本节书摘来自华章出版社《多核与GPU编程:工具、方法及实践》一书中的第3章,第3.8节, 作 者 Multicore and GPU Programming: An Integrated Approach[阿联酋]杰拉西莫斯·巴拉斯(Gerassimos Barlas) 著,张云泉 贾海鹏 李士刚 袁良 等译, 更多章节内容可以访问云栖社区“华章计算机”公众号查看。
3.8 动态线程管理与静态线程管理
3.2.3.1节介绍过,Qt管理一组就绪的线程池,不需要操作系统来分配和初始化新线程实体。尽管创建线程的开销较之创建进程的开销要小几个量级,但它仍然是较为耗时的,特别是当线程需要在运行时动态生成时。一个经典的粒子是监听请求和分配线程进行服务的并发Web或者数据库服务器。在这种情况下线程可以从一个空闲线程库中选取并重用,而不是为每一个请求创建一个新的线程。QThreadPool类提供的功能正是这种线程库。
本节将要介绍如何利用QThreadPool,以及如何创建线程库,即使线程库并不是嵌入式的。
3.8.1 Qt线程池
QThreadPool类和QtConcurrent命名空间函数提供给了高效、简单地扩展到多线程应用程序的方法(即使线程并不需要共享资源)。唯一的问题是只有当存在一个可用线程时,由独立线程运行的函数才会执行。
代码清单3-25是代码清单3-10生产者和消费者代码的重写版本,用于说明如何利用这些功能。


从代码清单3-25的长度可以看到,为了引入这些新的功能,只改变了很少的部分。QtConcurrent::run函数也能工作于一个对象的方法上,前提是提供这个对象的引用,以及待调用方法的地址。由于线程是匿名的,因此主线程必须使用QtConcurrent::run的QFuture对象来等待其完成(第22行和第25行)。
第13行和第18行使用的对象引用(p[i]和c[i])意味着调用的方法是常量,亦即它们不改变对象。如果不使用常量方法,对象指针可能按如下方式使用。

关于第13行和第18行中语法的最后一个说明是,在没有类实例的情况下,需要使用地址操作符,否则非静态函数将不能被引用。
第3行和第4行保证了所有请求的线程都将会开始执行,即使根据Qt的标准这一数目是次优的。理想的线程数目是通过QThread::idealThreadCount()方法来估计和设置的,这是设置动态线程数的默认方法。通过QThreadPool::globalInstance()静态方法获得一个内部QThreadPool实例,可用的线程数目可以修改(第4行)。
3.8.2 线程池的创建和管理
需要频繁生成线程的应用可以通过重用线程来提高性能,亦即使用相同的线程处理不同的任务。这一提高来自内存管理子系统需求的减少,这是由于操作系统不需要分配和初始化线程执行所需要的所有组件(运行时栈、线程控制块等)。
为满足该目的创建的线程池需要能够满足以下条件。
1.描述计算任务。
2.计算任务间通信。
3.标识一个执行任务的线程。
4.通知任务执行的终止。
Qt中初始化线程的方法是依照满足上述几个条件的原则来设计的:把一个计算任务描述为通过一个供线程执行的单一入口点的类来实现。可以通过定义一个抽象的类来建定接口的类型。
在一个或多个任务生成(生产)线程与执行(消费)它们的线程池间,ComputationalTask的具体派生类的通信实例是生产者–消费者模式一个典型的示例。这一问题可以利用3.5.2节计算数值积分中使用的方式来解决,核心的区别是这里的目标是执行任意的任务,而不仅仅是单一类型的任务。
第三个和第四个需求可以通过唯一地标识任务(例如通过任务ID)并且强制线程使用相关联的标识符指示执行状态(即终止)来实现。基于前面的讨论,可以给出一个抽象类,作为提交给线程池的任意任务的基础类,代码清单图3-26所示。

taskID数据成员用于唯一地标识一个任务,不管它由哪一个线程执行。这看上去与上一节用到的设置(即主线程存储子线程的引用这一方式)相矛盾。
由于真正关心的是提交的任务,因此对一个线程池的引用对于主线程而言没有意义。在任意时刻一个线程池线程可以执行任意任务(或者变为空闲)。
下面的代码清单展示了一个基于monitor的自定义线程池类以及其对应的线程类。为了更为清晰地展示,每个代码清单展示了单个类的代码。实际的代码分为两个文件:一个头文件和一个实现文件。


CustomThread类是代码的基础架构,包含对CustomThreadPool单例对象的类级引用。每个类的实例获得一个新的任务(第13~18行),并执行它(第16行),标记其完成状态(第17行)。CustomThread实例一直执行直到获得的返回值是一个空任务的引用,这用来表示程序的终止。
代码清单3-28中展示的CustomThreadPool类是一个monitor,它提供两组方法:一组供任务生产者使用,另一组供线程池线程使用。除了构造函数和析构函数之外,所有的公共线程都开始于对象的加锁。因此,一组等待条件保证了任务生产者线程将会在任务缓冲区已满时阻塞,或者线程池线程在任务缓冲区为空时阻塞。


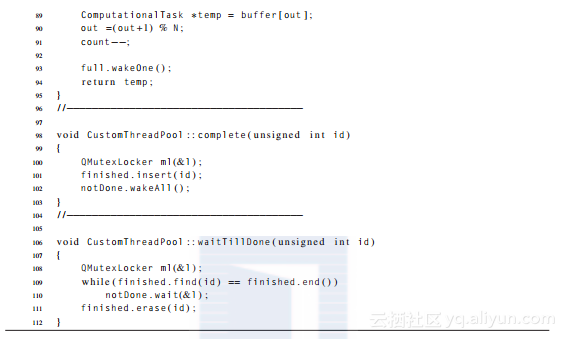
代码清单3-28 定制的线程池类
一旦CustomThreadPool的实例被创建,创建一组CustomThread对象,相联的线程(第40~44行)也会被生成。线程数量默认为16,但是实际的数目可以在类的构造函数中指定。这些线程的引用存储在t数组中,于是CustomThreadPool的析构函数可以阻塞,直到完成所有提交的任务(第53~55行)。
CustomThreadPool对象维护一个循环队列,保存所有ComputationalTask对象。队列通过下面的方法更新。
schedule:在队列中存入一个任务引用。如果引用非空,则该任务被分配一个唯一的ID,该值通过递增静态的nextTaskID变量(第73行和第74行)更新。这一ID也作为句柄返回“生产者”线程。
get:从队列中移除并返回一个任务引用。
这些方法都包含3.7.1节描述的典型的队列操作语句。
一旦一个线程池线程完成了一个任务(亦即compute方法返回),它就通过调用complete方法通知monitor,插入任务ID到一个已完成任务集合中(第101行),并且等待一个提交的任务完成的任意“生产者”线程将被唤醒(第102行)。这个集合只保存已经完成的但是还未被向其生产者报告为完成任务的ID(为了高效率)。任务生成线程可以通过调用waitTillDone方法并传递任务ID作为参数来检查任务是否已经完成。在finished集合(第109行)中的失败查找导致了主调线程的阻塞。
只有当第109行的条件失败时,才表示找到了任务ID,线程会从集合中删除这一ID并返回(第111行)。
作为应用CustomThreadPool类的一个实例,下面的程序生成一组计算Mandelbrot分形集的独立任务。由于加载操作可以被划分并分配到数目固定的线程上,这并不是一个需要动态生成线程的问题的对策,所以这并不是最合适的示例。
Mandelbrot集是复平面上由c=x+iy组成的一个点集,它由一组满足如下递归公式的有界数列z0,z1,z2,…组成:
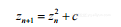
(3-1)
其中,当Ma
著名的ndelbrot分形图形计算如下,对于复平面上的每个点c,计算使得有界数列分叉的迭代次数n,分叉是指|zn|>2。数字n用于对该点伪着色。显然,对于Mandelbrot集,必须对不分叉的点限制迭代次数。
下面的程序将命令行中指定的复平面划分为几个不相交部分,并将其计算分配给不同的任务。每个部分都通过其左上角和右下角来标识。图3-12展示了任务初始化的方法。需要的参数包括:(a)需要计算的复平面子部分的左上角和右下角以及(b)左上角坐标,需要生成的图像的像素高度和宽度。




代码清单3-29展示的程序的关键点如下。
需要处理的复平面的子部分(通过第71~74行中提取的命令行参数指定),划分为Xparts*Yparts个不相交的部分。对于每个部分,都生成一个独立的任务(第107行)并且放置到CustomThreadPool对象队列中(第108行)。
任务为ComputationalTask类的子类,即MandelCompute类的实例。计算主要集中在compute和diverge方法中。
在创建CustomThreadPool单例tp(第87行)后,主线程将生成的任务放置到tp的队列中,并在一个数组中维护返回的任务ID(第108行)。在将生成的图像存储到文件之中前,随后这些ID用来检查任务是否完成(第113~115行)。
一个QImage实例用于处理生成的图像数据,并最终将完整的图像存储到文件中(第118行)。QImage类中的所有方法都是可重入的,亦即可以在多线程中对其进行调用。因为每个线程都被组织为处理QImage对象的不同部分,所以这里不用考虑竞争条件。