本节书摘来自华章出版社《精通Python网络爬虫:核心技术、框架与项目实战》一书中的第3章,第3.1节,作者 韦 玮,更多章节内容可以访问云栖社区“华章计算机”公众号查看。
第二篇 Part 2
核心技术篇
第3章 网络爬虫实现原理与实现技术
第4章 Urllib库与URLError异常处理
第5章 正则表达式与Cookie的使用
第6章 手写Python爬虫
第7章 学会使用Fiddler
第8章 爬虫的浏览器伪装技术
第9章 爬虫的定向爬取技术
通过前面章节的学习,我们已经基本认识了网络爬虫,那么网络爬虫应该怎么实现?核心技术又有哪些呢?在本篇中,我们首先会介绍网络爬虫的相关实现原理与实现技术;随后,讲解Urllib库的相关实战内容;紧接着,带领大家一起开发几种典型的网络爬虫,让大家在实战项目中由浅入深地掌握Python网络爬虫的开发;在学会了一些经典的网络爬虫开发之后,我们将一起研究学习Fiddler抓包分析技术、浏览器伪装技术、爬虫定向抓取技术等知识,让大家更加深入地进入到网络爬虫技术的世界中来。
第3章
网络爬虫实现原理与实现技术
我们已经初步认识了网络爬虫,并了解了网络爬虫的应用领域。在这一章中,我们将学习网络爬虫的实现原理及其实现技术,并使用metaseeker为大家做一个简单的爬虫案例。
3.1 网络爬虫实现原理详解
不同类型的网络爬虫,其实现原理也是不同的,但这些实现原理中,会存在很多共性。在此,我们将以两种典型的网络爬虫为例(即通用网络爬虫和聚焦网络爬虫),分别为大家讲解网络爬虫的实现原理。
1.通用网络爬虫
首先我们来看通用网络爬虫的实现原理。通用网络爬虫的实现原理及过程可以简要概括如下(见图3-1)。
1)获取初始的URL。初始的URL地址可以由用户人为地指定,也可以由用户指定的某个或某几个初始爬取网页决定。
2)根据初始的URL爬取页面并获得新的URL。获得初始的URL地址之后,首先需要爬取对应URL地址中的网页,爬取了对应的URL地址中的网页后,将网页存储到原始数据库中,并且在爬取网页的同时,发现新的URL地址,同时将已爬取的URL地址存放到一个URL列表中,用于去重及判断爬取的进程。
3)将新的URL放到URL队列中。在第2步中,获取了下一个新的URL地址之后,会将新的URL地址放到URL队列中。
4)从URL队列中读取新的URL,并依据新的URL爬取网页,同时从新网页中获取新URL,并重复上述的爬取过程。
5)满足爬虫系统设置的停止条件时,停止爬取。在编写爬虫的时候,一般会设置相应的停止条件。如果没有设置停止条件,爬虫则会一直爬取下去,一直到无法获取新的URL地址为止,若设置了停止条件,爬虫则会在停止条件满足时停止爬取。

以上就是通用网络爬虫的实现过程与基本原理,接下来,我们为大家分析聚焦网络爬虫的基本原理及其实现过程。
2.聚焦网络爬虫
聚焦网络爬虫,由于其需要有目的地进行爬取,所以对于通用网络爬虫来说,必须要增加目标的定义和过滤机制,具体来说,此时,其执行原理和过程需要比通用网络爬虫多出三步,即目标的定义、无关链接的过滤、下一步要爬取的URL地址的选取等,如图3-2所示。
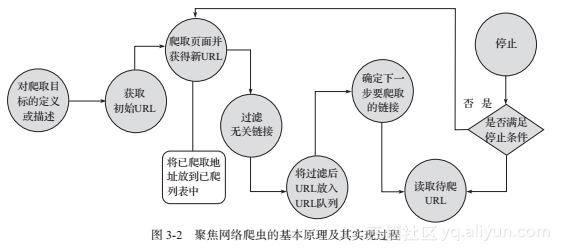
1)对爬取目标的定义和描述。在聚焦网络爬虫中,我们首先要依据爬取需求定义好该聚焦网络爬虫爬取的目标,以及进行相关的描述。
2)获取初始的URL。
3)根据初始的URL爬取页面,并获得新的URL。
4)从新的URL中过滤掉与爬取目标无关的链接。因为聚焦网络爬虫对网页的爬取是有目的性的,所以与目标无关的网页将会被过滤掉。同时,也需要将已爬取的URL地址存放到一个URL列表中,用于去重和判断爬取的进程。
5)将过滤后的链接放到URL队列中。
6)从URL队列中,根据搜索算法,确定URL的优先级,并确定下一步要爬取的URL地址。在通用网络爬虫中,下一步爬取哪些URL地址,是不太重要的,但是在聚焦网络爬虫中,由于其具有目的性,故而下一步爬取哪些URL地址相对来说是比较重要的。对于聚焦网络爬虫来说,不同的爬取顺序,可能导致爬虫的执行效率不同,所以,我们需要依据搜索策略来确定下一步需要爬取哪些URL地址。
7)从下一步要爬取的URL地址中,读取新的URL,然后依据新的URL地址爬取网页,并重复上述爬取过程。
8)满足系统中设置的停止条件时,或无法获取新的URL地址时,停止爬行。
现在我们初步掌握了网络爬虫的实现原理以及相应的工作流程,下面来了解网络爬虫的爬行策略。
