本节书摘来自华章出版社《多核与GPU编程:工具、方法及实践》一书中的第2章,第2.3节, 作 者 Multicore and GPU Programming: An Integrated Approach[阿联酋]杰拉西莫斯·巴拉斯(Gerassimos Barlas) 著,张云泉 贾海鹏 李士刚 袁良 等译, 更多章节内容可以访问云栖社区“华章计算机”公众号查看。
2.3 分解模式
设计过程最困难同时也最关键的部分无疑是分解过程,即确定可以并发执行的计算。虽然任务图法是最常用的,但开发者无法从中获取以往的经验,这时就需要模式。Mattson等人[33]列出了若干分解模式(在他们的书中表示为“algorithm structure design space patterns”),
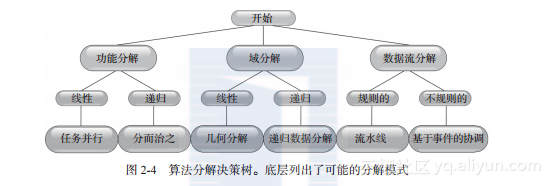
该参考文献包含了工作负载被分解并最终分配到并行或多核平台各个节点上的基本方法。图2-4显示了能得到6个模式之一的决策树。
上一节提到了两类分解,即功能分解和域分解,现在又加入了另一类分解:数据流分解。当应用程序需要处理通过一系列处理阶段的数据流时,适合使用这一类分解。从这种意义上说,可以认为数据流分解是功能分解的扩展。数据可能会遵从一系列特定的步骤,因而需要使用流水线模式;也可能遵从诸如离散事件模拟的不规则模式,因而需要使用事件流分解。
下一个决策步骤需要利用待执行任务的先验知识(或者不需要知识)以找到问题的解法。先验知识暗示了在数据或功能层静态分解任务的能力(线性分解)。与之相对的情况则需要使用运行时分解。
下面的各节将详细描述每一种模式。需要注意的是,不同分解模式没有严格的界限,一个问题通常可以按不同的方式分解,不同的模式可以让读者从不同的观点思考并行问题。
2.3.1 任务并行
许多串行代码都具有模块化的结构以共同解决问题。例如,考虑一个游戏的主循环:

一个简单的并行化方法就是将每个独立的模块分配给不同的计算节点:


barrier同步原语用于确保所有的任务协调一致,在下一次迭代开始前,要保证每个任务都完成了本次迭代。
只要任务间没有复杂的依赖关系,就可以并发执行。然而,这种策略不能随着计算节点数很好地扩展,因为最大节点数不能超过通常很有限的任务数。
2.3.2 分而治之分解
很大一部分的串行算法都可以简洁地用递归来表示,即算法的解法由更小且不相关联的子问题的解法组合来表示。
典型的分而治之算法步骤序列如下所示:

mergeLists函数调用完成实际的排序,但是它之前的代码清单揭示算法如何将输入分解为逐渐减小的块,等排序完再连接在一起。
要强调的是,可用于探索并发潜力的依赖图与函数调用图是不一致的,所以产生该图时要谨慎。图2-5显示了一个对包含8个元素的数组排序的串行程序所产生的函数调用序列。画出这些函数调用的依赖图即可揭示并行性,依赖图如图2-6所示。
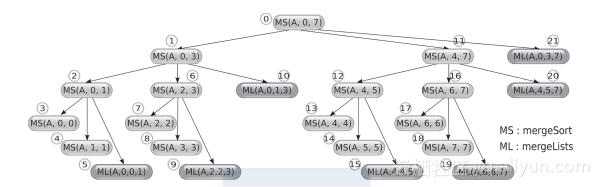
图2-5 串行执行自顶向下mergesoft算法时的函数调用图,该算法对输入的8个元素进行排序。每个节点旁圈出的数字表示调用顺序
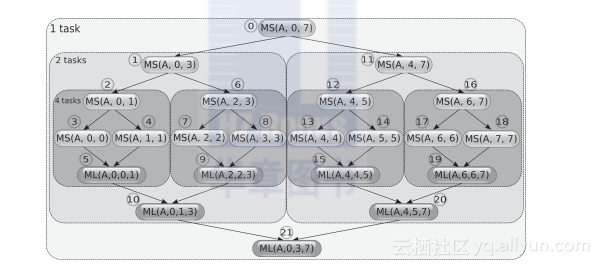
图2-6 自顶向下mergesoft算法产生的函数调用的依赖图,输入为8个元素。每个节点旁圈出的数字表示调用顺序。灰色虚线方框表示可能的任务分配。在本例中,并发的最大层次是4个任务,因为对数组大小为1的mergeSort调用会立即返回,不表示任何工作负载
通常,分而治之模式由运行时动态产生的任务所控制。任务产生会一直执行,直到下降到特定的任务大小,或可并发运行的任务数量达到可用的节点数。这种方法可以总结为如代码清单2-2所示的伪码形式。
代码清单2-2 并行化一般分而治之算法的伪码


在第8~9行的循环中,用非阻塞函数调用产生N个任务,用于解决第7行创建的子问题。只有当需要收集子任务执行的结果时执行才会阻塞(第11~12行)。也可能父任务解决一个子问题,并产生N-1个新任务,而不是空闲。实际的调度或映射任务到可用的计算节点是另一个问题,很大程度上这是要考虑特定平台的,因为它取决于任务迁移和数据通信的开销。因此,这个问题会在后面的章节再核查。
2.3.3 几何分解
许多算法包括在一个数据集上重复的一系列步骤。如果数据是按线性结构组织的,比如数组、二维矩阵或类似的数据结构,那么数据可以沿一维或多维分开,并分配给不同的任务。因此叫做“几何”分解。
如果数据间没有依赖,就得到了一个易并行的问题,因为所有产生的任务都可以并行执行,最大化潜在的加速比。
例如,考虑一个在二维表面模拟热扩散的问题。控制一个等方性且同构的媒介温度变化的等式是:
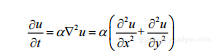
(2-5)
其中,u=u(x, y, t)是温度(作为空间和时间的函数),α是与材料导热率相关的一个常量。
通过将表面划分成大小均为h·h的离散单元格网可以执行模拟。每个单元格的温度可以通过使用式(2-5)中拉普拉斯算子的下列近似在一系列时间步长进行更新。
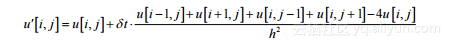
(2-6)
其中,u'[i,j]是在网格位置[i,j]的新温度值,u[i,j]是老温度值,δt 是时间步长。
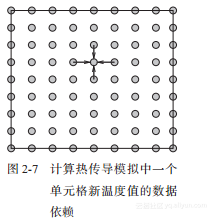
式(2-6)意味着要计算每个时间步长的温度,必须取得四个邻居的值,如图2-7所示。
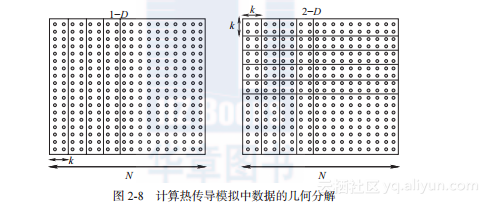
该问题中数据的几何分解可以从一维或二维进行,如图2-8所示,但是哪种更好呢?
只有在考虑了目标执行平台时才能回答这个问题。幸运的是,这并不需要构建并测试该并行程序的多个版本来完成。
假设执行平台是同构的,具有单端口、全双向通信连接,该问题可以由下面的参数描述。
N是每维的单元格数目。
k是沿着分解的维度,每个分组所包含的单元数。
P是计算节点数。
tcomp 表示对一个单元格一次更新的处理开销。
tcomm 表示在两个计算节点间传送每个数据项的通信开销。
tstart 表示通信启动延迟。
如果使用一维分解,一共有P=?N/k?组应该映射到独立的节点。为简单起见,假设N能被k整除。对于每个时间步长,每个节点将用于执行和通信的开销为:
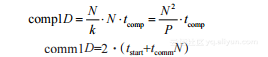
通信时间的计算基于发送和接收总共四组N值的需求。全双向连接可以同时执行发送和接收操作,因此式(2-8)中的常数是2。边界节点是例外(可以被忽略),因为其他节点控制总执行时间。如果只有两个节点,这种例外占统治地位,此时式(2-8)的系数将从2减为1。
若使用二维分解,每个节点处理k2个单元格,P=N2/ k2,每个时间步长需要的执行和通信开销为:
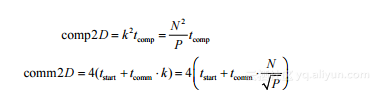
和一维一样,边界节点是例外(可被忽略),除非仅有4个节点。这种情况下,每个节点执行两个并发的接收和发送操作(总共4个),式(2-10)中的系数将降为2。
因此,如果可以使用多于4个节点,一维分解比二维要好,因为根据通信开销的关系可以推导出:

因此,在上文描述的通信结构下,只要通信启动延迟超过式(2-11)的阈值,一维分解就更适合。
值得注意的是,式(2-6)也可以被建模为图像的卷积,像素表示单元格温度,3×3的核为:

2.2节的讨论也适用这种情况,会产生相同结果。
2.3.4 递归数据分解
类似树、链表或图这样的递归数据结构不能使用上一节提到的直接方式进行分割。对于递归数据分解,数据结构被分解为独立的元素,每个元素(或元素组)再被分配到独立的计算节点。
这一过程可能需要修改原始算法,以便并发操作可以执行。操作方式模仿动态规划,即较大问题的解答基于所存储的较小问题的解答。
例如计算一个数组局部和的问题,给定一个N个元素的数组A,计算局部和 。线性复杂度串行算法如代码清单2-3所示。
。线性复杂度串行算法如代码清单2-3所示。

该算法的一个变种是计算逐渐增大的组数的局部和:首先是大小为2的组,然后是大小为4的组,再然后是大小为8的组,以此类推,如代码清单2-4所示。

对一个大小为9的数组,代码清单2-4中的代码追踪如图2-9所示。在结果的计算过程中必须使用两个数组来保存结果值,因为while循环第14行的每次迭代都不可以改变老的S值。
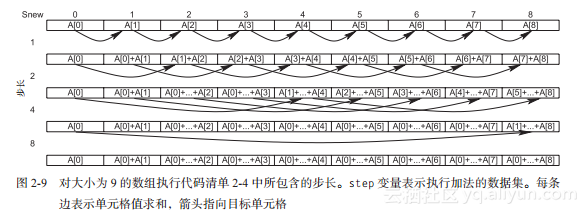
第22~24行的交换代码确保下次计算用到新计算的S值。循环的第一次迭代(step=1)使用数组A而不是Sold,以避免将A拷贝到Sold。
代码清单2-4并没有提升代码清单2-3的时间复杂度。相反,它的时间复杂度为O(NlgN),比N-1有显著增加。然而,它可以并行执行!每次while循环迭代第14行的最大N个步长都可以并行执行。下一次迭代前,所有节点要同步(通过栅栏),以便更新的S数组值可在下次迭代中使用。
如果有N-1个处理器,则可以O(lgN)复杂度运行代码清单2-4的算法,产生可能的加速比:
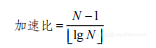
当然,对任何实际问题有如此多的处理器都是不现实的,因此每次迭代都要对P个可用节点中的每一个分配一组更新。并行伪码如代码清单2-5所示。


在代码清单2-5并行循环的第16~23行,由ID表示的计算节点更新元素S[ID+step],S[ID+P+step],S[ID+2*P+step]等的局部和。只要N是2的幂且能被P整除,每个节点就能分配相同的负载。
第24行调用barrier确保只有当全部节点都完成parallel do循环才能进行下一次迭代。
然而,给定并行算法增加的复杂度,并行代码是否能达到大于1的加速比?
代码清单2-5中第14~30行的while循环执行?logN?次。每次迭代中,Snew数组更新的元素总数为N-step,假设在上述代码清单中第20行的开销tc 控制执行时间,N是2的幂,总的执行时间约等于:
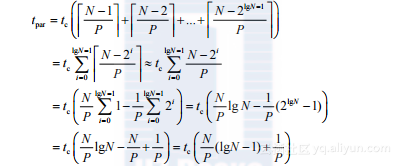
(2-14)
因此加速比大于1需要满足以下条件:
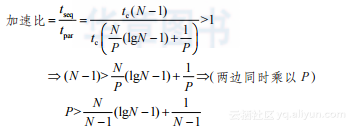
(2-15)
问题规模较大时,上述阈值可近似为lgN – 1,例如,对于220 项数据,节点数应该大于19。
2.3.5 流水线分解
流水线相当于一条装配线的软件或硬件等价。一个条目(item)可以经过由若干阶段组成的流水线,每个阶段对该条目执行特定的操作。
流水线是一个很常用的模式,在许多领域都可以遇到。
CPU体系结构:现代CPU中的机器指令在构成一条流水线的各个阶段执行。这使得许多指令可以并发执行,每个运行在流水线的不同阶段。
信号处理:许多信号处理算法都可以表示为流水线。例如,基于FFT的滤波器可以设计为按顺序执行的三个阶段:FFT变换、FFT系数操作以及逆FFT变换。
图形渲染:当代GPU有图形或渲染流水线,流水线接收3D顶点输入,产生2D光栅图像。流水线阶段包括照明和阴影、裁剪、投影变换和纹理。
Shell编程:nix提供了将一个命令的控制台输出作为另一个命令的控制台输入的功能,因此形成了一条命令流水线。这个看似简单的技术可以使简单的nix命令行工具执行非常复杂的任务。例如,下面的三阶段流水线列出了用户guest使用超级用户权限执行的指令。系统管理员可用这一技术检测黑客攻击:

流水线中的第一阶段过滤出在/var/log/auth.log日志文件中包含sudo的行,下一阶段过滤出第一阶段的输出中包含guest的行。最后,第三阶段分析第二阶段的输出以产生用户guest使用的命令。
流水线阶段执行下列伪码的变种,其中发送和接收操作通常同步且并发以减少CPU空闲时间:

但是将计算安排成一系列相通的离散阶段的好处究竟是什么呢?结果是除非这些阶段(一次作用于不同的数据项)能并发运行,否则没有任何好处。然而,即使可以并发运行,也要确保每个阶段的持续时间非常相近或相同:最慢的(持续时间最长的)阶段决定了流水线的速度。
接着上面的分析,一个简单的例子可以说明流水线的行为。假设有一个五阶段线性流水线,每个阶段将输出发送给下一个阶段后即可获得新的输入。为简化问题,假设通信开销是可忽略的,则四个数据项的处理过程与图2-10的甘特图相似。
从图2-10即可明显看出持续时间最长的阶段(阶段3)决定了流水线处理数据的速度。
一般来说,如果有N个数据项要被一个分M阶段的流水线处理,每个阶段Si 需要ti 时间处理输入,Sl是最慢的阶段,则总执行时间为(见图2-10中突出显示的阶段执行组):
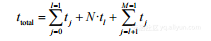
(2-16)
流水线的处理率为(即每个时间单位处理的数据项):
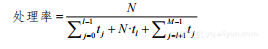
(2-17)
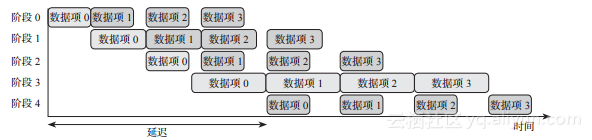
图2-10 阶段延迟不同的五级流水线处理四个数据项集合的甘特图。突出显示的阶段执行顺序决定了总执行时间
流水线延迟定义为直到所有阶段都有要处理的数据所需要的时间:
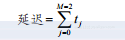
(2-18)
如果所有流水线阶段持续时间相同,每个都是t,则之前的等式可以简化为:
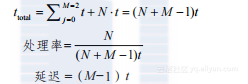
如果N远大于M,则流水线可以达到近乎完美的加速比:
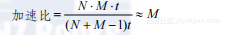
(2-22)
一个线性流水线的例子是流水线排序:对于N个数据项排序,创建N个阶段,每个阶段从前一个阶段读取数据项,和自己当前持有的数据项(如果有的话)进行比较,并将两者者中最大的发给下一个阶段。每个第i阶段(i ∈ [0, N-1])运行N-i-1次迭代。描述每个阶段行为的伪码如代码清单2-6所示。

如果可以并行执行所有的阶段,总执行时间将等于2N-1乘以代码清单2-6的循环体持续时间。因为循环体有常数延迟,所以流水线排序算法的时间复杂性应该为线性的O(N)。然而,有N个阶段是不实际的,一个替代的方法是使用较少的阶段,每个处理一批数据项,而不是仅仅比较两个数据项。
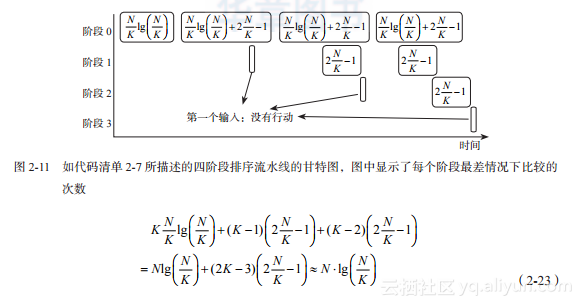
这个构想产生了代码清单2-6的以下改编版本,其中有K个阶段,每个从其前一阶段接收包含 个数据的组,假设N能被K整除,如代码清单2-7所示:
个数据的组,假设N能被K整除,如代码清单2-7所示:

代码清单2-7 处理一批数据的流水线排序算法一个阶段的伪码
第3行和第6行中合并排序算法的时间复杂度为 。第7行合并两个数组,其最差情况复杂度
。第7行合并两个数组,其最差情况复杂度 。所有K个阶段并行执行将产生与图2-11相似的时序,因为第一阶段的持续时间将支配整个过程。总执行时间将与支配它的部分中执行的重要比较次数成正比:
。所有K个阶段并行执行将产生与图2-11相似的时序,因为第一阶段的持续时间将支配整个过程。总执行时间将与支配它的部分中执行的重要比较次数成正比:
图2-11 如代码清单2-7所描述的四阶段排序流水线的甘特图,图中显示了每个阶段最差情况下比较的次数
这个结果并不好,因为加速比的上限为:
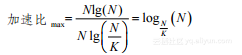
(2-24)
然而,这是一个与流水线最佳实践相违背的例子,流水线应该处理长数据流(远长于流水线长度),并保持每个阶段持续时间相同。
2.3.6 基于事件的合作分解
之前讨论的分解模式有一个共同的隐含特征:通信流是固定的,并且在并行算法的设计及性能评估中可以考虑进来。然而,在一些应用中,并不是这种情况。
可以通过在运行时做出决定以识别出一些动态交互的任务或任务组。这种情况下,通信模式不是固定的,且对任务执行的性能分析(频率、持续时间及空闲时间)也不能预先知道。
这种情况的典型例子是系统的离散事件模拟。离散事件模拟基于系统组件或代理的建模,建模过程是通过产生事件进行交互的对象或软件模型。事件是一条带有时间戳的消息,消息可以表示模型状态的改变、改变状态的触发器、执行动作的请求、对之前产生请求的回复,以及其他类似的消息。