本节书摘来自华章出版社《深入浅出DPDK》一书中的第3章,第3.1节并行计算,作者朱河清,梁存铭,胡雪焜,曹水 等,更多章节内容可以访问云栖社区“华章计算机”公众号查看。
第3章 并 行 计 算
处理器性能提升主要有两个途径,一个是提高IPC(每个时钟周期内可以执行的指令条数),另一个是提高处理器主频率。每一代微架构的调整可以伴随着对IPC的提高,从而提高处理器性能,只是幅度有限。而提高处理器主频率对于性能的提升作用是明显而直接的。但一味地提高频率很快会触及频率墙,因为处理器的功耗正比于主频的三次方。
所以,最终要取得性能提升的进一步突破,还是要回到提高IPC这个因素。经过处理器厂商的不懈努力,我们发现可以通过提高指令执行的并行度来提高IPC。而提高并行度主要有两种方法,一种是提高微架构的指令并行度,另一种是采用多核并发。这一章主要就分享这两种方法在DPDK中的实践,并在指令并行方法中上进一步引入数据并发的介绍。
3.1 多核性能和可扩展性
3.1.1 追求性能水平扩展
多核处理器是指在一个处理器中集成两个或者多个完整的内核(及计算引擎)。如果把处理器性能随着频率的提升看做是垂直扩展,那多核处理器的出现使性能水平扩展成为可能。原本在单核上顺序执行的任务,得以按逻辑划分成若干子任务,分别在不同的核上并行执行。在任务粒度上,使指令执行的并行度得到提升。
那随着核数的增加,性能是否能持续提升呢?Amdahl定律告诉我们,假设一个任务的工作量不变,多核并行计算理论时延加速上限取决于那些不能并行处理部分的比例。换句话说,多核并行计算下时延不能随着核数增加而趋于无限小。该定律明确告诉我们,利用多核处理器提升固定工作量性能的关键在于降低那些不得不串行部分占整个任务执行的比例。更多信息可以参考[Ref3-1]。
对于DPDK的主要应用领域——数据包处理,多数场景并不是完成一个固定工作量的任务,更主要关注单位时间内的吞吐量。Gustafson定律对于在固定工作时间下的推导给予我们更多的指导意义。它指出,多核并行计算的吞吐率随核数增加而线性扩展,可并行处理部分占整个任务比重越高,则增长的斜率越大。带着这个观点来读DPDK,很多实现的初衷就豁然开朗。资源局部化、避免跨核共享、减少临界区碰撞、加快临界区完成速率(后两者涉及多核同步控制,将在下一章中介绍)等,都不同程度地降低了不可并行部分和并发干扰部分的占比。
3.1.2 多核处理器
在数据包处理领域,多核架构的处理器已经广泛应用。本节以英特尔的至强主流多核处理器为例,介绍DPDK中用到的一些概念,比如物理核、逻辑核、CPU node等。
下面结合图形详细介绍了单核、多核以及超线程的概念。
通过单核结构(见图3-1),我们先认识一下CPU物理核中主要的基本组件。为简化理解,将主要组件简化为:CPU寄存器集合、中断逻辑(Local APIC)、执行单元和Cache。一个完整的物理核需要拥有这样的整套资源,提供一个指令执行线程。
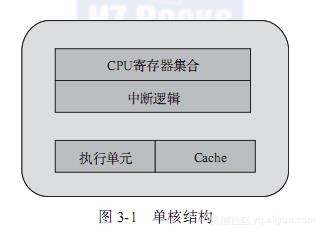
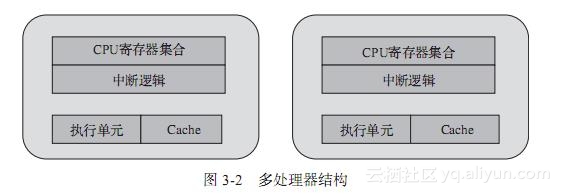
多处理器结构指的是多颗单独封装的CPU通过外部总线连接,构成的统一计算平台,如图3-2所示。每个CPU都需要独立的电路支持,有自己的Cache,而它们之间的通信通过主板上的总线。在此架构上,若一个多线程的程序运行在不同CPU的某个核上,跨CPU的线程间协作都要走总线,而共享的数据还会付出因Cache一致性产生的开销。从内存子系统的角度,多处理器结构进一步衍生出了非一致内存访问(NUMA),这一点在第2章就有介绍。在DPDK中,对于多处理器的NUMA结构,使用Socket Node来标示,跨NUMA的内存访问是性能调优时最需要避免的。
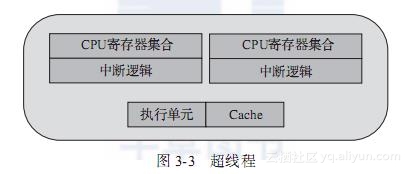
如图3-3所示,超线程(Hyper-Threading)在一个处理器中提供两个逻辑执行线程,逻辑线程共享流水线、执行单元和缓存。该技术的本质是复用单处理器中的超标量流水线的多路执行单元,降低多路执行单元中因指令依赖造成的执行单元闲置。对于每个逻辑线程,拥有完整独立的寄存器集合和本地中断逻辑,从软件的角度,与单线程物理核并没有差异。例如,8核心的处理器使用超线程技术之后,可以得到16个逻辑线程。采用超线程,在单核上可以同时进行多线程处理,使整体性能得到一定程度提升。但由于其毕竟是共享执行单元的,对IPC(每周期执行指令数)越高的应用,带来的帮助越有限。DPDK是一种I/O集中的负载,对于这类负载,IPC相对不是特别高,所以超线程技术会有一定程度的帮助。更多信息可以参考[Ref3-2]。
如果说超线程还是站在一个核内部以资源切分的方式构成多个执行线程,多核体系结构(见图3-4)则是在一个CPU封装里放入了多个对等的物理核,每个物理核可以独立构成一个执行线程,当然也可以进一步分割成多个执行线程(采用超线程技术)。多核之间的通信使用芯片内部总线来完成,共享更低一级缓存(LLC,三级缓存)和内存。随着CPU制造工艺的提升,每个CPU封装中放入的物理核数也在不断提高。
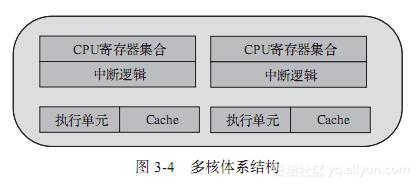
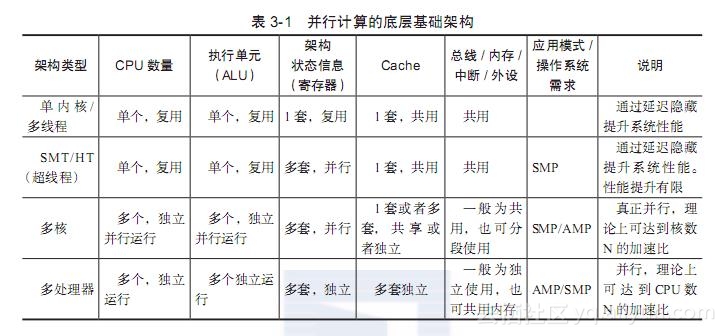
各种架构在总线占用、Cache、寄存器以及执行单元的区别大致可以归纳为表3-1。
一个物理封装的CPU(通过physical id区分判断)可以有多个核(通过core id区分判断)。而每个核可以有多个逻辑CPU(通过processor区分判断)。一个核通过多个逻辑CPU实现这个核自己的超线程技术。
查看CPU内核信息的基本命令如表3-2所示。

处理器核数:processor cores,即俗称的“CPU核数”,也就是每个物理CPU中core的个数,例如“Intel(R) Xeon(R) CPU E5-2680 v2 @ 2.80GHz”是10核处理器,它在每个socket上有10个“处理器核”。具有相同core id的CPU是同一个core的超线程。
逻辑处理器核心数:sibling是内核认为的单个物理处理器所有的超线程个数,也就是一个物理封装中的逻辑核的个数。如果sibling等于实际物理核数的话,就说明没有启动超线程;反之,则说明启用超线程。
系统物理处理器封装ID:Socket中文翻译成“插槽”,也就是所谓的物理处理器封装个数,即俗称的“物理CPU数”,管理员可能会称之为“路”。例如一块“Intel(R) Xeon(R) CPU E5-2680 v2 @ 2.80GHz”有两个“物理处理器封装”。具有相同physical id的CPU是同一个CPU封装的线程或核心。
系统逻辑处理器ID:逻辑处理器数的英文名是logical processor,即俗称的“逻辑CPU数”,逻辑核心处理器就是虚拟物理核心处理器的一个超线程技术,例如“Intel(R) Xeon(R) CPU E5-2680 v2 @ 2.80GHz”支持超线程,一个物理核心能模拟为两个逻辑处理器,即一块“Intel(R) Xeon(R) CPU E5-2680 v2 @ 2.80GHz”有20个“逻辑处理器”。
3.1.3 亲和性
当处理器进入多核架构后,自然会面对一个问题,按照什么策略将任务线程分配到各个处理器上执行。众所周知的是,这个分配工作一般由操作系统完成。负载均衡当然是比较理想的策略,按需指定的方式也是很自然的诉求,因为其具有确定性。
简单地说,CPU亲和性(Core affinity)就是一个特定的任务要在某个给定的CPU上尽量长时间地运行而不被迁移到其他处理器上的倾向性。这意味着线程可以不在处理器之间频繁迁移。这种状态正是我们所希望的,因为线程迁移的频率小就意味着产生的负载小。
Linux内核包含了一种机制,它让开发人员可以编程实现CPU亲和性。这意味着应用程序可以显式地指定线程在哪个(或哪些)处理器上运行。
1.Linux内核对亲和性的支持
在Linux内核中,所有的线程都有一个相关的数据结构,称为task_struct。这个结构非常重要,原因有很多;其中与亲和性相关度最高的是cpus_allowed位掩码。这个位掩码由n位组成,与系统中的n个逻辑处理器一一对应。具有4个物理CPU的系统可以有4位。如果这些CPU都启用了超线程,那么这个系统就有一个8位的位掩码。
如果针对某个线程设置了指定的位,那么这个线程就可以在相关的CPU上运行。因此,如果一个线程可以在任何CPU上运行,并且能够根据需要在处理器之间进行迁移,那么位掩码就全是1。实际上,在Linux中,这就是线程的默认状态。
Linux内核API提供了一些方法,让用户可以修改位掩码或查看当前的位掩码:
- sched_set_affinity()(用来修改位掩码)
- (sched_get_affinity(用来查看当前的位掩码)
注意,cpu_affinity会被传递给子线程,因此应该适当地调用sched_set_affinity。
2.为什么应该使用亲和性
将线程与CPU绑定,最直观的好处就是提高了CPU Cache的命中率,从而减少内存访问损耗,提高程序的速度。
在多核体系CPU上,提高外设以及程序工作效率最直观的办法就是让各个物理核各自负责专门的事情。每个物理核各自也会有缓存,缓存着执行线程使用的信息,而线程可能会被内核调度到其他物理核上,这样L1/L2的Cache命中率会降低,当绑定物理核后,程序就会一直在指定核上跑,不会由操作系统调度到其他核上,省却了来回反复调度的性能消耗,线程之间互不干扰地完成工作。
在NUMA架构下,这个操作对系统运行速度的提升有更大的意义,跨NUMA节点的任务切换,将导致大量三级Cache的丢失。从这个角度来看,NUMA使用CPU绑定时,每个核心可以更专注地处理一件事情,资源体系被充分使用,减少了同步的损耗。
通常Linux内核都可以很好地对线程进行调度,在应该运行的地方运行线程(这就是说,在可用的处理器上运行并获得很好的整体性能)。内核包含了一些用来检测CPU之间任务负载迁移的算法,可以启用线程迁移来降低繁忙的处理器的压力。
一般情况下,在应用程序中只需使用默认的调度器行为。然而,您可能会希望修改这些默认行为以实现性能的优化。让我们来看一下使用亲和性的三个原因。
- 有大量计算要做
基于大量计算的情形通常出现在科学计算和理论计算中,但是通用领域的计算也可能出现这种情况。一个常见的标志是发现自己的应用程序要在多处理器的机器上花费大量的计算时间。
- 测试复杂的应用程序
测试复杂软件是我们对内核亲和性技术感兴趣的另外一个原因。考虑一个需要进行线性可伸缩性测试的应用程序。有些产品声明可以在使用更多硬件时执行得更好。我们不用购买多台机器(为每种处理器配置都购买一台机器),而是可以:①购买一台多处理器的机器,②不断增加分配的处理器,③测量每秒的事务数,④评估结果的可伸缩性。
如果应用程序随着CPU的增加可以线性地伸缩,那么每秒事务数和CPU个数之间应该会是线性的关系。这样建模可以确定应用程序是否可以有效地使用底层硬件。
如果一个给定的线程迁移到其他地方去了,那么它就失去了利用CPU缓存的优势。实际上,如果正在使用的CPU需要为自己缓存一些特殊的数据,那么所有其他CPU都会使这些数据在自己的缓存中失效。
因此,如果有多个线程都需要相同的数据,那么将这些线程绑定到一个特定的CPU上是非常有意义的,这样就确保它们可以访问相同的缓存数据(或者至少可以提高缓存的命中率)。
否则,这些线程可能会在不同的CPU上执行,这样会频繁地使其他缓存项失效。
- 运行时间敏感的、决定性的线程
我们对CPU亲和性感兴趣的最后一个原因是实时(对时间敏感的)线程。例如,您可能会希望使用亲和性来指定一个8路主机上的某个处理器,而同时允许其他7个处理器处理所有普通的系统调度。这种做法确保长时间运行、对时间敏感的应用程序可以得到运行,同时可以允许其他应用程序独占其余的计算资源。下面的应用程序显示了这是如何工作的。
3.线程独占
DPDK通过把线程绑定到逻辑核的方法来避免跨核任务中的切换开销,但对于绑定运行的当前逻辑核,仍然可能会有线程切换的发生,若希望进一步减少其他任务对于某个特定任务的影响,在亲和的基础上更进一步,可以采取把逻辑核从内核调度系统剥离的方法。
Linux内核提供了启动参数isolcpus。对于有4个CPU的服务器,在启动的时候加入启动参数isolcpus=2,3。那么系统启动后将不使用CPU3和CPU4。注意,这里说的不使用不是绝对地不使用,系统启动后仍然可以通过taskset命令指定哪些程序在这些核心中运行。步骤如下所示。
命令:vim /boot/grub2.cfg
在Linux kernel启动参数里面加入isolcpus参数,isolcpu=2,3。
命令:cat /proc/cmdline
等待系统重新启动之后查看启动参数BOOT_IMAGE=/boot/vmlinuz-3.17.8-200.fc20.x86_64 root=UUID=3ae47813-79ea-4805-a732-21bedcbdb0b5 ro LANG=en_US.UTF-8 isolcpus=2,3。
3.1.4 DPDK的多线程
DPDK的线程基于pthread接口创建,属于抢占式线程模型,受内核调度支配。DPDK通过在多核设备上创建多个线程,每个线程绑定到单独的核上,减少线程调度的开销,以提高性能。
DPDK的线程可以作为控制线程,也可以作为数据线程。在DPDK的一些示例中,控制线程一般绑定到MASTER核上,接受用户配置,并传递配置参数给数据线程等;数据线程分布在不同核上处理数据包。
1.?EAL中的lcore
DPDK的lcore指的是EAL线程,本质是基于pthread(Linux/FreeBSD)封装实现。Lcore(EAL pthread)由remote_launch函数指定的任务创建并管理。在每个EAL pthread中,有一个TLS(Thread Local Storage)称为_lcore_id。当使用DPDK的EAL‘-c’参数指定coremask时,EAL pthread生成相应个数lcore并默认是1:1亲和到coremask对应的CPU逻辑核,_lcore_id和CPU ID是一致的。
下面简单介绍DPDK中lcore的初始化及执行任务的注册。
(1)初始化
1)rte_eal_cpu_init()函数中,通过读取/sys/devices/system/cpu/cpuX/下的相关信息,确定当前系统有哪些CPU核,以及每个核属于哪个CPU Socket。
2)eal_parse_args()函数,解析-c参数,确认哪些CPU核是可以使用的,以及设置第一个核为MASTER。
3)为每一个SLAVE核创建线程,并调用eal_thread_set_affinity()绑定CPU。线程的执行体是eal_thread_loop()。eal_thread_loop()的主体是一个while死循环,调用不同模块注册到lcore_config[lcore_id].f的回调函数。
RTE_LCORE_FOREACH_SLAVE(i) {
/*
* create communication pipes between master thread
* and children
*/
if (pipe(lcore_config[i].pipe_master2slave) < 0)
rte_panic("Cannot create pipe\n");
if (pipe(lcore_config[i].pipe_slave2master) < 0)
rte_panic("Cannot create pipe\n");
lcore_config[i].state = WAIT;
/* create a thread for each lcore */
ret = pthread_create(&lcore_config[i].thread_id, NULL,
eal_thread_loop, NULL);
if (ret != 0)
rte_panic("Cannot create thread\n");
}
(2)注册
不同的模块需要调用rte_eal_mp_remote_launch(),将自己的回调处理函数注册到lcore_config[].f中。以l2fwd为例,注册的回调处理函数是l2fwd_launch_on_lcore()。
rte_eal_mp_remote_launch(l2fwd_launch_one_lcore, NULL, CALL_MASTER);
DPDK每个核上的线程最终会调用eal_thread_loop()--->l2fwd_launch_on_lcore(),调用到自己实现的处理函数。
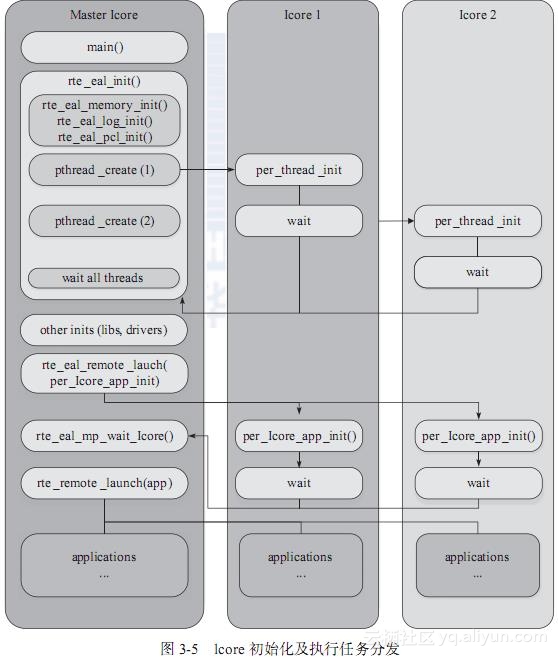
最后,总结整个lcore启动过程和执行任务分发,可以归纳为如图3-5所示。
2.?lcore的亲和性
默认情况下,lcore是与逻辑核一一亲和绑定的。带来性能提升的同时,也牺牲了一定的灵活性和能效。在现网中,往往有流量潮汐现象的发生,在网络流量空闲时,没有必要使用与流量繁忙时相同的核数。按需分配和灵活的扩展伸缩能力,代表了一种很有说服力的能效需求。于是,EAL pthread和逻辑核之间进而允许打破1:1的绑定关系,使得_lcore_id本身和CPU ID可以不严格一致。EAL定义了长选项“--lcores”来指定lcore的CPU亲和性。对一个特定的lcore ID或者lcore ID组,这个长选项允许为EAL pthread设置CPU集。
格式如下:
--lcores=’@cpu_set,...]’
其中,‘lcore_set’和‘cpu_set’可以是一个数字、范围或者一个组。数字值是“digit([0-9]+)”;范围是“-”;group是“([,,...])”。如果不指定‘@cpu_set’的值,那么默认就使用‘lcore_set’的值。这个选项与corelist的选项‘-l’是兼容的。
For example, "--lcores='1,2@(5-7),(3-5)@(0,2),(0,6),7-8'" which means start 9 EAL thread;
lcore 0 runs on cpuset 0x41 (cpu 0,6);
lcore 1 runs on cpuset 0x2 (cpu 1);
lcore 2 runs on cpuset 0xe0 (cpu 5,6,7);
lcore 3,4,5 runs on cpuset 0x5 (cpu 0,2);
lcore 6 runs on cpuset 0x41 (cpu 0,6);
lcore 7 runs on cpuset 0x80 (cpu 7);
lcore 8 runs on cpuset 0x100 (cpu 8).
这个选项以及对应的一组API(rte_thread_set/get_affinity())为lcore提供了亲和的灵活性。lcore可以亲和到一个CPU或者一个CPU集合,使得在运行时调整具体某个CPU承载lcore成为可能。
而另一个方面,多个lcore也可能亲和到同一个核。这里要注意的是,同一个核上多个可抢占式的任务调度涉及非抢占式的库时,会有一定限制。这里以非抢占式无锁rte_ring为例:
1)单生产者/单消费者模式,不受影响,可正常使用。
2)多生产者/多消费者模式且pthread调度策略都是SCHED_OTHER时,可以使用,性能会有所影响。
3)多生产者/多消费者模式且pthread调度策略有SCHED_FIFO或者SCHED_RR时,建议不使用,会产生死锁。
3.?对用户pthread的支持
除了使用DPDK提供的逻辑核之外,用户也可以将DPDK的执行上下文运行在任何用户自己创建的pthread中。在普通用户自定义的pthread中,lcore id的值总是LCORE_ID_ANY,以此确定这个thread是一个有效的普通用户所创建的pthread。用户创建的pthread可以支持绝大多数DPDK库,没有任何影响。但少数DPDK库可能无法完全支持用户自创建的pthread,如timer和Mempool。以Mempool为例,在用户自创建的pthread中,将不会启用每个核的缓存队列(Mempool cache),这个会对最佳性能造成一定影响。更多影响可以参见开发者手册的多线程章节。
4.?有效地管理计算资源
我们知道,如果网络吞吐很大,超过一个核的处理能力,可以加入更多的核来均衡流量提高整体计算能力。但是,如果网络吞吐比较小,不能耗尽哪怕是一个核的计算能力,如何能够释放计算资源给其他任务呢?
通过前面的介绍,我们了解到了DPDK的线程其实就是普通的pthread。使用cgroup能把CPU的配额灵活地配置在不同的线程上。cgroup是control group的缩写,是Linux内核提供的一种可以限制、记录、隔离进程组所使用的物理资源(如:CPU、内存、I/O等)的机制。DPDK可以借助cgroup实现计算资源配额对于线程的灵活配置,可以有效改善I/O核的闲置利用率。