本节书摘来自华章出版社《ANTLR 4权威指南 》一书中的第3章,第3.2节,[美] 特恩斯·帕尔(Terence Parr) 著张 博 译,更多章节内容可以访问云栖社区“华章计算机”公众号查看。
3.2 测试生成的语法分析器
对语法运行ANTLR之后,我们需要编译自动生成的Java源代码。简单起见,我们在工作目录/tmp/array下完成所有的编译操作。
如果编译器产生了一个ClassNotFoundException异常,说明你可能没有正确设置Java的CLASSPATH环境变量。在类UNIX系统上,你需要执行以下命令(也可以写在类似.bash_profile的启动脚本中):
我们使用第1章提到的grun别名来启动TestRig,执行对语法的测试。下面的命令告诉我们如何将词法分析器生成的词法符号打印出来。
在输入要测试的语句{99, 3, 451}之后,我们必须手动输入一个EOF。默认情况下,ANTLR在开始处理前会加载全部的输入文本(这是最常见的情况,也是最有效率的处理方式)。
每行输出代表一个词法符号,其中包含该词法符号的全部信息。例如,[@5, 8:10 = '451', <4>, 1:8]表明它是第5个词法符号(从0开始计数),由第8到第10个字符组成(从0开始计数,包含第8和第10),包含的文本是451,类型是4(INT),位于输入文本的第1行(从1开始计数)第8个字符(从0开始计数,tab作为一个字符)处。注意,输出的结果中不包含空格和换行符,这是因为在我们的语法中,WS规则的“->skip”指令将它们丢弃了。
如果需要语法分析器关于输入文本识别过程的更多信息,我们可以使用“-tree”选项查看语法分析树:
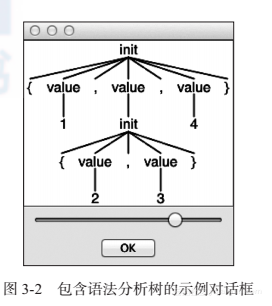
“-tree”选项使用LISP风格(根节点和子节点在同一行显示)打印出语法分析树。另外,我们也可以使用“-gui”选项生成一个可视化的对话框。我们试着用这个选项处理一下{1, {2, 3}, 4}这样的嵌套结构。
图3-2就是弹出的包含语法分析树的对话框。
用自然语言表述,语法分析树就是,“输入的是一个由一对花括号包裹的三个值组成的初始化语句,第一个和第三个值是整数1和4,第二个值也是一个初始化语句,它由一对花括号包裹的两个值组成,这两个值是整数2和3”。
这些内部节点,即init节点和value节点,非常通俗易懂,因为它们用名字标识出了复杂的输入元素。这有点像是标识英语句子中的动词和主语。ANTLR最棒的部分在于,它能够基于我们的语法中的规则名自动创建这样的一棵语法分析树。在本章的最后,我们会使用ANTLR内置的语法分析树遍历器触发自定义的回调函数enterInit()和enterValue(),从而构建出一个满足要求的翻译器。
现在我们已经能用ANTLR分析语法、生成代码,并且测试它们了,接下来我们要思考的是,如何从另外一个Java程序中调用生成的语法分析器。

