本节书摘来自华章出版社《精通Python网络爬虫:核心技术、框架与项目实战》一书中的第2章,第2.1节,作者 韦 玮,更多章节内容可以访问云栖社区“华章计算机”公众号查看。
第2章
网络爬虫技能总览
在上一章中,我们已经初步认识了网络爬虫,那么网络爬虫具体能做些什么呢?用网络爬虫又能做哪些有趣的事呢?在本章中我们将为大家具体讲解。
2.1 网络爬虫技能总览图
如图2-1所示,我们总结了网络爬虫的常用功能。
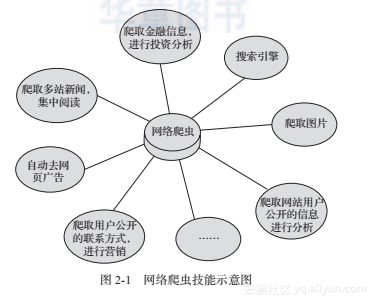
在图2-1中可以看到,网络爬虫可以代替手工做很多事情,比如可以用于做搜索引擎,也可以爬取网站上面的图片,比如有些朋友将某些网站上的图片全部爬取下来,集中进行浏览,同时,网络爬虫也可以用于金融投资领域,比如可以自动爬取一些金融信息,并进行投资分析等。
有时,我们比较喜欢的新闻网站可能有几个,每次都要分别打开这些新闻网站进行浏览,比较麻烦。此时可以利用网络爬虫,将这多个新闻网站中的新闻信息爬取下来,集中进行阅读。
有时,我们在浏览网页上的信息的时候,会发现有很多广告。此时同样可以利用爬虫将对应网页上的信息爬取过来,这样就可以自动的过滤掉这些广告,方便对信息的阅读与使用。
有时,我们需要进行营销,那么如何找到目标客户以及目标客户的联系方式是一个关键问题。我们可以手动地在互联网中寻找,但是这样的效率会很低。此时,我们利用爬虫,可以设置对应的规则,自动地从互联网中采集目标用户的联系方式等数据,供我们进行营销使用。
有时,我们想对某个网站的用户信息进行分析,比如分析该网站的用户活跃度、发言数、热门文章等信息,如果我们不是网站管理员,手工统计将是一个非常庞大的工程。此时,可以利用爬虫轻松将这些数据采集到,以便进行进一步分析,而这一切爬取的操作,都是自动进行的,我们只需要编写好对应的爬虫,并设计好对应的规则即可。
除此之外,爬虫还可以实现很多强大的功能。总之,爬虫的出现,可以在一定程度上代替手工访问网页,从而,原先我们需要人工去访问互联网信息的操作,现在都可以用爬虫自动化实现,这样可以更高效率地利用好互联网中的有效信息。


