随机化是在原始位置数据中加入随机噪声。可信第三方服务器在接收到用户的准确位置后,将噪声和准确位置都发送给服务提供商。在服务提供商返回候选结果集后,可信第三方根据用户的真实位置对候选结果集过滤求精,返回真实的查询结果给相应用户。文献[15]中首次提出了随机化方法,在每一时刻,根据上一时刻的位置按照随机的速度和随机的方向进行移动,并将获得的随机位置点加入到原始数据中进行发布。然而,这些随机位置点组成的历史数据的移动特征与真实移动对象的特征具有很大差别,甚至提交的位置可能是一些实际上不可达的位置,因此很容易被攻击者区分。为此,文献[31]中在产生随机位置数据的时候加入了路网、移动速度等移动特征的约束条件。在文献[15]和[31]中假设物体在不停地移动,文献[17]中考虑到移动对象不会不停地移动,根据移动对象的周围环境等因素让移动对象随机产生停顿,以进一步防止攻击者区分这些噪声。
2.空间模糊化
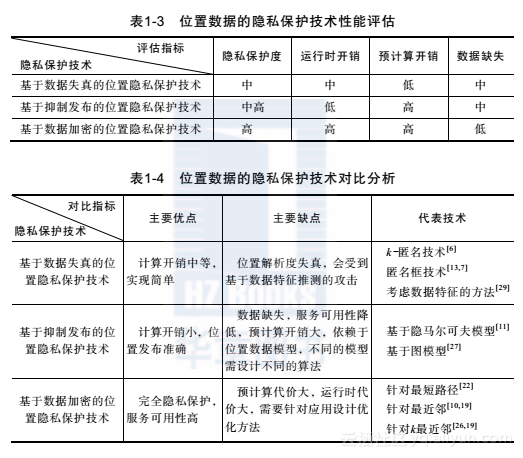
空间模糊化通过在一定程度上降低发布位置数据的精度以满足用户隐私需求,具体来讲,即将用户提交的位置精度从一个点模糊到一个区域,以致攻击者无法获得某个用户清晰的位置。图1-2是某一时刻标号为A~E的6个移动用户在空间中的位置。根据四分树(Quad-tree)划分技术[13],空间被划分成若干区域,用户希望每次发布的位置数据不要准确到区域中只有一个用户。于是,用户A(B, C)在发布自己的位置时,可以发布左下角阴影区域作为自己的位置;用户D(E, F)可以发布右上角阴影区域作为自己的位置。假设每个移动对象均向服务提供商发送自己所在的阴影区域来请求近邻查询,服务提供商需要计算包含阴影区域中任何一点的最近邻的区域,返回其中包含的全部用户。例如,对于包含右上角阴影区域的近邻查询,服务器只需要返回阴影区域和黑色区域包含的全部用户,发起查询的用户就可以自行计算出自己的近邻。
3.时间模糊化
时间模糊化通过增加位置数据时间域的不确定性,以减少位置数据的精度。图1-3例举了一个简单的时间模糊例子。图1-3a是两个移动物体在路网上运动的示意图。物体1的移动轨迹用黑色表示,物体2的移动轨迹用灰色表示。没有经过时间模糊时,它们要提交的位置信息如图1-3b第1、2行所示,其中A、B和C表示物体1的位置。假设用户希望t2时刻在黑色框内的用户不唯一,则经过时间模糊后的位置数据如图1-3b第3、4行所示。在t2时刻,黑色框内物体1和物体2同时在位置C出现,达到了用户的隐私要求。时间模糊化的隐私保护方法易于操作且实际应用通常不需要很大程度的数据改变量,所以它被广泛应用在LBS隐私保护中。考虑到移动对象在某些敏感位置和时间域上展现一定的特征,例如,在交通路口当红色交通信号灯亮时,附近的移动对象会在较长时间内没有位置变化。通过对位置数据的时间域进行模糊,能够避免攻击者察觉到用户处于交通路口这一事件的发生[28]。同时,当满足用户隐私要求的区域不存在时,使用时间模糊化可以实现用户的隐私需求[7,29,25]。

1.5.2 基于抑制发布的位置隐私保护技术
1.5.1节中介绍的方法只考虑当前时刻的位置是否会暴露用户的敏感位置,然而,用户的隐私信息可能会由于位置数据在时间和空间上的关联而泄露。事实上,有研究表明用户在未经保护的情况下提交查询时,位置数据在时间和空间上的关系可以通过多种模型来刻画。当前主要使用隐马尔可夫模型[5]或一般化图模型[13]来刻画用户的位置数据在时间和空间上的关系。
2012年,文献[11]中提出了基于隐马尔可夫模型的概率推测抑制法。该方法针对LBS应用中用户连续地向服务器发送位置信息的场景,假设攻击者具有足够的背景知识,并对用户提交的每个位置数据推测用户隐私。该工作提出了Maskit系统,帮助用户判断提交当前位置数据是否违反用户隐私要求。对于违反隐私要求的位置信息采取概率性的抑制发布策略,以此来保证攻击者无法以较高的后验概率推测出用户处于哪个敏感位置。
图1-4是将用户移动模式用隐马尔可夫模型建模的示意图。用户从每天的起始位置开始移动,以后的各个时刻会根据上一时刻用户位置的不同,转移到各个其他位置,其中有些位置是敏感位置(在图中用浅色阴影表示)。转移的概率由模型建立时形成的参数确定。攻击者推测用户处于敏感位置的先验概率是0.2,假设无论用户处于敏感位置或非敏感位置都以0.5的概率发布位置,则当攻击者接收到抑制发布的位置信息时,根据贝叶斯公式,攻击者推测用户处于敏感位置的后验概率为:
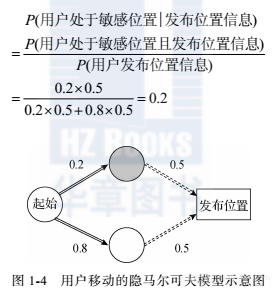
隐马尔可夫模型认为用户发布的位置数据只与其当前所处的位置有关。这样的假设有利于模型的高效创建,但对用户在某时刻处于某位置的概率计算并不十分准确。考虑到历史数据也会暗示用户当前位置是否敏感,因此历史数据也对当前位置是否能够安全发布具有很大影响。总之,当前时刻所处的位置和之前的历史数据均对是否发布位置数据有影响,且影响基于位置服务的可用性。为此,文献[11]中提出了两种不同的抑制方法,这两种方法针对各自的用户群体具有各自适宜的服务可用性。
第一种抑制方法:设反映对各个位置的发布概率的向量p=( p1,…,pn),其中pi表示用户处于第i个位置时以pi的概率发布。方法一从p=(0,…,0)开始(即完全不发布位置信息)。利用MONDFRIAN和ALGPR等贪心优化方法,逐渐调整各个位置的发布概率。发布概率向量确定后,根据给定的移动轨迹,利用贝叶斯公式和隐马尔可夫模型分别计算用户属于敏感位置的后验概率和先验概率。根据后验概率与先验概率之差,判断p是否满足隐私需求,不断调整p中各个元素的值直至收敛。在实际运行中,系统按照收敛后的发布概率向量在各个位置上发布用户的位置信息。
第二种抑制方法:根据用户历史位置数据计算用户当前处于敏感位置的先验概率;然后通过考虑未来所有可能的位置发布,计算发布当前位置以后用户在各个时刻处于各个敏感位置的后验概率;与第一种方法类似,根据后验概率与先验概率之差,判断发布当前位置是否违反隐私需求,从而在线决定是否发布该位置。文献[11]将“考虑未来所有可能的位置发布”这样一项时间复杂度极高的任务,简化成了多项式时间内可完成的任务。
一方面,基于抑制的隐私保护方法提交了用户的若干真实查询,当攻击者具有用户的背景知识时,攻击者可以根据用户发布的位置直接得到用户所在的位置;另一方面,基于抑制的方法牺牲了LBS应用的可用性,用户在查询被抑制时无法得到服务。
1.5.3 基于数据加密的位置隐私保护技术
1.5.1节和1.5.2节介绍的隐私保护技术通过发布失真位置数据和抑制发布位置数据的方法,达到了对位置大数据隐私保护的目的。然而,这两类方法无法满足具有较高隐私需求用户的要求。基于数据加密的方法是指利用加密算法将用户的查询内容(包括位置属性、敏感语义属性等)进行加密处理后发送给服务提供商。服务提供商根据接收到的数据在不解密的情况下直接进行查询处理。服务提供商返回给客户端的查询结果需要用户根据自己的密钥进行解密,并获得最终的查询结果。在这个过程中,服务提供商因为没有密钥,无法得知用户的具体查询内容,甚至对返回给客户端的查询结果的含义也无法掌握。
最早基于数据加密的方法是通过利用空间填充曲线转换数据空间实现的。Khoshgoz-aran等人提出了利用Hilbert曲线将表示位置信息的二维坐标从二维空间转换到一维空间,利用一维空间的邻近性来解决近邻查询等空间查询问题[18,20]。当用户提出查询请求的时候,将查询位置的二维坐标转换成一维的Hilbert值并发送给服务提供商。服务提供商根据在一维空间的值查询出满足条件的对象返回给用户。在此过程中,服务提供商只能返回给用户近似解。同时,该方法因空间填充曲线的局部性和距离维护性会导致潜在的隐私泄露风险。
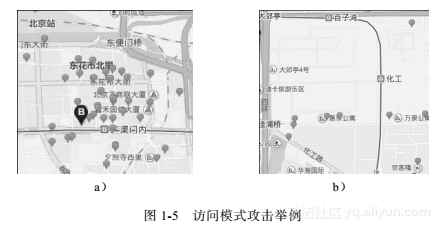
第二类是利用同态加密等加密工具结合数据库索引技术来防止空间查询处理过程中的隐私泄露。文献[37]提出了基于查询隐私保护的层次型索引结构,可支持多种查询类型。该方法从查询隐私和数据隐私两个方面进行设计,然而该方法依然存在查询关键字的泄露风险。因为提交用户的每个查询后,在服务器端按照算法执行的过程会形成一个访问模式(如访问服务器数据库的次数、单次访问的数据量大小等)。访问模式的不同给攻击者带来了推测隐私的机会。以图1-5为例,当用户提出的查询位于兴趣位置点(Point of Interest,POI)分布稀疏和密集的两种情况下,需要的数据页访问数量肯定是不同的。攻击者可根据当前查询的访问模式推测出查询是位于POI分布稀疏的区域,还是位于POI分布密集的区域,由此会导致隐私泄露。第一类和第二类方法均不能阻止攻击者通过访问模式对用户的查询内容进行推测。
第三类是基于私有信息检索(Private Information Retrieval,PIR)技术的隐私保护方法。PIR理论最早被应用于访问网络中的外包数据,用户可以检索一个不可信服务器上的任意数据项,而不暴露用户检索的数据项信息[4]。当用户提交查询数据库中索引为i的数据块时,PIR技术可以在服务器不知道用户的查询内容(i)的前提下为用户返回其查询的数据块。基于PIR的隐私保护技术大致可以分为3类:基于信息论的PIR技术、基于计算能力的PIR技术以及基于硬件的PIR技术。其中后两种被研究者普遍应用于最短路径计算[22]以及近邻查询[12,10,26]计算。
1.5.4 性能评估与小结
位置数据隐私保护技术需要在保护用户位置隐私的同时兼顾服务可用性以及开销。一般从以下3个方面度量位置隐私保护技术的性能:
1)服务的可用性,指发布位置信息的准确度和及时性,反映通过隐私保护技术处理后用户获得的基于位置数据的服务质量。
2)隐私保护程度,通常由隐私保护技术的披露风险来反映。通常,服务的可用性与隐私保护程度之间具有一个权衡,提高隐私保护程度有时会降低服务的可用性。
3)开销,包括预计算和运行时发生的存储和计算代价。存储代价主要发生在预计算时,该代价在现有技术中通常可以接受,并在选择隐私保护技术时被忽略。运行时的计算代价根据位置大数据隐私保护技术的特点,一般利用CPU计算时间以及文件块访问次数的时间复杂度进行度量。
每类位置数据隐私保护技术都有不同的特点。表1-3从隐私保护度、运行时开销、预计算开销和数据缺失4个方面分析比较了现有的各种隐私保护技术。从表1-3可以看出,不同方法的适用范围、性能表现等不尽相同。当对位置数据的隐私程度要求较高且对计算开销要求较高时,基于抑制发布的位置大数据隐私保护技术更适合。当关注位置信息的完美隐私保护时,则可以考虑基于数据加密的位置大数据隐私保护技术,这时计算量以及响应时间上的代价较高。基于数据失真的位置隐私保护技术能够以较低的计算开销实现对一般隐私需求的保护。表1-4从技术层面对各种方法的优点、缺点以及代表性技术作了进一步的对比显示。